Bridging Items and Language: A Transition Paradigm for Large Language Model-Based Recommendation
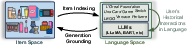
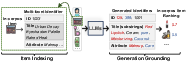
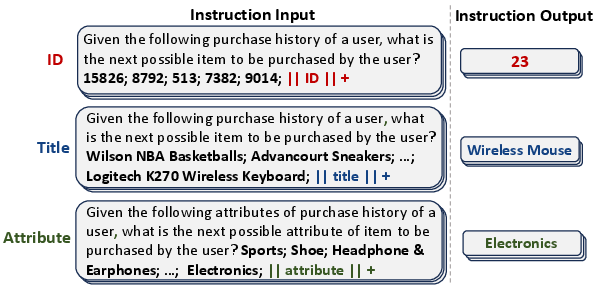
Abstract: Harnessing LLMs for recommendation is rapidly emerging, which relies on two fundamental steps to bridge the recommendation item space and the language space: 1) item indexing utilizes identifiers to represent items in the language space, and 2) generation grounding associates LLMs' generated token sequences to in-corpus items. However, previous methods exhibit inherent limitations in the two steps. Existing ID-based identifiers (e.g., numeric IDs) and description-based identifiers (e.g., titles) either lose semantics or lack adequate distinctiveness. Moreover, prior generation grounding methods might generate invalid identifiers, thus misaligning with in-corpus items. To address these issues, we propose a novel Transition paradigm for LLM-based Recommender (named TransRec) to bridge items and language. Specifically, TransRec presents multi-facet identifiers, which simultaneously incorporate ID, title, and attribute for item indexing to pursue both distinctiveness and semantics. Additionally, we introduce a specialized data structure for TransRec to ensure generating valid identifiers only and utilize substring indexing to encourage LLMs to generate from any position of identifiers. Lastly, TransRec presents an aggregated grounding module to leverage generated multi-facet identifiers to rank in-corpus items efficiently. We instantiate TransRec on two backbone models, BART-large and LLaMA-7B. Extensive results on three real-world datasets under diverse settings validate the superiority of TransRec.
- A bi-step grounding paradigm for large language models in recommendation systems. arXiv:2308.08434.
- Tallrec: An effective and efficient tuning framework to align large language model with recommendation. In RecSys. ACM.
- Towards language models that can see: Computer vision through the lens of natural language. arXiv:2306.16410.
- Autoregressive search engines: Generating substrings as document identifiers. NeurIPS 35 (2022), 31668–31683.
- Zheng Chen. 2023. PALR: Personalization Aware LLMs for Recommendation. arXiv preprint arXiv:2305.07622 (2023).
- M6-rec: Generative pretrained language models are open-ended recommender systems. arXiv:2205.08084.
- Uncovering ChatGPT’s Capabilities in Recommender Systems. arXiv:2305.02182.
- Autoregressive entity retrieval. arXiv:2010.00904.
- Toward personalized answer generation in e-commerce via multi-perspective preference modeling. TOIS 40, 4 (2022), 1–28.
- Paolo Ferragina and Giovanni Manzini. 2000. Opportunistic data structures with applications. In Proceedings 41st annual symposium on foundations of computer science. IEEE, 390–398.
- Chat-rec: Towards interactive and explainable llms-augmented recommender system. arXiv:2303.14524.
- Recommendation as language processing (rlp): A unified pretrain, personalized prompt & predict paradigm (p5). In RecSys. ACM, 299–315.
- Retrieval augmented language model pre-training. In ICML. PMLR, 3929–3938.
- Lightgcn: Simplifying and powering graph convolution network for recommendation. In SIGIR. 639–648.
- Session-based recommendations with recurrent neural networks. In ICLR.
- Bros: A pre-trained language model focusing on text and layout for better key information extraction from documents. In AAAI, Vol. 36. AAAI press, 10767–10775.
- Large language models are zero-shot rankers for recommender systems. arXiv:2305.08845.
- Lora: Low-rank adaptation of large language models. arXiv:2106.09685.
- How to Index Item IDs for Recommendation Foundation Models. arXiv:2305.06569.
- Wang-Cheng Kang and Julian McAuley. 2018. Self-attentive sequential recommendation. In ICDM. IEEE, 197–206.
- Diederik P Kingma and Jimmy Ba. 2014. Adam: A Method for Stochastic Optimization. In arXiv:1412.6980.
- Large language models are zero-shot reasoners. NeurIPS 35 (2022), 22199–22213.
- Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. arXiv:1910.13461.
- Multiview Identifiers Enhanced Generative Retrieval. In ACL. ACM.
- Code as policies: Language model programs for embodied control. In ICRA. IEEE, 9493–9500.
- Is chatgpt a good recommender? a preliminary study. arXiv:2304.10149.
- Ilya Loshchilov and Frank Hutter. 2017. Decoupled weight decay regularization. arXiv:1711.05101.
- Training language models to follow instructions with human feedback. NeurIPS 35 (2022), 27730–27744.
- BPR: Bayesian personalized ranking from implicit feedback. In UAI. AUAI Press, 452–461.
- Llama: Open and efficient foundation language models. arXiv:2302.13971.
- Lei Wang and Ee-Peng Lim. 2023. Zero-Shot Next-Item Recommendation using Large Pretrained Language Models. arXiv:2304.03153.
- Mm-rec: Visiolinguistic model empowered multimodal news recommendation. In SIGIR. ACM, 2560–2564.
- Towards Open-World Recommendation with Knowledge Augmentation from Large Language Models. arXiv:2306.10933.
- Adversarial and contrastive variational autoencoder for sequential recommendation. In WWW. ACM, 449–459.
- Recommendation as instruction following: A large language model empowered recommendation approach. arXiv:2305.07001.
- UNBERT: User-News Matching BERT for News Recommendation.. In IJCAI. 3356–3362.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.