- The paper demonstrates that funnel-aware pretraining mitigates information loss, achieving up to a 44% latency reduction in Gemma2 models.
- The study systematically evaluates pretraining, fine-tuning, and recovery operations, highlighting the trade-offs between computational efficiency and accuracy.
- Recovery operations using averaged layer outputs effectively balance detailed and abstract feature representations for improved NER performance.
Introduction
The computational demands of Transformer-based LLMs have prompted ongoing research into optimizing performance without sacrificing accuracy. This paper builds upon the Funnel Transformer architecture, initially proposed by Zihang Dai and Quoc Le, addressing its applicability in contemporary Gemma2 models. The Funnel Transformer reduces sequence length by pooling intermediate representations, thus aiming to streamline processing and mitigate self-attention's quadratic scaling issues. This study explores varying configurations of funnel architecture within the Gemma2 model family, specifically focusing on the balance between computational efficiency and model accuracy.
Methodology
The study examines the effects of different funnel configurations on the performance of Gemma2 models. It systematically evaluates three primary aspects: pretraining strategies, fine-tuning impacts, and sequence recovery operations. This investigation is performed on benchmarks such as GLUE, CoNLL-2003 NER, and an internal WebAnswers classification task to understand how funneling influences model accuracy and operational efficiency.
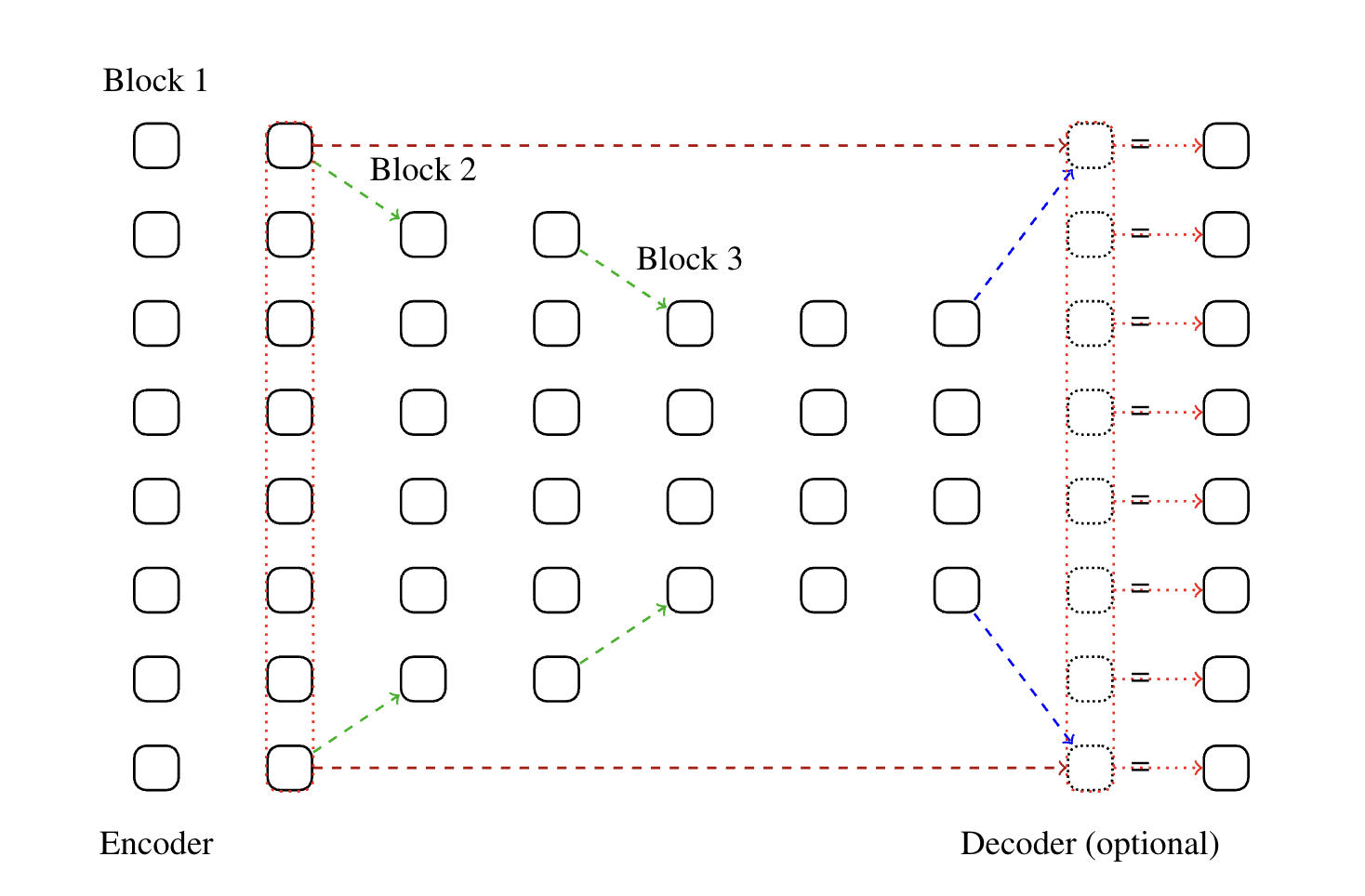
Figure 1: A representation of a funnel architecture with seven encoder layers and two funneling operations -- one at the "last" pre-funneling layer, layer 3, and one at the recovery sequence layer, layer 7.
Experimental Results
Pretraining Strategies
The study reveals that funnel-aware pretraining can mitigate the performance degradation typically imposed by funneling configurations. Notably, funnel-aware setups demonstrated effectiveness in counterbalancing the information loss that may occur through funneling in the Gemma2 models. The results showed an up to 44% reduction in latency, underscoring the computational benefits of funnel architectures.
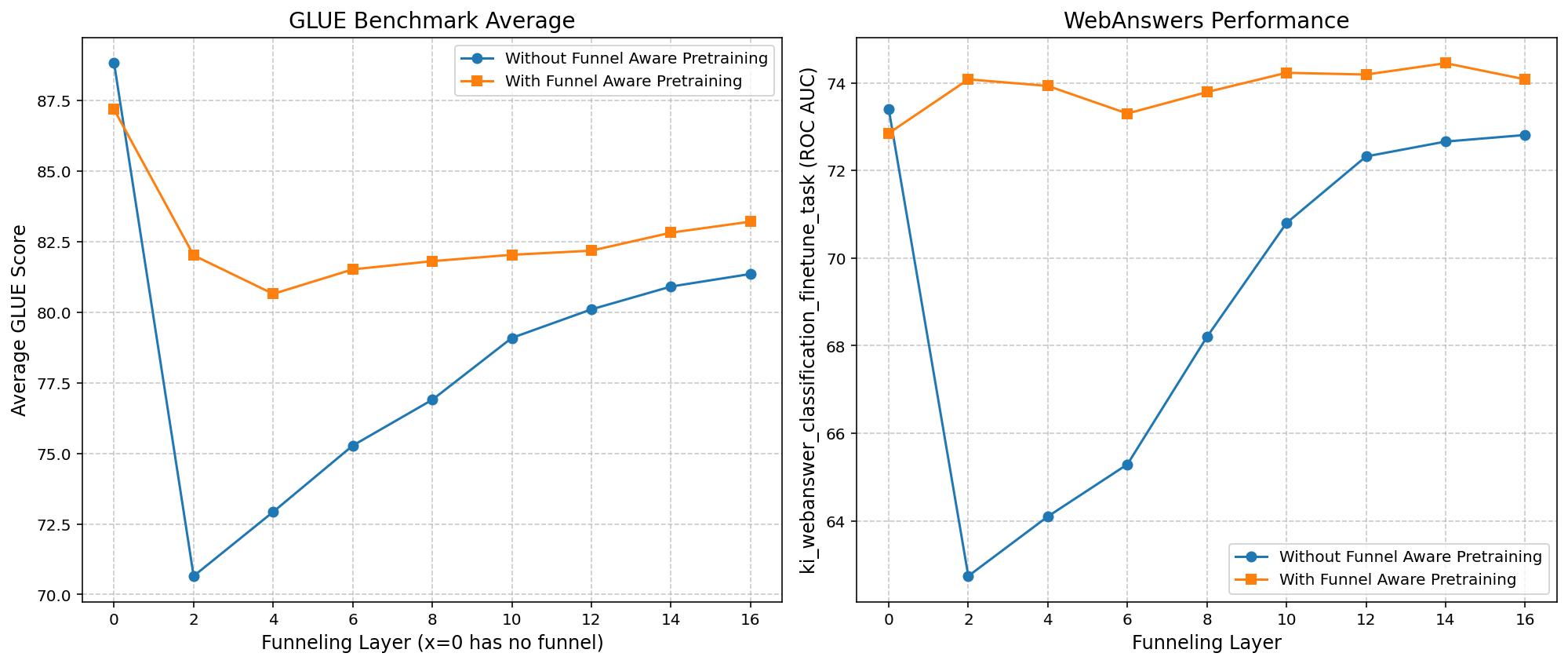
Figure 2: Performance on (a) GLUE benchmark (Average GLUE Score) and (b) WebAnswers ROC AUC as a function of the funnel recovery layer. The x=0 point corresponds to the model without funneling.
Fine-tuning Impacts
Fine-tuning on funnel-aware architectures revealed substantial performance improvements, particularly in models where funnel-aware pretraining was previously conducted. The larger Gemma2 7B model, while starting with a higher baseline, suffered more from deeper information bottlenecks induced by funneling than the smaller Gemma2 2B model.
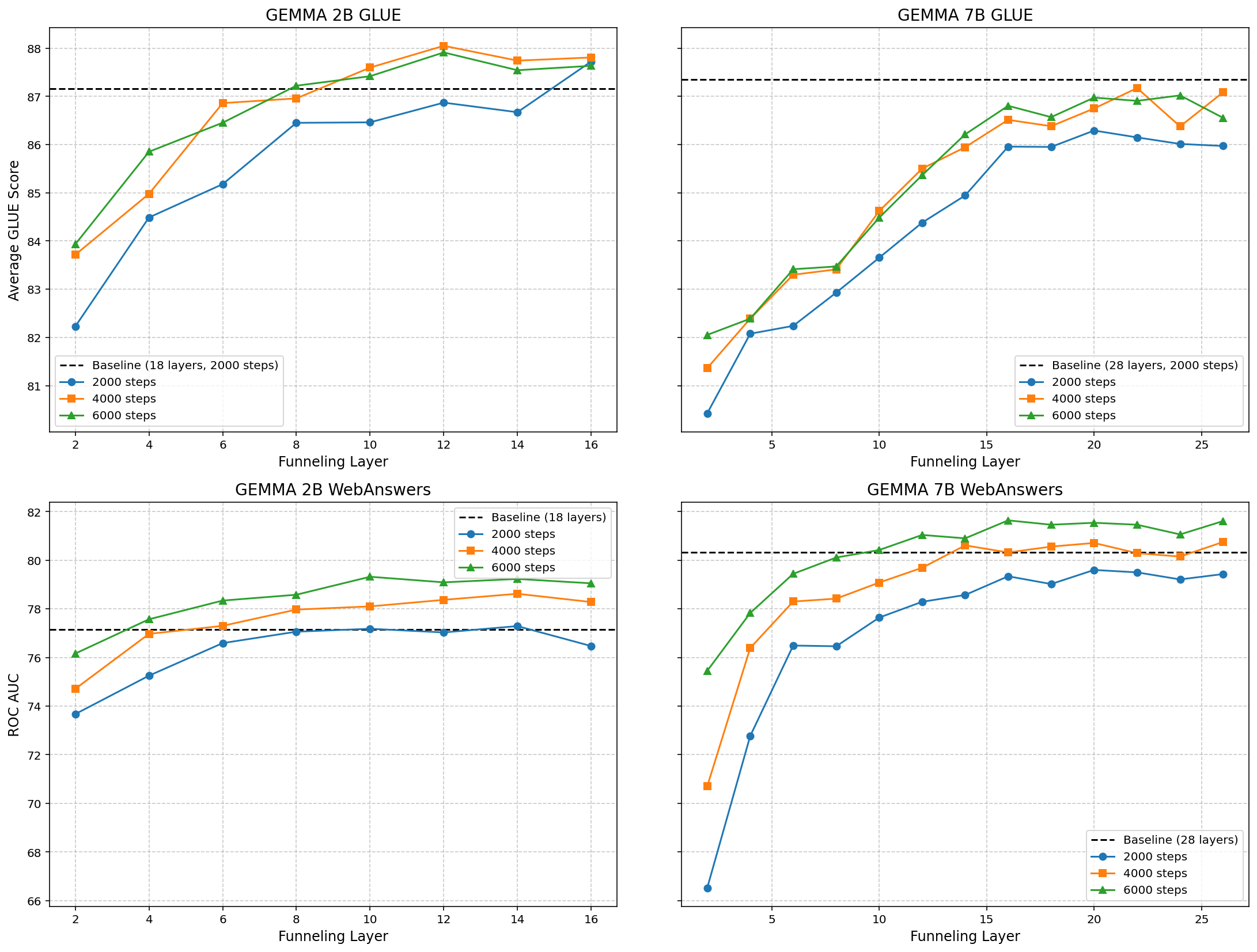
Figure 3: Performance of Gemma2 2B (left) and Gemma2 7B (right) on GLUE (top row) and WebAnswers ROC AUC (bottom row) against successive layers at which 2-token funnel is applied.
Recovery Operations
Different recovery operations were evaluated to understand their impact on sequence length recovery's effectiveness. Averaging the outputs of compressed and uncompressed layers emerged as the most robust strategy, balancing detailed and abstract feature integrations.
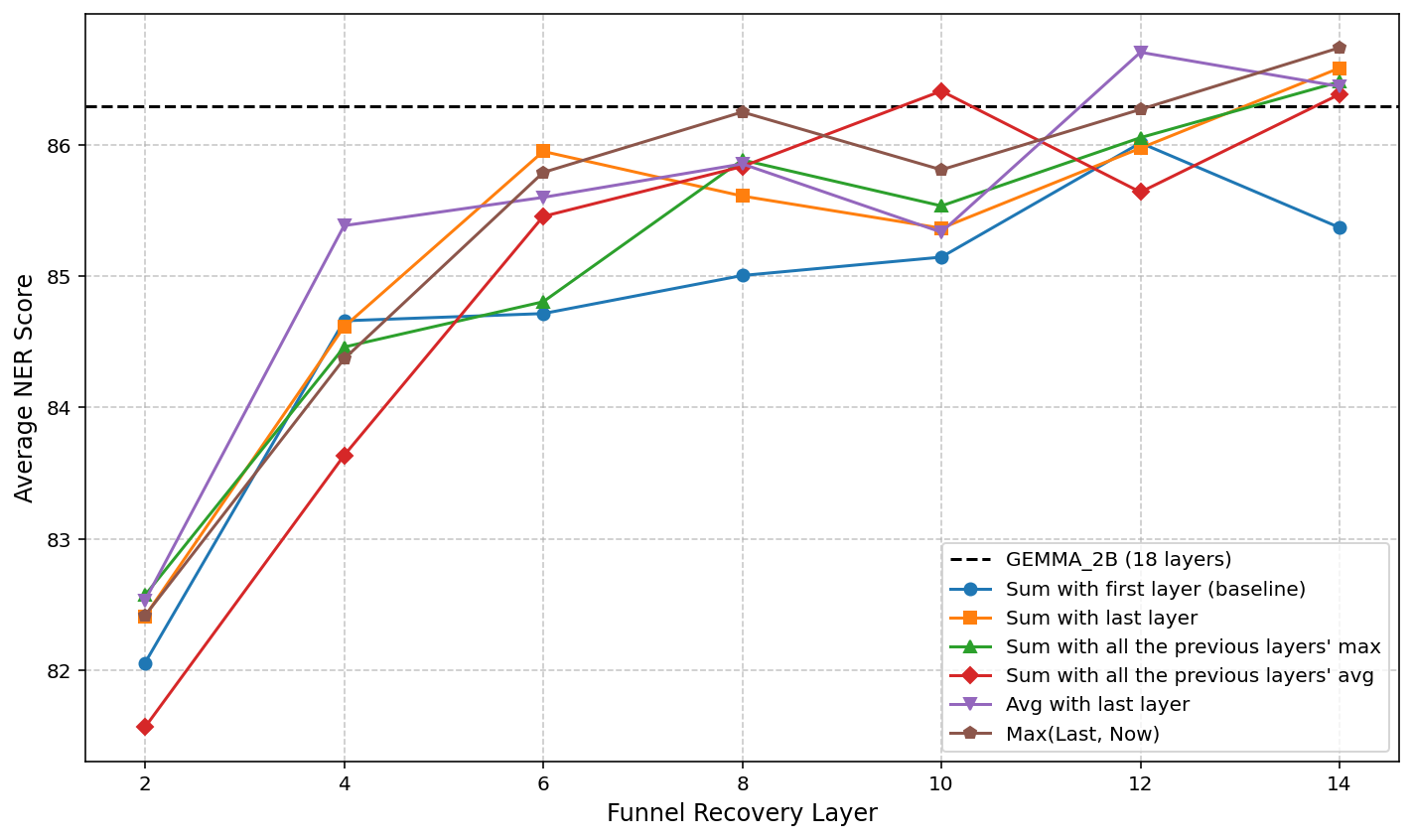
Figure 4: The effect of different recovery operations on NER performance.
Discussion and Conclusions
The paper highlights the critical trade-offs between computational efficiency and accuracy in funnel transformers. While funneling operations introduce information bottlenecks, strategic placement and recovery methods can significantly mitigate adverse effects. The models benefit from funnel-aware pretraining, particularly when employing appropriate recovery operations, to maintain performance. Future research should explore variations in funnel configurations, mix-of-expert models, and alternative pooling strategies to further enhance efficiency in large-scale NLP applications.
In conclusion, this work provides insights into effectively applying funnel transformers within modern LLM architectures, offering guidelines for achieving the delicate balance between latency reduction and model accuracy. Further investigation is needed to test these findings across diverse model architectures and benchmarks.
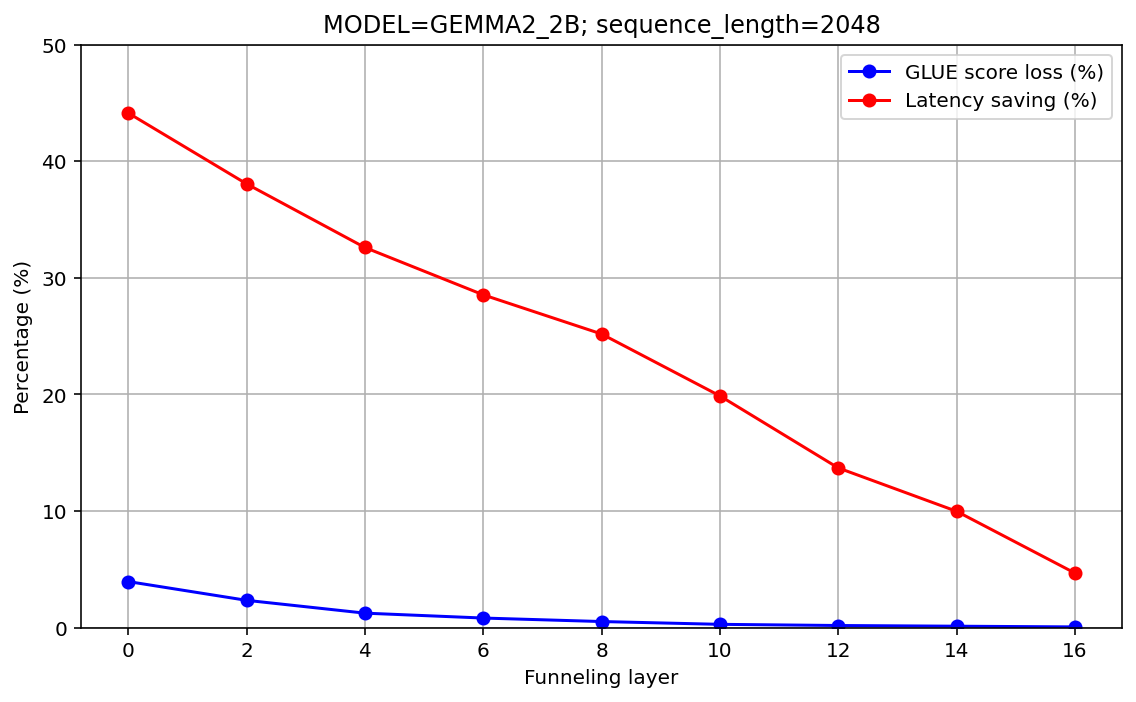
Figure 5: Comparison of latency versus performance gains.

