A Decade of You Only Look Once (YOLO) for Object Detection: A Review
Abstract: This review marks the tenth anniversary of You Only Look Once (YOLO), one of the most influential frameworks in real-time object detection. Over the past decade, YOLO has evolved from a streamlined detector into a diverse family of architectures characterized by efficient design, modular scalability, and cross-domain adaptability. The paper presents a technical overview of the main versions, highlights key architectural trends, and surveys the principal application areas in which YOLO has been adopted. It also addresses evaluation practices, ethical considerations, and potential future directions for the framework's continued development. The analysis aims to provide a comprehensive and critical perspective on YOLO's trajectory and ongoing transformation.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper looks back at 10 years of “YOLO” (short for “You Only Look Once”), a famous computer program family that can quickly find and label objects in pictures and videos. YOLO helped make object detection fast enough to be used in real-time, like spotting pedestrians for self-driving cars or identifying medical tools during surgery. The authors review how YOLO started, how it changed over time, where it’s used, how it’s tested, and what might come next.
Key Objectives and Questions
The paper sets out to:
- Explain what object detection is and why it’s hard.
- Walk through the main YOLO versions (v1 to v5 and related variants) and how they improved.
- Show where YOLO is used in real life (like traffic, drones, healthcare).
- Discuss how researchers evaluate these systems and what ethical issues matter.
- Suggest future directions to keep YOLO fast, accurate, and responsible.
Methods and Approach
This is a review paper. Instead of running new experiments, the authors:
- Summarize earlier research on object detection (what came before YOLO).
- Describe benchmark datasets used to train and test detectors (like COCO and PASCAL VOC).
- Explain the common evaluation metrics (like precision, recall, and mAP).
- Break down the main YOLO models and the design ideas behind them.
- Collect and discuss trends, applications, and considerations from many papers and tools over the last decade.
To make technical ideas more approachable, here are some key terms explained in everyday language:
- Object detection: Finding “what” and “where” in an image. The model draws a rectangle (a “bounding box”) around an object and says what it is (like “dog” or “traffic light”), along with a confidence score (how sure it is).
- Bounding box: A rectangle around an object, described by position and size.
- Non-Maximum Suppression (NMS): If the model draws many overlapping boxes for the same object, NMS keeps the best one and removes the rest.
- Two-stage vs. one-stage detectors: Two-stage models first guess “candidate regions,” then check each in detail—accurate but slower. YOLO is a one-stage model that does everything in one pass, making it faster.
- Anchor boxes: Predefined “starter” rectangles (different sizes and shapes) placed across the image; the model nudges them to fit actual objects.
- Multi-scale features: Looking at the image at different levels of detail, like zooming in and out, to find tiny objects and large ones.
- Residual/skip connections: “Shortcuts” in the network that help deep models learn better and faster.
- Data augmentation: Clever ways to mix, crop, and blend images during training so the model gets tougher and more general.
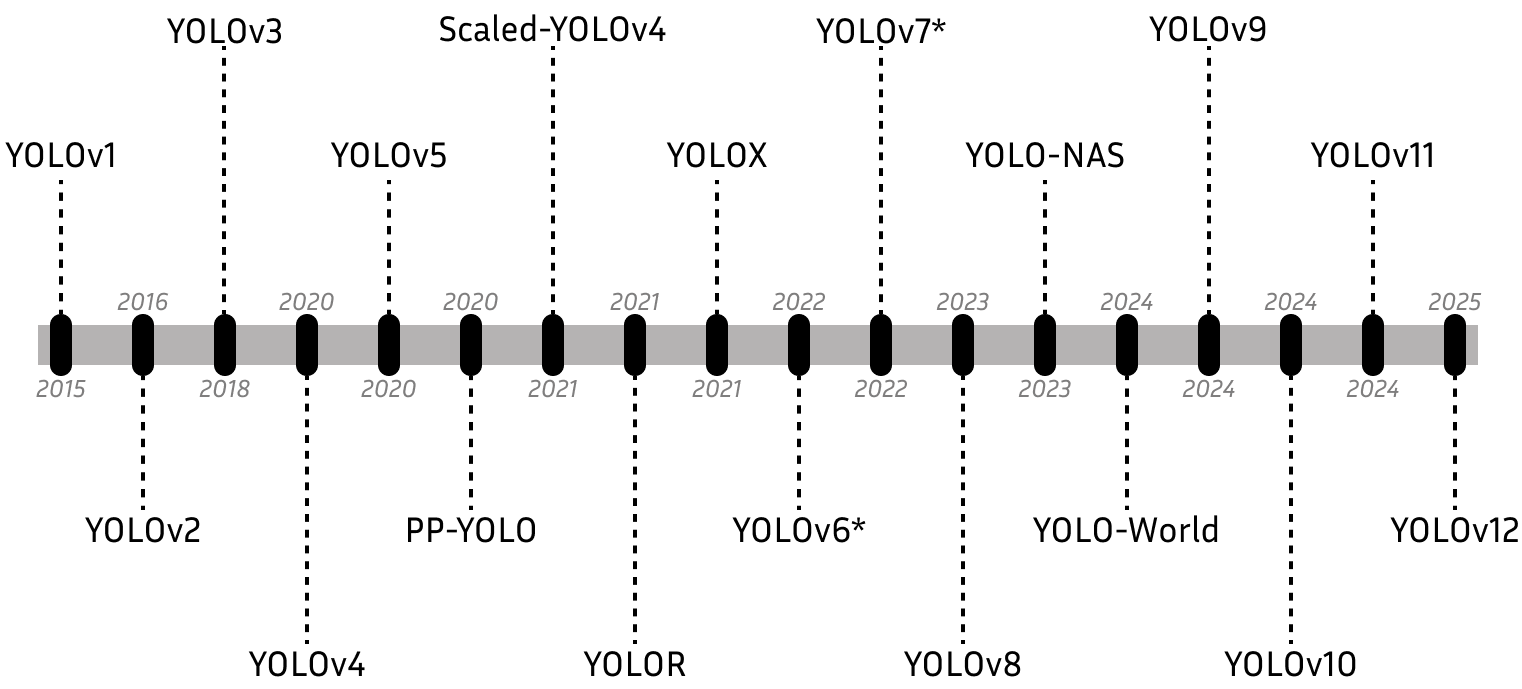
What YOLO Changed and How It Evolved
The paper walks through major YOLO versions and their improvements. In simple terms:
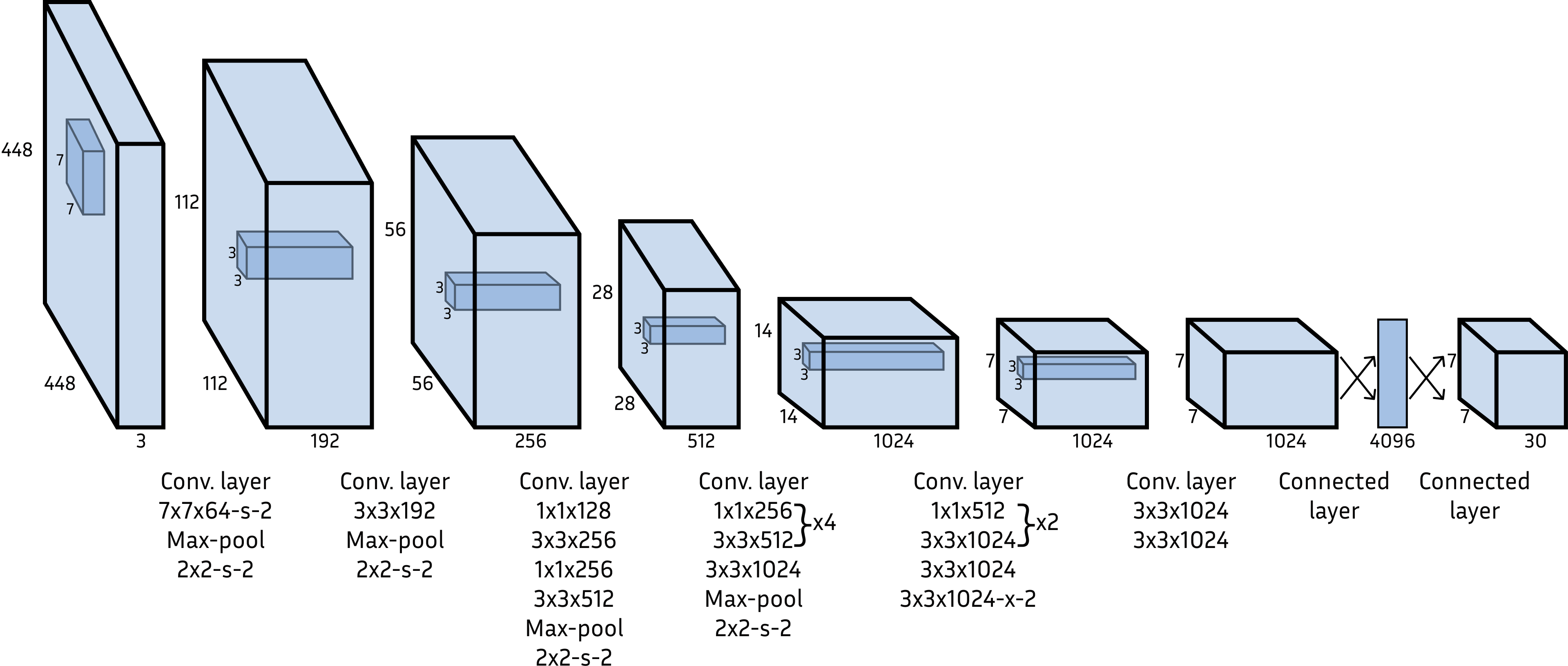
- YOLOv1 (2015): The original “You Only Look Once.” It divides the image into a grid and predicts boxes and labels in one shot. Very fast, but struggled with small or crowded objects.
- YOLOv2 + YOLO9000 (2016–2017): Smarter anchors chosen by looking at the data (k-means clustering), better training tricks like batch normalization, and multi-scale training (learning to work at different image sizes). YOLO9000 connects detection with a huge classification tree (WordTree) so it can recognize thousands of categories—even ones without detection boxes during training.
- YOLOv3 (2018): A stronger backbone (Darknet-53) with skip connections and multi-scale predictions at three sizes. This helps catch small objects better and speeds up training. It also changes class prediction to be more flexible when labels overlap.
- YOLOv4 (2020): More practical and accessible—designed to work well on a single GPU. It adds a “bag of freebies” (accuracy boosters that don’t slow down inference) and a “bag of specials” (small modules that add power at low cost). Key pieces include:
- CSPDarknet-53 backbone: Efficient feature extractor with “cross-stage partial” connections.
- PANet + SPP neck: Better mixing of features from shallow and deep layers and wider context using multiple pooling sizes.
- Training tricks: Mosaic, MixUp, CutMix (creative ways to blend training images), DropBlock (regularization), and smarter box-loss (CIoU).
- Scaled-YOLOv4 (2021): Same design ideas, but adjustable size. It scales depth, width, and input resolution to fit different devices (small, medium, large models).
- YOLOv5 (2020): Rewritten in PyTorch (a popular deep learning framework), making it easier for many people to use and extend. Continues the modular design with backbone, neck, and head, plus practical training tools and deployment support.
Along the way, YOLO models kept a core promise: fast detection with solid accuracy, and a growing toolkit that lets you pick the right size and settings for your hardware and needs.
Datasets and Metrics, Simply Explained
- Common datasets:
- PASCAL VOC: Earlier, smaller benchmark.
- ImageNet/ILSVRC: Large image dataset; includes a detection track.
- MS-COCO: Big, realistic scenes with many small objects—great for testing real-world performance.
- OpenImages: Massive dataset with many categories.
- Common metrics:
- Precision: Of the boxes the model drew, how many were correct? Think: “How careful is it?”
- Recall: Of all the real objects, how many did it find? Think: “How thorough is it?”
- mAP (mean Average Precision): A single score that balances how precise and complete the detections are across all classes and different levels of overlap.
These datasets and metrics help everyone compare models fairly.
Main Takeaways and Why They Matter
- Speed plus accuracy: YOLO made real-time object detection practical. That opened doors for safety systems, robotics, phones, and more.
- Design trends: Over time, YOLO added anchors, multi-scale predictions, efficient backbones, feature-mixing necks, and smart training tricks. Together, these made it better at finding small, overlapping, or varied objects.
- Scalability: Newer YOLO versions come in sizes, so you can choose a tiny model for a phone or a larger one for a server.
- Cross-domain use: YOLO is used for traffic monitoring, drones, medical imaging, security cameras, and more, adapting well to different contexts.
- Evaluation and ethics: The paper notes standard testing methods and raises ethical points like fairness, privacy, and responsible deployment—important when detectors are used in public spaces or critical tasks.
Implications and Future Impact
- More adaptable models: Expect continued focus on models that can run efficiently on many devices while handling complex, crowded scenes and tiny objects.
- Better training and testing: Smarter data augmentation, clearer evaluation standards, and improved losses will keep pushing accuracy forward.
- Responsible AI: As detectors are deployed everywhere, developers and users must consider bias, transparency, and privacy to ensure safe and fair use.
- Wider applications: Faster, smarter object detection can support safer roads, better medical tools, environmental monitoring, and helpful everyday apps.
In short, over ten years YOLO grew from a bold idea into a mature, flexible family of models that make fast, reliable object detection widely possible. The paper shows how that happened, what it means today, and how it might shape what comes next.
Collections
Sign up for free to add this paper to one or more collections.