- The paper demonstrates integrating multilingual text during visual instruction tuning to reduce English bias and enhance multilingual capacity in VLMs.
- It employs three strategies (TR-1S, TR-2S, TR-3S) to effectively integrate multilingual data without compromising visual performance.
- Results show that TR-3S models achieve superior language fidelity across 35 European languages, though challenges remain for unseen languages.
Breaking Language Barriers in Visual LLMs via Multilingual Textual Regularization
Introduction
The proliferation of Visual LLMs (VLMs) has revolutionized multimodal understanding, but these models are often restricted by their preference to generate English responses. This constraint arises due to the lack of multimodal multilingual data, termed Image-induced Fidelity Loss (IFL). The study proposes integrating multilingual text-only data during visual instruction tuning to preserve multilingual capacity in VLMs without compromising visual understanding.
Methodology
The core strategy involves augmenting VLM training with multilingual textual data during different stages of visual instruction tuning. This process aims to maintain the original multilingual capabilities of the LLM (LM) (Figure 1).
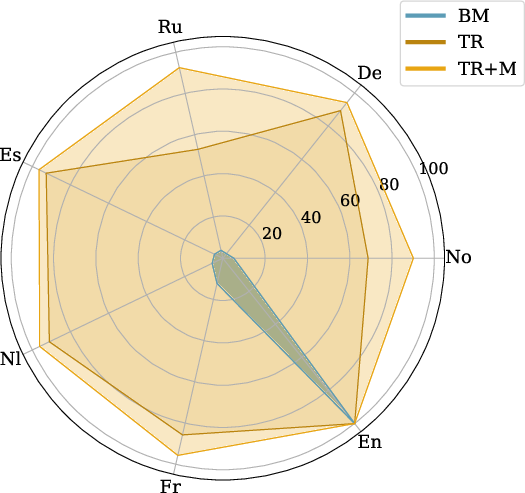
Figure 1: Language Fidelity (LF) accuracy on Crossmodal-3600. (BM: Base Model, TR: model trained with multilingual Textual Regularization, TR+M: TR and merging the final model with the original LLM Backbone)
To achieve robust textual integration, three distinct strategies were evaluated: integration across three stages (TR-3S), two stages (TR-2S), and a single stage (TR-1S), with participation across different languages captured in the training data mix. This approach enhances coverage and fidelity without reliance on large multilingual vision-language datasets.
Experimental Setup
The experimental setup employs a training framework marrying multimodal visual-language data with multilingual text-only instruction data. The baseline VLM architecture involves coupling a vision encoder with a multilingual LLM backbone. The datasets encompass a mix of general, detailed, and task-specific images, alongside multilingual text samples across 35 European languages (Figure 2).
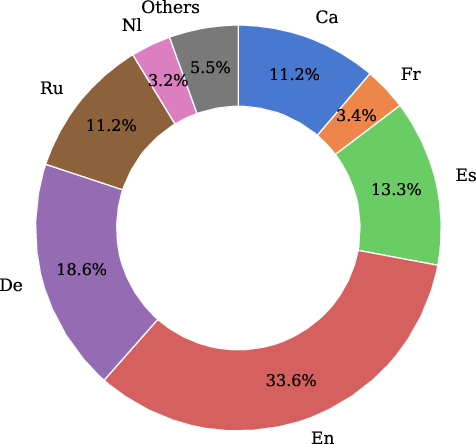
Figure 2: Distribution of the multilingual text-only data used for Textual Regularization. Languages with a volume smaller than 3\% are grouped under Others, which collectively account for 5.5\% of the data.
Results and Discussion
The multilingual integration demonstrated a significant reduction in English bias across VLMs. Evaluation of LF accuracy showed that models utilizing TR-3S achieved superior multilingual competence without trade-offs in visual performance. Furthermore, experiments indicated the importance of strategically distributing multilingual text across several training phases.
Generalization Challenges
Despite improvements, generalization to languages not present in the training data remains a challenge. The limited performance for unseen languages underscores the necessity of explicit language inclusion during training.
Model Merging
In an effort to further enhance multilingual capacity, merging trained models with their original LLM backbones was explored, resulting in improved LF metrics. However, this approach introduces a trade-off, with some degradation observed in the model's ability to perform general visual-language tasks.
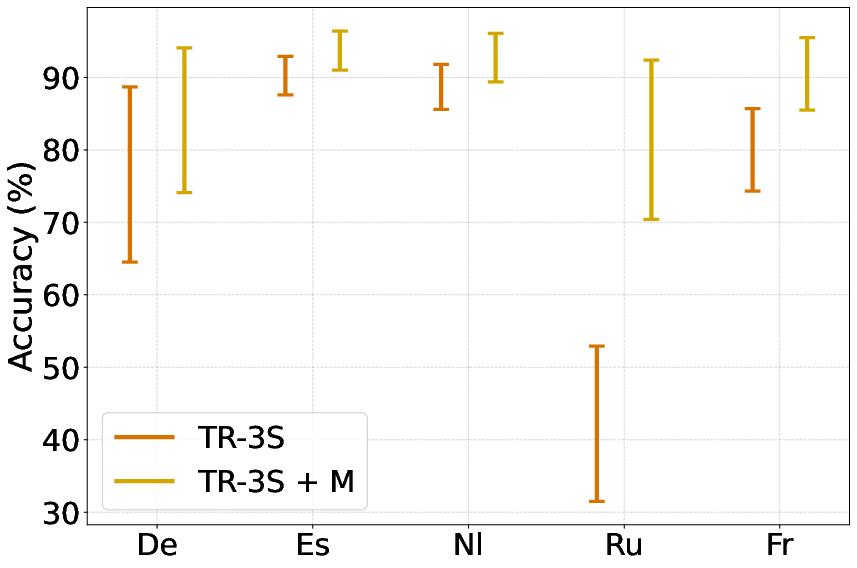
Figure 3: Interval Plot contrasting LF (upper bars) vs. LF+ (lower bars) across languages of our best-performing models.
Conclusion
The integration of multilingual text during visual instruction is a scalable and effective strategy to mitigate IFL in VLMs. These findings pave the way for more inclusive AI applications, though optimizations around model merging and data distribution are crucial for sustained performance enhancements.
Future Work
Future research should explore broader non-European language integrations, fine-tuned balancing in model merging, and improvements in language coverage. This ensures VLMs become usable across diverse linguistic landscapes, bridging the current limitations observed in language calls during evaluation.
This study underscores the promise of multilingual textual regularization, offering potential pathways for VLMs to navigate and interact seamlessly with a linguistically diverse global audience. Additional attention to data fidelity and cultural nuance will further enhance these outcomes.

