- The paper presents GFT by introducing Gradient Attention Learning Alignment and Progressive Patch Selection to prioritize discriminative features.
- It achieves competitive accuracy on datasets like FGVC Aircraft and Food-101 with fewer parameters than conventional Vision Transformers.
- The adaptive mechanism enhances computational efficiency and robustness in complex scenes, paving the way for practical applications.
Introduction to Fine-Grained Image Classification
Fine-Grained Image Classification (FGIC) necessitates distinguishing between categories that appear superficially similar, often demanding precise recognition of subtle visual cues. Traditional approaches using handcrafted features such as SIFT and HOG struggled with the inherent complexity of such tasks. The advent of CNNs enhanced feature extraction capabilities but lacked dynamic prioritization of discriminative regions. Vision Transformers (ViT) introduced attention-driven mechanisms that helped address global context, yet they too struggled with computational efficiency and focus narrative flexibility. The presented research on Gradient Focal Transformer (GFT) integrates innovative mechanisms to prioritize class-discriminative features using dynamic learning strategies.
Methodology: GFT Architecture and Innovations
GFT builds upon the ViT framework, introducing two key components: Gradient Attention Learning Alignment (GALA) and Progressive Patch Selection (PPS). GALA utilizes gradients across attention landscapes to highlight crucial regions with high variation, focusing on where attentional change occurs most rapidly rather than on absolute attention values.
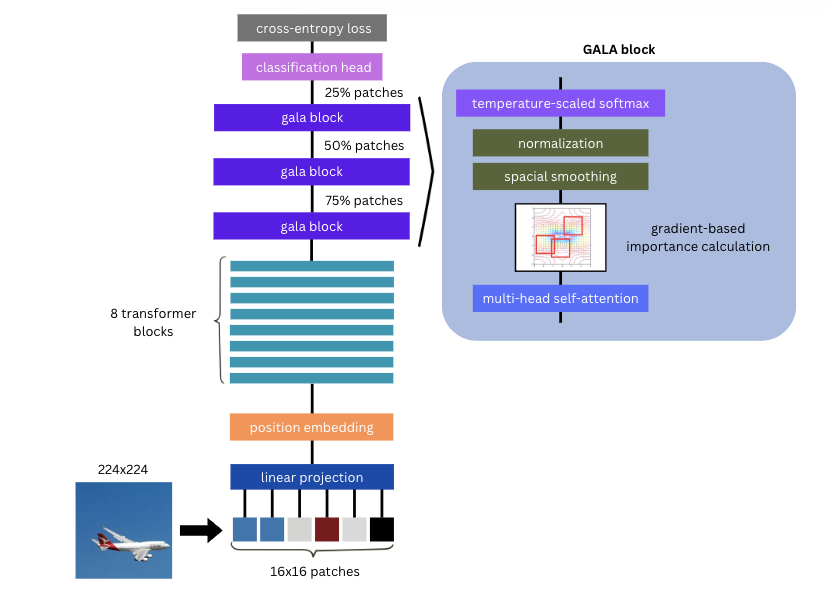
Figure 1: GFT Architecture Overview.
PPS implements a multi-stage refinement strategy to filter out less informative patches progressively, which aligns with natural attention patterns where focus transitions from coarse to fine detail. It significantly reduces computational overhead while enhancing sensitivity to intricate visual features.
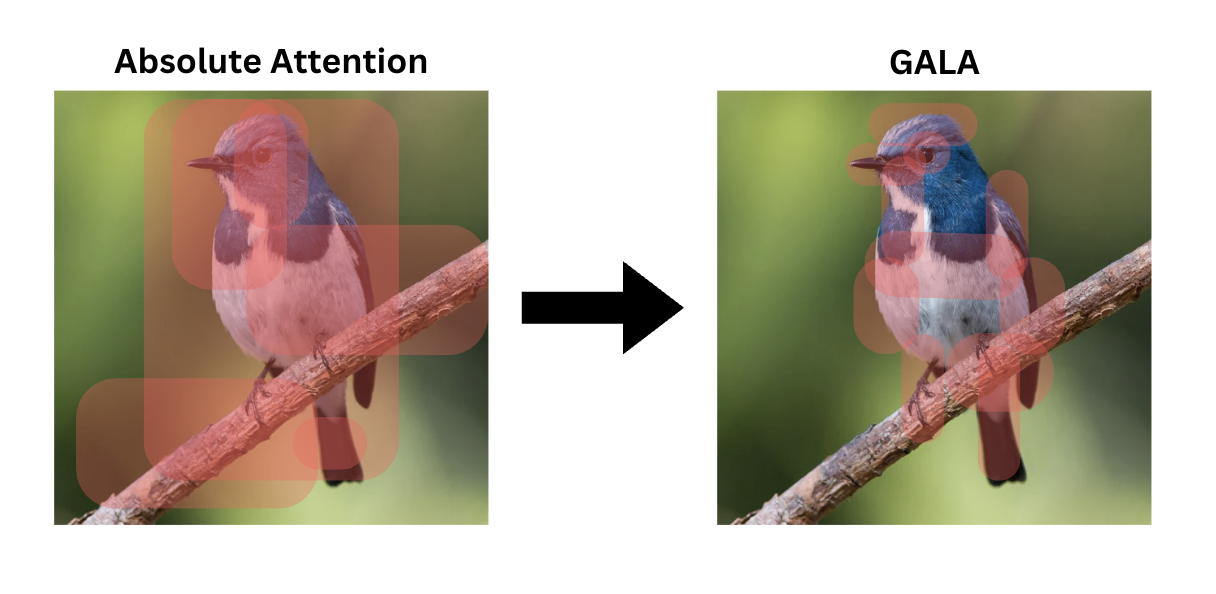
Figure 2: Absolute Attention vs GALA.
Empirical Analysis and Results
Extensive experiments demonstrate GFT's capabilities across FGVC Aircraft, Food-101, and COCO datasets. On FGVC Aircraft, GFT achieves competitive accuracy with fewer parameters compared to TransFG, showcasing enhanced generalization from precise feature selection.

Figure 3: Progressive Patch Selection in GFT.
GFT achieves superior accuracy in datasets with high intra-class variation, such as Food-101, highlighting its ability to filter redundant details effectively. The models consistently outperform traditional ViT models, proving their robustness in complex scenes such as those in the COCO dataset due to advanced learning mechanisms.

Figure 4: GFT Importance Regions in FGVC Aircraft Dataset.
Implications and Future Directions
GFT represents a significant advancement in FGIC, pushing the boundaries of efficiency and accuracy in ViT models. The adaptive nature of feature selection offers potential for real-world applications where discriminative precision is crucial. Future research could explore integrating multimodal data inputs or optimizing for deployment on resource-constrained devices to expand its applicability.
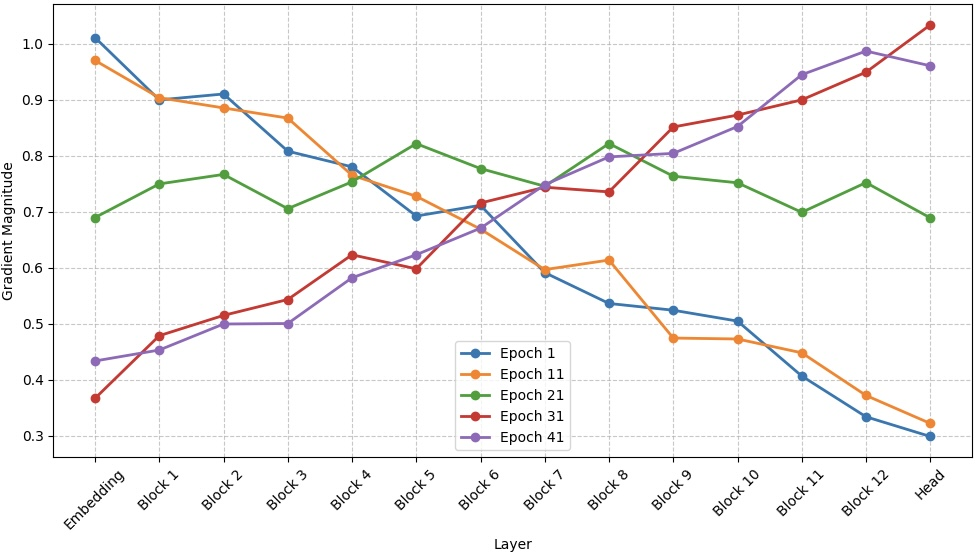
Figure 5: Gradient Flow across GFT Layers.
Conclusion
GFT, through GALA and PPS, addresses existing challenges in FGIC, offering an interpretable and efficient solution that maintains robust classification accuracy. While computational requirements are improved, further optimization for edge devices could extend its utility. The framework sets a promising new standard for fine-grained image classification, with potential for further enhancements integrating diverse data inputs.


