- The paper demonstrates that traditional perplexity fails to predict fine-tuning performance reliably, with error rates exceeding 60%.
- It introduces effective proxy metrics like span corruption-based perplexity and k-shot learning that nearly halve prediction errors.
- A supervised Learning-to-Compare framework using LightGBM consistently improves prediction accuracy across diverse fine-tuning tasks.
Can Pre-training Indicators Reliably Predict Fine-tuning Outcomes of LLMs?
This paper explores the limitations of traditional pre-training metrics such as perplexity in predicting the fine-tuning performance of LLMs of fixed sizes. It introduces new proxy metrics that significantly enhance prediction accuracy and proposes a supervised learning approach for improving prediction efficiency.
Introduction
The paper challenges the prevailing assumption that pre-training indicators, notably perplexity, can reliably predict the fine-tuning success of LLMs with fixed parameters. It highlights the practical challenges of optimizing fine-tuning processes due to the immense computational resources required, especially when scaling up model sizes is not feasible. The authors systematically generate and evaluate multiple 1B parameter LLM variants through varied pre-training configurations, examining their performance post-SFT across tasks such as commonsense reasoning, retrieval-augmented generation, and closed-book question answering.
Experimentation and Findings
Misleading Perplexity
The investigation begins with a baseline assessment of perplexity, finding that it fails to correlate reliably with fine-tuning performance across different tasks, exhibiting error rates exceeding 60%, which is inferior even to random guessing.
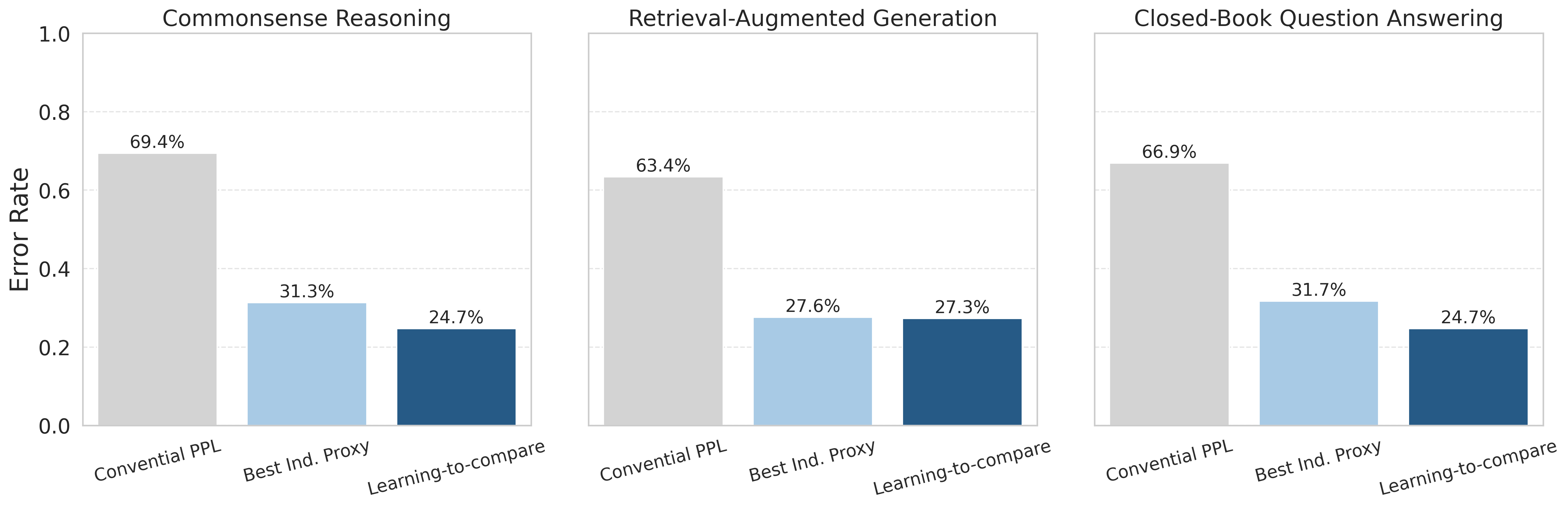
Figure 1: Mean pairwise error rates across three SFT tasks (separate plots). Each plot compares perplexity, the best individual proxy, and the learning-to-compare proxy.
Introduction of Proxy Metrics
To remedy the inadequacy observed with traditional perplexity, the study proposes new pre-training proxies:
- PPL-SC: Perplexity computed using span corruption objectives.
- Kshot Learning Performance: Performance of 1-shot and 5-shot learning configurations tailored to specific SFT tasks.
These proxies demonstrated substantial performance improvements, reducing error rates by nearly half in some tasks when compared to standard perplexity.
Learning-to-Compare Framework
To further enhance predictive accuracy, the paper introduces a Learning-to-Compare (LTC) framework. This supervised method combines multiple proxies through a classification model to estimate the fine-tuning performance, demonstrating a consistent reduction in prediction error rates. Using LightGBM as the classifier, the LTC framework achieved predictive accuracies superior to any single proxy indicator, particularly excelling in scenarios with large performance gaps between models.
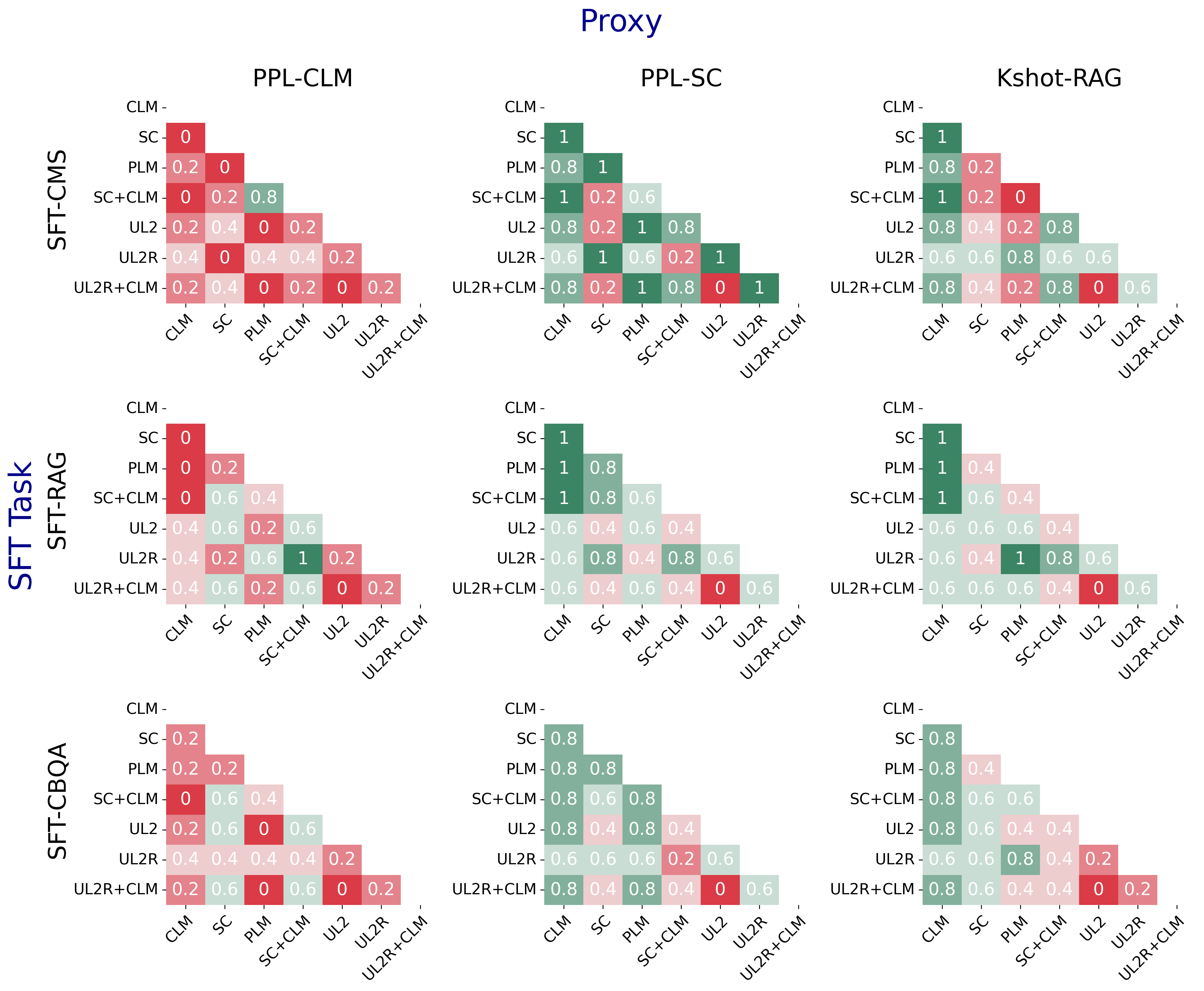
Figure 2: Pairwise prediction accuracy for PPL-CLM, PPL-SC, and Kshot-RAG across different pre-training objectives.
Impact of Model Variations
The study evaluates the generalizability of the proxy metrics and the LTC framework across LLM variants differing in pre-training objectives, domain-based dataset re-weighting, and data tagging. The analysis shows a substantial impact of such variations on predictive accuracy, with performance greatly influenced by the pre-training objectives and SFT task type.
Practical Applications
Model Selection
One critical application of this research is in selecting the most promising models from a pool, thereby reducing the computational overhead associated with comprehensive fine-tuning. The LTC framework is particularly useful here, achieving high recall rates for top-performing models from constrained candidate sets.
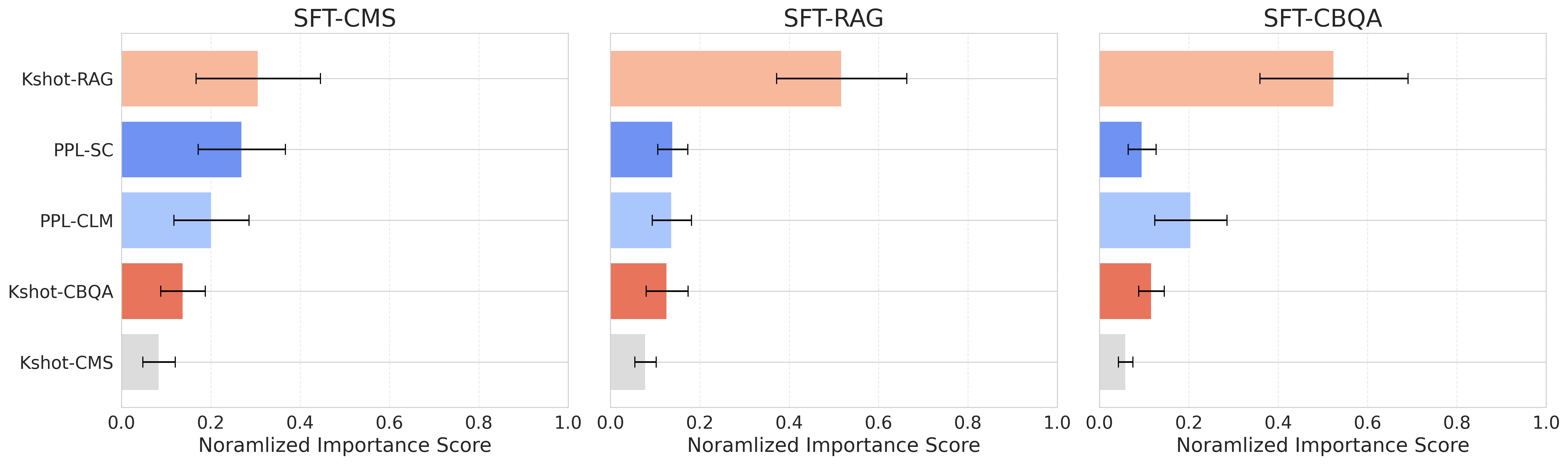
Figure 3: Relative influence of proxy metrics in the LTC framework (LightGBM).
Generalization Across Tasks
The LTC framework demonstrated strong generalization capabilities, maintaining high predictive accuracy when trained on a source task and tested on different target tasks. This offers flexibility in applying the framework across diverse fine-tuning scenarios without significant performance degradation.
Conclusion
This study provides evidence that traditional pre-training perplexity is insufficient for predicting fine-tuning outcomes in LLMs of fixed sizes. It introduces more effective proxy metrics and a supervised learning approach, significantly reducing prediction errors. These findings not only challenge the reliance on perplexity but also propose a practical solution that may promote more efficient model selection and development practices within the computational limits often faced in real-world applications.
Future research could expand these results to larger models and more divergent tasks, explore additional pre-training configurations, and refine proxy metric combinations for broader applicability.