- The paper introduces Seamless Packing, a two-stage strategy that minimizes truncation and padding to enhance contextual coherence and model performance.
- It employs a dynamic sliding window and First-Fit-Decreasing heuristic to optimize data utilization, achieving up to fourfold improvement over baselines.
- Comprehensive experiments across diverse domains, including multilingual settings, confirm the method’s robust generalization and reduced hallucination.
Seamless Data Packing for Enhanced Continual Pre-training
The paper "Improving Continual Pre-training Through Seamless Data Packing" (2505.22018) addresses the critical yet often overlooked aspect of data packing in continual pre-training of LLMs. It posits that conventional data packing methods, which rely on simple concatenation and truncation, can disrupt contextual continuity and introduce inefficiencies due to padding. To mitigate these issues, the authors propose Seamless Packing (SP), a novel two-stage data packing strategy designed to optimize contextual coherence while minimizing truncation and padding. The paper's central claim is that SP enhances model performance and generalization across diverse domains and tasks.
Seamless Packing Methodology
The proposed SP method comprises two sequential stages: Sliding Window and Packing with Dropping (Figure 1).
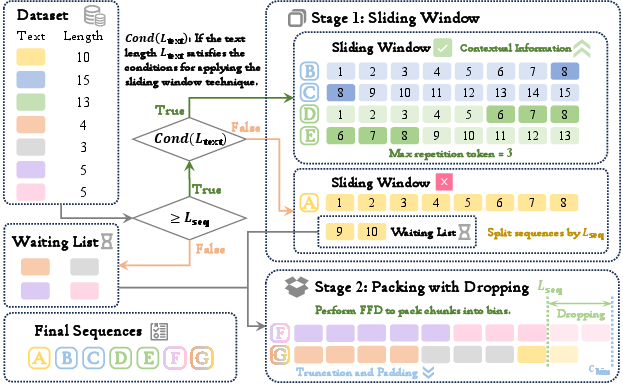
Figure 1: An illustration of the Seamless Packing method.
The first stage, Sliding Window, processes long texts that meet specific length criteria using a dynamic sliding window technique. This technique maximizes contextual continuity by dynamically adjusting the overlap between consecutive sequences based on a predefined maximum repetition ratio (rmax). The condition for applying the sliding window is defined as Loriginal+Lmax_overlap≥(n+1)×Lseq, where Loriginal is the length of the original text, Lmax_overlap is the maximum allowed overlap, n is the number of full sequences, and Lseq is the sequence length. Texts that do not meet this condition are divided into chunks of length Lseq, with incomplete chunks deferred to the second stage. The second stage, Packing with Dropping, addresses the remaining shorter texts using the First-Fit-Decreasing (FFD) algorithm, an approximation heuristic for the NP-hard bin packing problem. The bin capacity is slightly larger than Lseq, controlled by the parameter Cextra, and tokens exceeding Lseq after packing are discarded. This strategy minimizes padding and truncation, ensuring efficient sequence utilization.
Theoretical Analysis of SP
The paper presents a theoretical analysis of the proportion of texts processed by each stage of SP, influenced by rmax. This analysis leverages the observation that text length distributions typically exhibit a decreasing trend as sequence length increases. By combining the conditions for applying the sliding window with the definition of n, the authors derive an expression for the number of texts processed using the sliding window (Nsw):
Nsw=k=1∑⌊rmax1⌋Tk+⌈rmax1⌉T⌈rmax1⌉
where Tk denotes the number of texts with tokenized length within the interval (kLseq,(k+1)Lseq]. The analysis also provides an estimate for the total number of tokens in shorter chunks (Ntoken_short) processed in the second stage:
Ntoken_short=k=1∑⌈rmax1⌉(1−krmax)Tk×4(1−krmax)Lseq
Experimental Evaluation and Results
The efficacy of SP is evaluated through extensive experiments across diverse domains and models, including GPT-2, LLaMA-3, and Qwen2.5. The datasets used for continual pre-training include BBC News, financial news articles, and PubMed articles. The paper compares SP against several baselines, including the original model (OM), concatenation and truncation (CT), and Best-Fit-Decreasing (BFD).
The results demonstrate that SP consistently outperforms conventional data packing methods, achieving superior performance and generalization. Specifically, SP achieves a fourfold improvement over baseline methods (0.96% vs. 0.24%). The experiments encompass various evaluation metrics, including perplexity, full parameter fine-tuning, and LoRA tuning. SP consistently achieves the best results in the majority of cases, demonstrating its robustness across different domains and task types.
Furthermore, the paper presents a generalization analysis, evaluating SP under mixed-domain and general-domain settings. The results confirm that SP generalizes effectively across both domain-specific and general-domain continual pre-training scenarios. The cross-lingual applicability of SP is also examined, with experiments on a French dataset demonstrating its effectiveness in multilingual settings.
Ablation Studies and Hyperparameter Analysis
Ablation studies are conducted to evaluate the contributions of the two key stages in SP and to compare BFD and FFD. The results highlight the effectiveness of the sliding window technique and suggest that slightly increasing bin capacity enhances overall model performance. The paper also analyzes the impact of the hyperparameters rmax and Cextra, finding that a moderate choice of rmax=0.3 achieves a balance between maintaining contextual continuity and preventing excessive redundancy (Figure 2a). Similarly, setting Cextra=50 achieves the best trade-off between preserving essential context and effectively utilizing the additional capacity (Figure 2b).
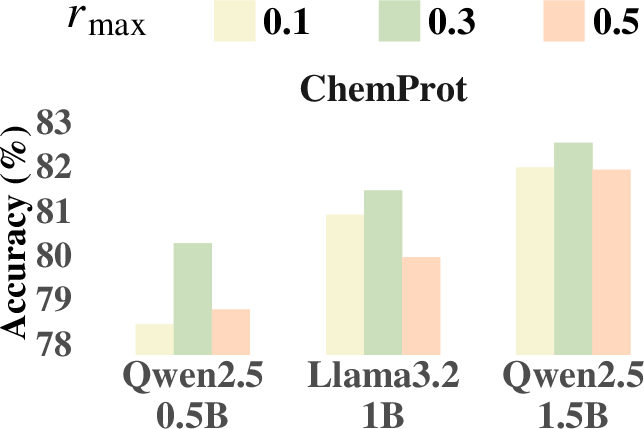
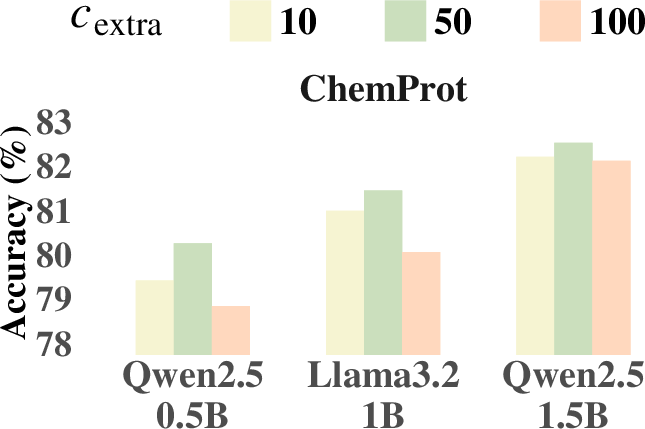
Figure 2: Influence of rmax and Cextra on model performance.
To further demonstrate the importance of contextual continuity, a case study is presented, showcasing that SP effectively reduces hallucination and improves factual consistency in downstream tasks. The paper also includes an empirical analysis of the trade-off between dropping and padding, as well as a computational efficiency comparison of BFD and FFD.
Conclusion
The paper makes a compelling case for the importance of data engineering in continual pre-training. By optimizing both segment placement and overlap strategy, SP preserves contextual continuity while reducing truncation and padding. The empirical results and theoretical analysis provide valuable insights into the design and implementation of data packing strategies for LLMs. The authors acknowledge limitations, including the need for a comprehensive theoretical framework explaining token dropping and padding dynamics, as well as further investigation into the generalizability of SP to other domains and pre-training settings.