- The paper introduces GraNT, a nonparametric teaching paradigm that selects graph examples based on maximum loss gradient discrepancy to accelerate GCN convergence.
- It provides a theoretical connection between gradient descent in GCNs and functional gradient flow using the Graph Neural Tangent Kernel, ensuring pointwise convergence.
- Empirical evaluations show 30–47% reductions in training time across graph-level and node-level tasks, while maintaining or improving generalization performance.
Nonparametric Teaching for Graph Property Learners: An Expert Summary
Overview and Motivation
The paper provides a rigorous theoretical and practical framework for enhancing the efficiency of graph property learning in GCNs via nonparametric machine teaching. The core contribution is the Graph Neural Teaching (GraNT) paradigm, which leverages the emerging theory of nonparametric teaching to optimize the training procedure of GCNs by algorithmically choosing informative subsets of the training data—specifically, those graph-property pairs that maximize convergence speed. The approach is grounded in a detailed analysis of the alignment between parameter-space learning dynamics (via gradient descent in GCNs) and functional-space evolution as formalized in nonparametric teaching. This alignment permits the application of teaching strategies originally formulated for nonparametric models to structure-aware models operating on graph domains.
Theoretical Foundations
At the heart of graph property learning is the inference of an implicit mapping f∗ from a set of graphs to their properties, encompassing both node-level and graph-level tasks. Traditional training of GCNs to approximate f∗ is computationally intensive, especially as graph sizes and datasets scale. The nonparametric teaching paradigm, in contrast to standard passive learning, focuses on the construction of a highly informative teaching set that accelerates the learner’s convergence to the target function.
The paper provides an in-depth mathematical analysis:
- Adjacency-aware Parameter Updates: The authors derive gradient expressions for flexible GCN variants, showing that the structural composition of the graph (encapsulated in the adjacency matrix A and flexible convolutional order aggregation) directly shapes the parameter gradients.
- Functional Perspective: The evolution of the mapping fθ induced by parameter updates is recast as a gradient flow in function space, formally connecting to functional gradient descent. This analysis establishes that the dynamic Graph Neural Tangent Kernel (GNTK), which encodes how GCN changes in response to parameter updates, pointwise converges to the canonical structure-aware kernel of functional gradient dynamics (Theorem 1).
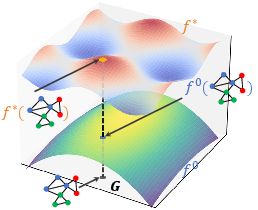
Figure 1: An illustration of the implicit mapping f∗ between a graph G and its property f∗(G), where f0 represents the initial GCN mapping.
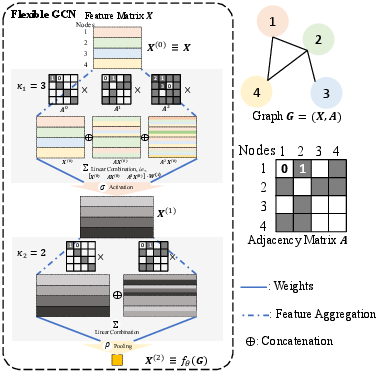
Figure 2: Workflow of a two-layer flexible GCN, highlighting permutations of feature aggregation across convolutional orders and layers.
- Teaching via Functional Gradients: The paper shows that selecting examples with the highest discrepancy between fθ(G) and f∗(G) (i.e., largest gradient component) most efficiently drives down the loss, providing sufficient conditions for loss reduction under convexity and smoothness assumptions (Proposition 1).
The GraNT Algorithm
GraNT operationalizes nonparametric teaching for GCNs. Algorithmically, it iteratively selects a subset of graphs (or node-graphs for node-level tasks) where the current GCN model's predictions most disagree with ground-truth properties. Formally, the subset maximizes the ℓ2 norm of the vector of discrepancies ∣fθ(G)−f∗(G)∣ (or the scaled Frobenius norm for node-level tasks). The selected graphs are used for the next update step, directly paralleling greedy selection in nonparametric teaching.
This selection is performed in both batch-wise (GraNT-B, selecting most informative batches) and singleton (GraNT-S, selecting individual hardest examples across batches) regimes, accommodating standard GCN training pipelines.
Empirical Evaluation
Extensive experiments demonstrate strong empirical results across standard benchmarks:
- Graph-level regression (QM9, ZINC): GraNT achieves 36–38% reductions in training time while matching or slightly improving validation/test losses and MAE.
- Graph-level classification (ogbg-molhiv, ogbg-molpcba): Training time is similarly decreased by over 30%, with ROC-AUC and AP maintained or improved relative to standard GCN training and prominent active learning and efficiency baselines.
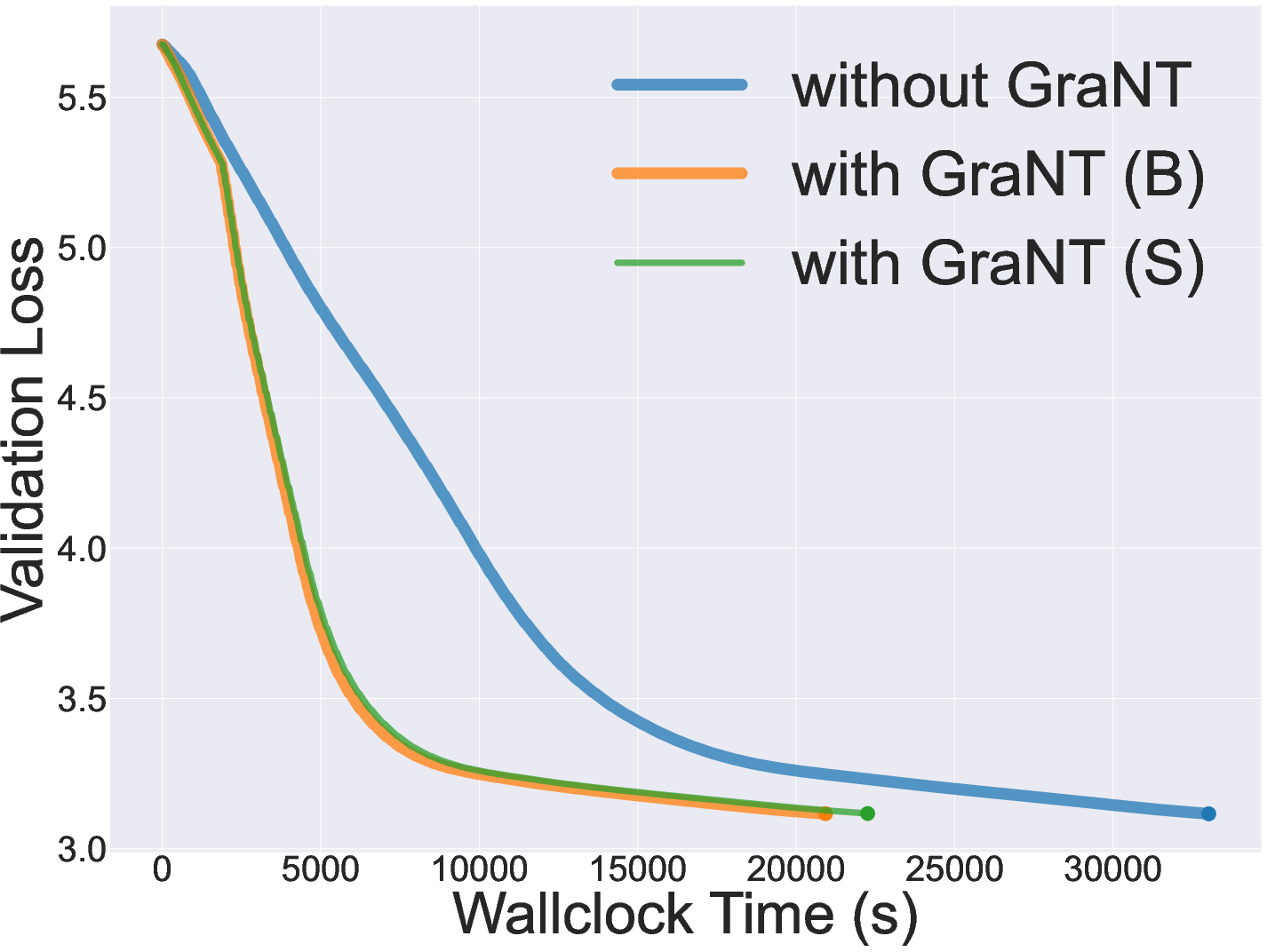
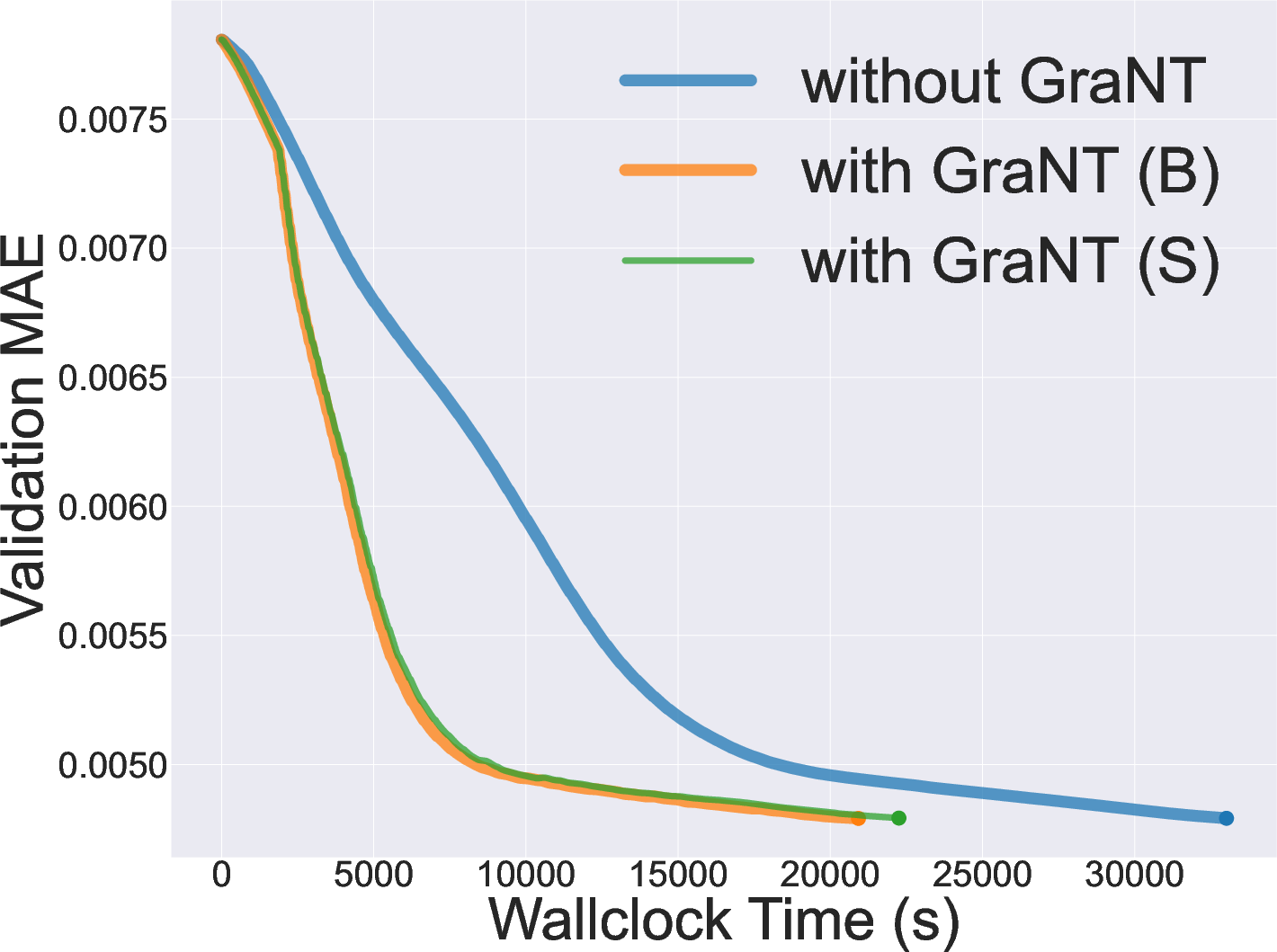
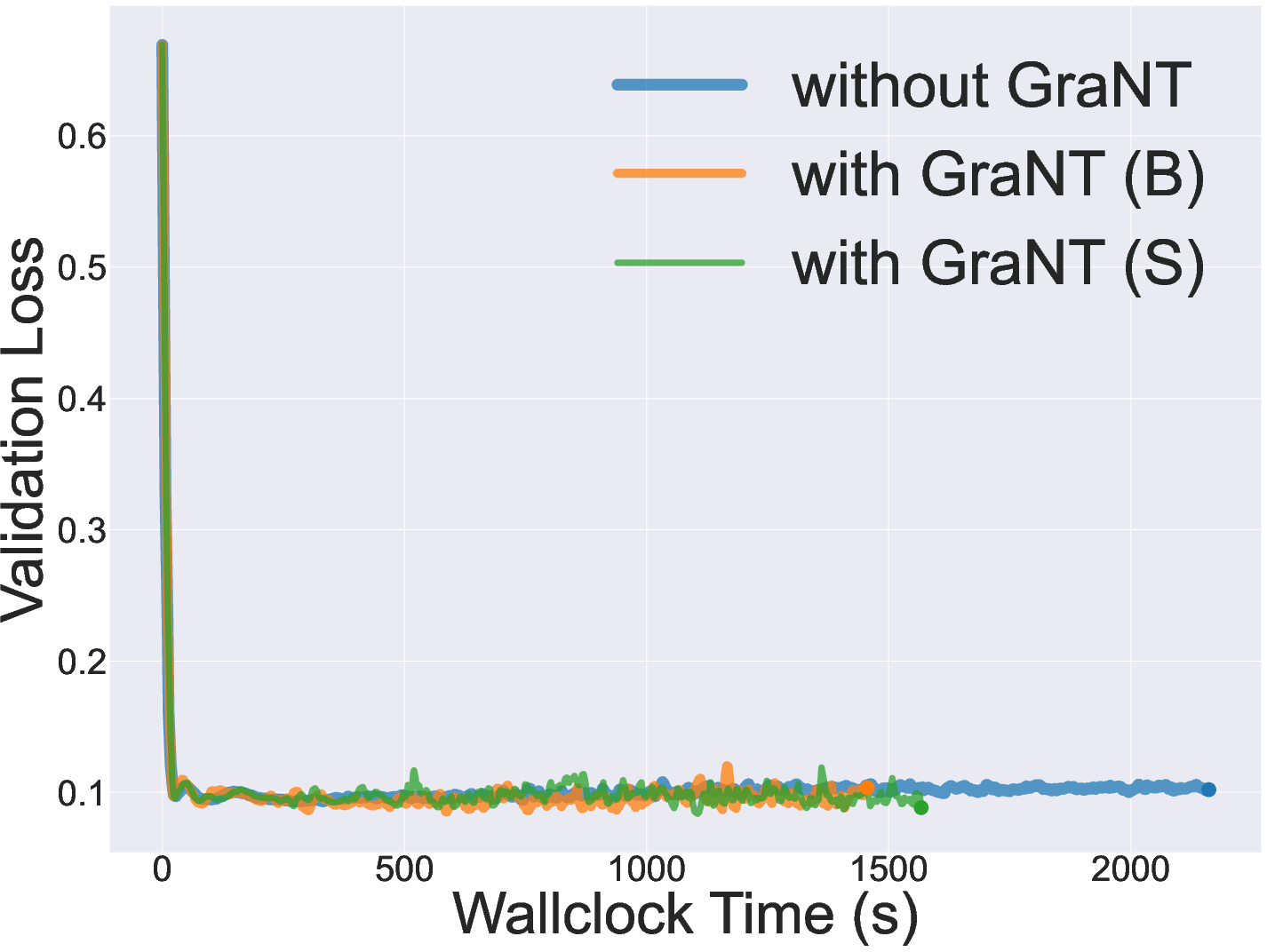
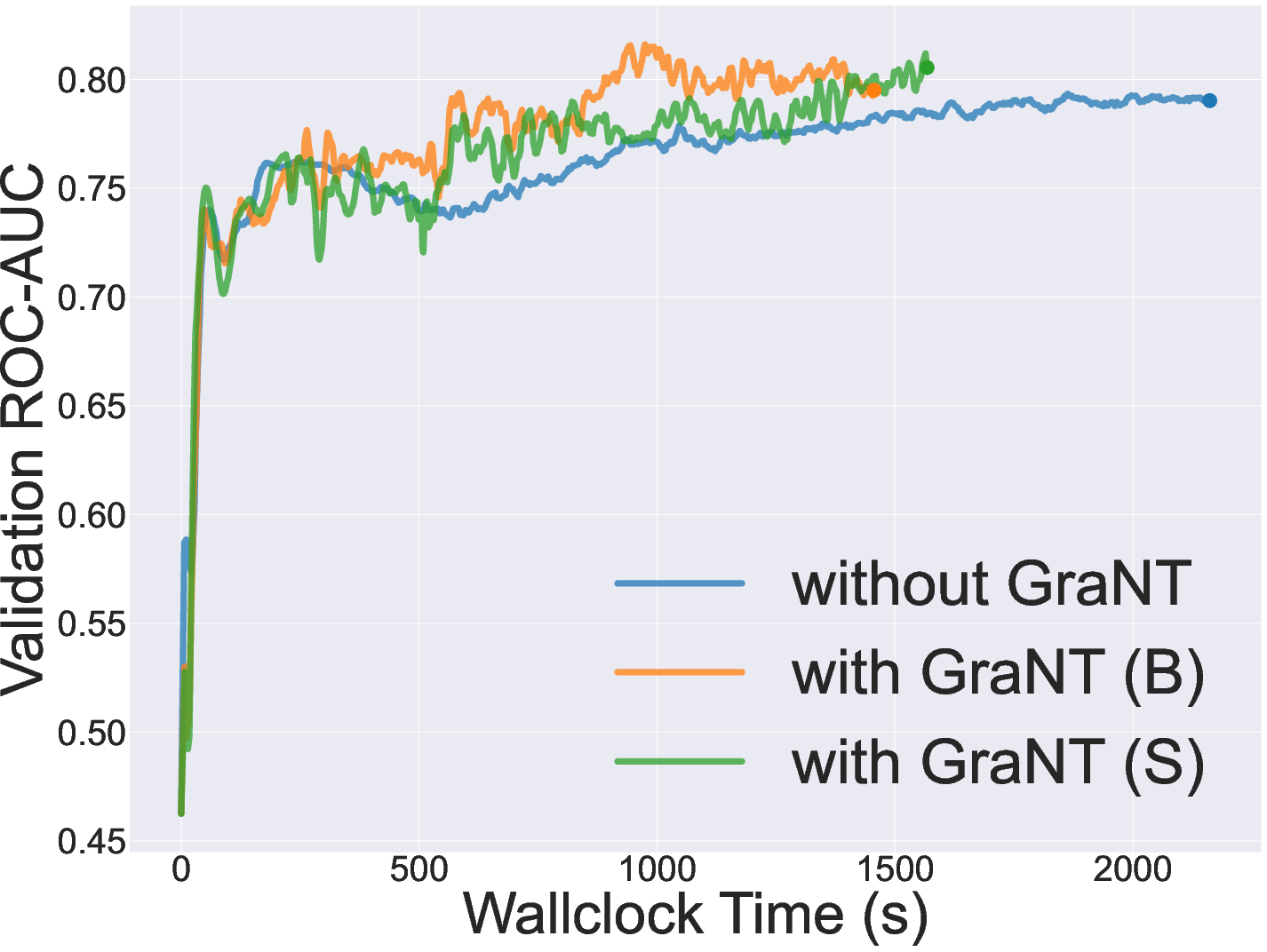
Figure 3: Validation set loss progression for ZINC graph-level regression, demonstrating accelerated convergence with GraNT variants.
- Node-level regression/classification (synthetic graphon-based data): GraNT provides 31–47% reductions in wallclock training time, with no reduction in test set generalization.
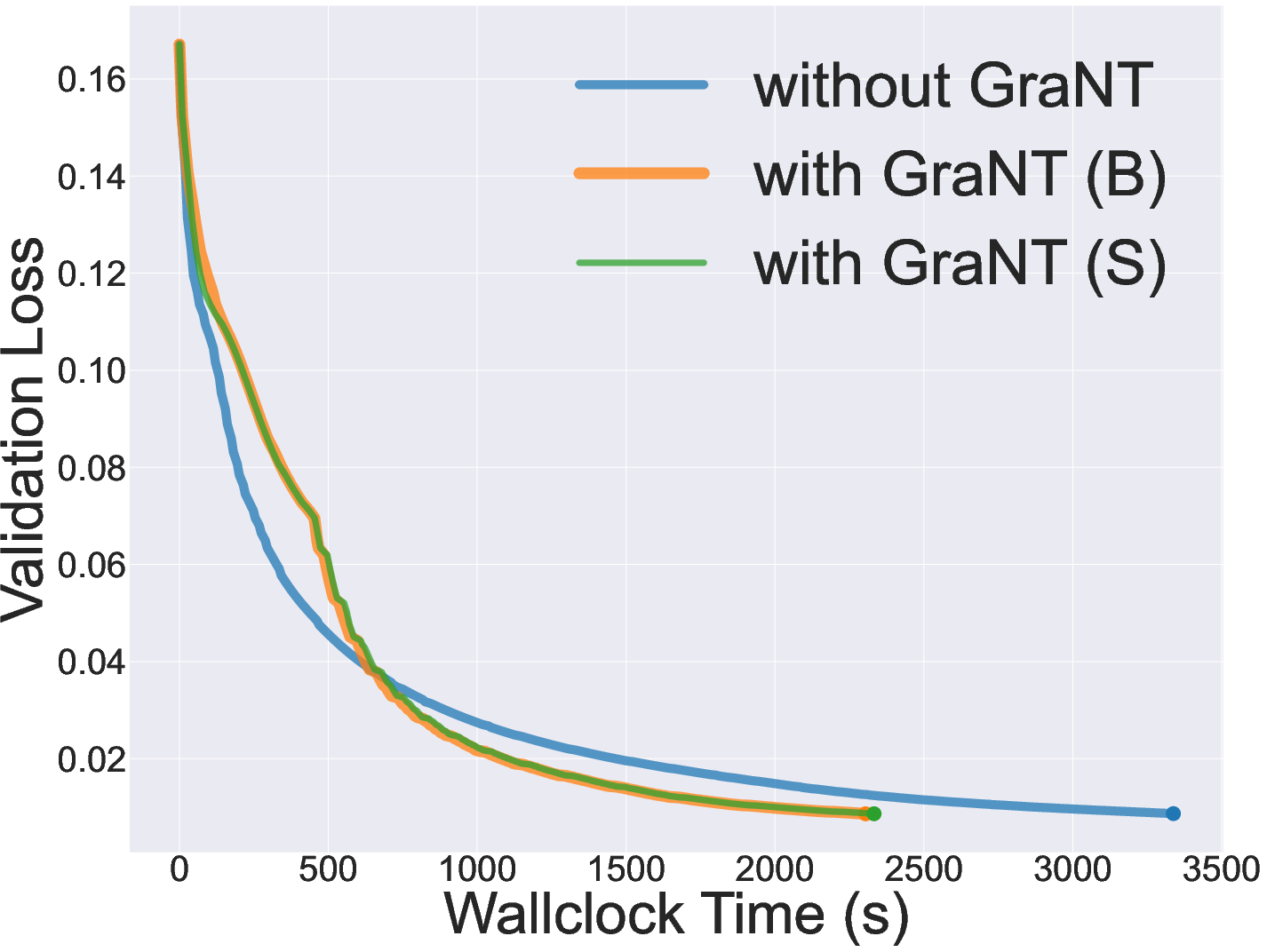
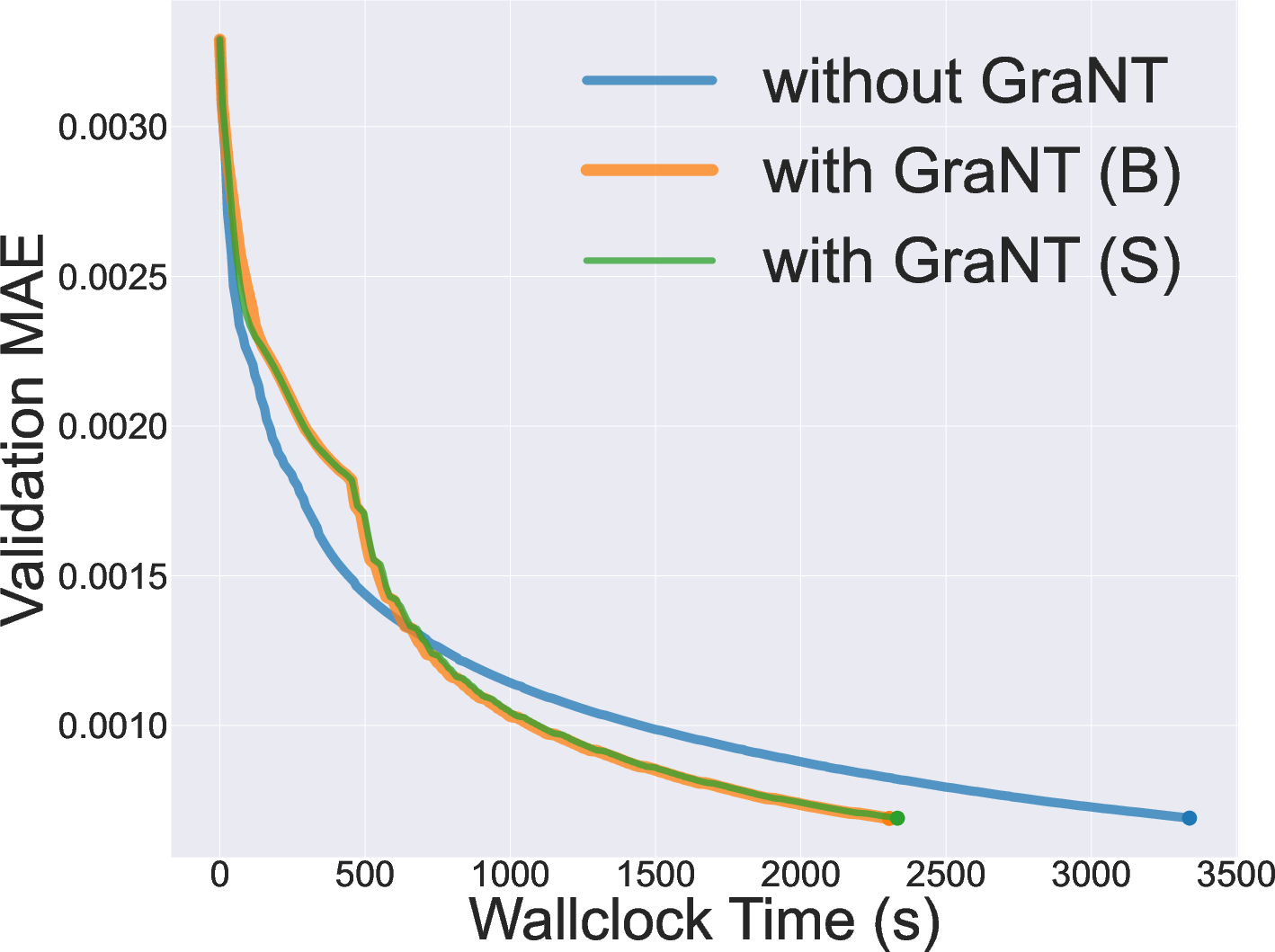
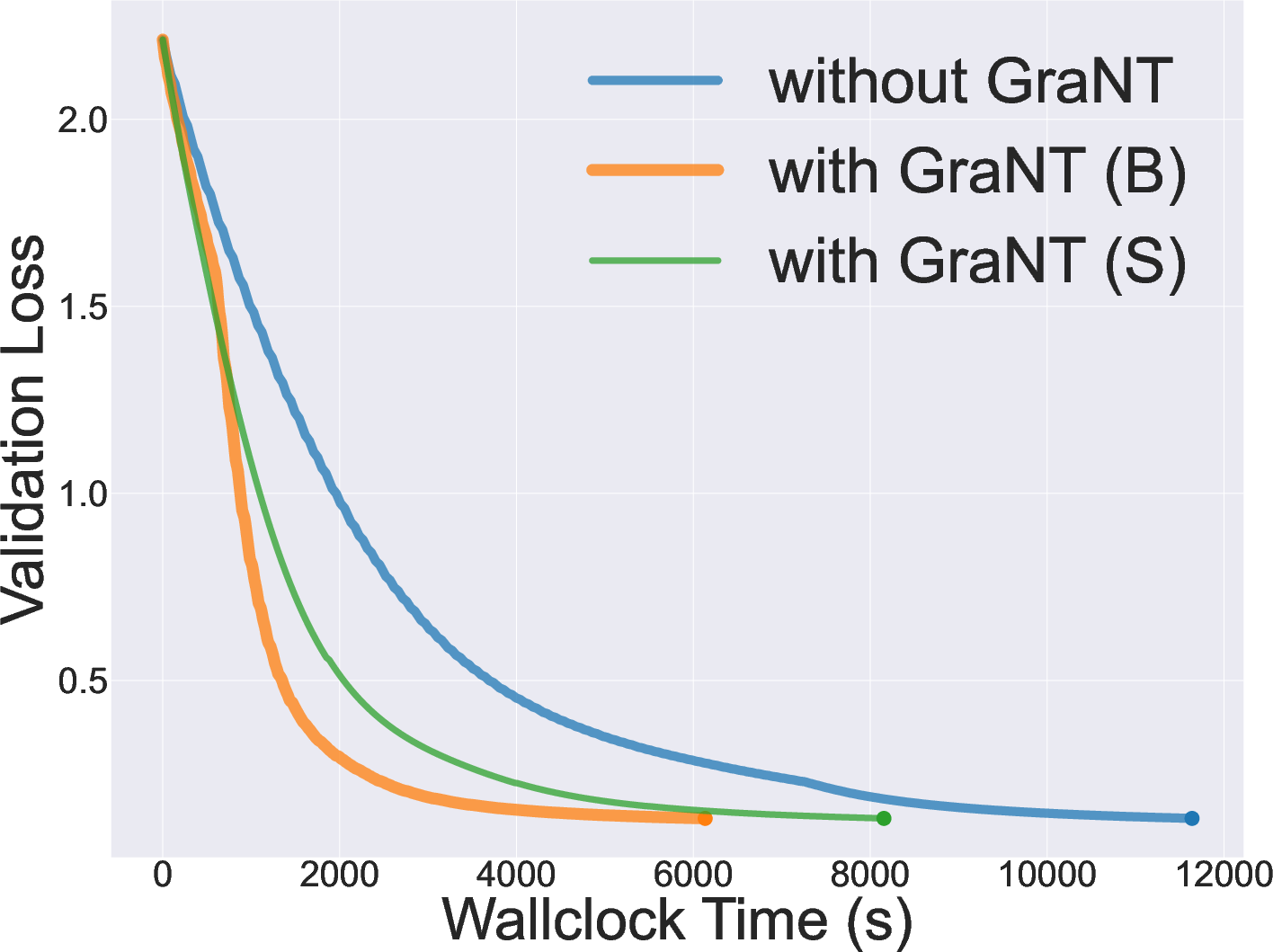
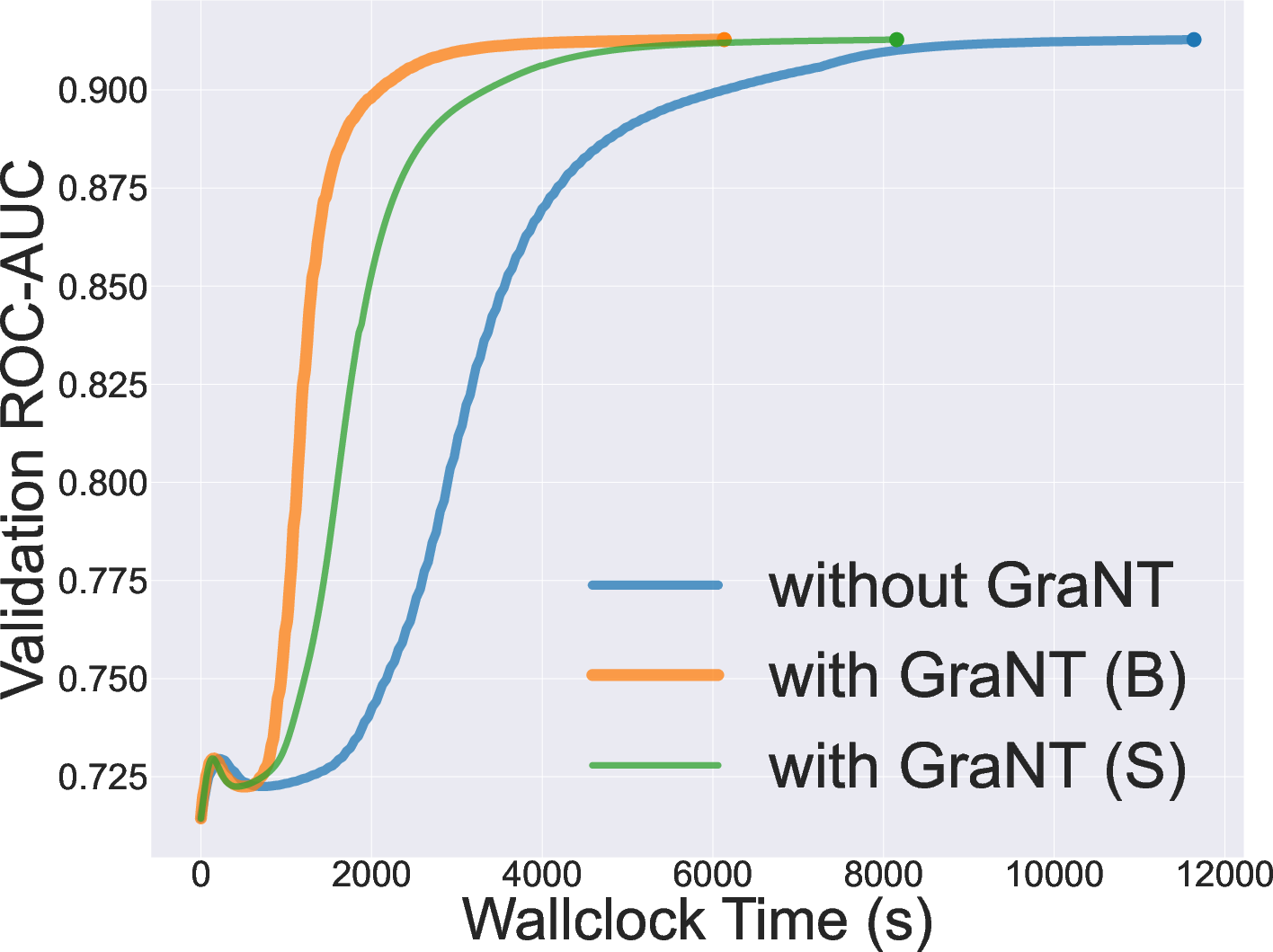
Figure 4: Validation loss on a synthetic node-level regression task ("gen-reg"), showing that GraNT enables significantly faster convergence.
In all cases, both GraNT-B and GraNT-S consistently outperform non-taught baselines with respect to time-to-convergence and often yield higher average ROC-AUC/MAE scores, despite using only the most informative subsets.
Practical and Theoretical Implications
The main implications are:
- Theoretical: This work establishes a concrete correspondence between parameter-gradient-based training in GCNs and structure-aware functional gradient flows, bridging nonparametric teaching theory and GNN practical training procedures. The proven pointwise convergence of GNTK to the canonical kernel firmly supports the use of functional teaching strategies in GNN contexts.
- Practical: By formalizing and implementing active, structure-aware example selection in the training process, GraNT enables faster GCN training—especially crucial for large-scale domains like molecular property prediction or biological network inference—without sacrificing (and sometimes improving) generalization.
- Algorithm design: The explicit connection between loss gradient norms and teaching set selection provides a foundation for further adaptive or curriculum-based training schemes. The paradigm could be extended to other GNNs such as GATs or message-passing variants.
Speculation on Future Developments
Future work should extend GraNT to a broader range of GNN architectures (attention-based, higher-order, relational GNNs) and explore integration with complex multi-task or multi-modal graph property predictors. The teaching paradigm laid out here may also inform online active learning/sampling strategies in resource-constrained scientific settings and edge-device deployment. Furthermore, the functional alignment perspective may be leveraged to develop new theoretical results on convergence and generalization in deep GNNs, as well as new teaching strategies for other nonparametric learners on irregular data.
Conclusion
The paper delivers a robust synthesis of nonparametric teaching theory and graph neural learning, culminating in a principled and empirically validated method (GraNT) for reducing GCN training costs via active, loss-gradient-informed example selection. GraNT’s adaptation of functional teaching to the structural graph domain is well-founded, theoretically sound, and directly translatable to practical implementation in large-scale graph property learning tasks. The work opens avenues for both theoretical research in structure-aware functional optimization and efficient deployment of GNNs in scientific and industrial applications.