- The paper introduces the Surgical Action Planning (SAP) task, using LLM-SAP to generate forward-looking action sequences from surgical video history.
- The framework employs a Near-History Focus Memory Module with both direct and indirect visual observations, effectively capturing context from recent surgical actions.
- Experimental results show that the indirect visual observation approach and supervised fine-tuning significantly improve action prediction accuracy on the CholecT50-SAP dataset.
Surgical Action Planning with LLMs
Introduction
The paper aims to address the challenges in robot-assisted minimally invasive surgery (RMIS) by introducing the Surgical Action Planning (SAP) task. Unlike existing intelligent systems that focus on retrospective analysis, SAP aims to generate future action sequences based on visual inputs, which can potentially aid in intraoperative guidance and procedural automation.
LLMs offer promising capabilities for advancing SAP by leveraging their reasoning abilities to construct coherent action plans from unstructured data, such as surgical video content. The authors propose a framework, LLM-SAP, which includes innovative components to handle predictive decision-making challenges in surgery, a domain previously underexplored.
Methodology
Surgical Action Planning Task Definition
In SAP, the model's objective is to generate an action plan A={a1,…,at} from a visual history H and a user-defined goal G. This involves leveraging a sequence of video clips H and a natural language description goal G. Each action in the plan is a categorical label from a predefined set.
LLM-SAP Architecture
The proposed LLM-SAP framework operates by decomposing complex procedures into action chains using advanced LLMs. It comes in two versions: a text-based LLM model and a Vision LLM (VLM)-based model. These versions differ in their approach to utilizing visual history, highlighted by different data flows within the architecture.
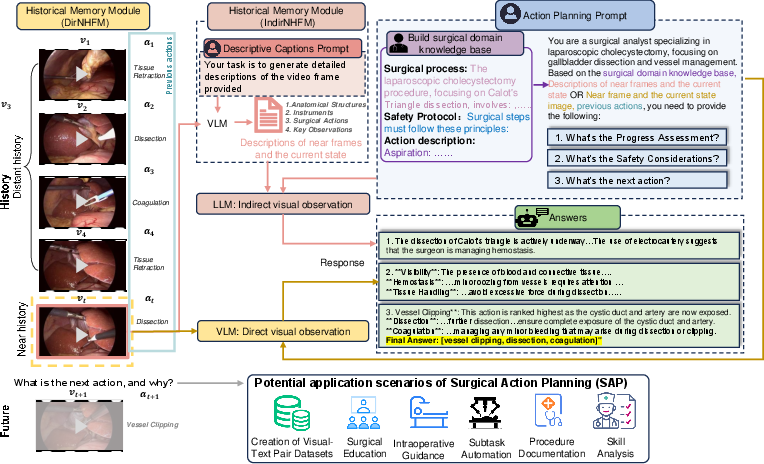
Figure 1: The architecture of our LLM-SAP, highlighting the data flows for text-based and visual-based planning models.
Key Components
Near-History Focus Memory Module (NHFM): This module models historical states by emphasizing recent actions while abstracting distant history, thus avoiding performance degradation due to overwhelming historical data. It comprises two variations:
- Direct Visual Observation (DirNHFM): Uses video frames to create a detailed history.
- Indirect Visual Observation (IndirNHFM): Captures historical context via VLM-generated descriptive captions when LLMs that do not support visual inputs directly are used.
Prompts Factory: This component generates captions and prompts necessary for action planning. Detailed descriptive prompts guide the VLM in generating captions, while action-planning prompts engage with the domain's knowledge base to effectuate progress assessments, safety considerations, and action recommendations.
Zero-Shot and Supervised Fine-Tuning (SFT): The framework supports both zero-shot inference from pre-trained models and more refined task-customization through SFT, addressing the challenges of data privacy and resource limitations.
Dataset and Evaluation
The CholecT50-SAP dataset, derived from the CholecT50 dataset, serves as the evaluation bedrock. It is designed to test surgical action planning abilities with selected segments from surgical procedures.
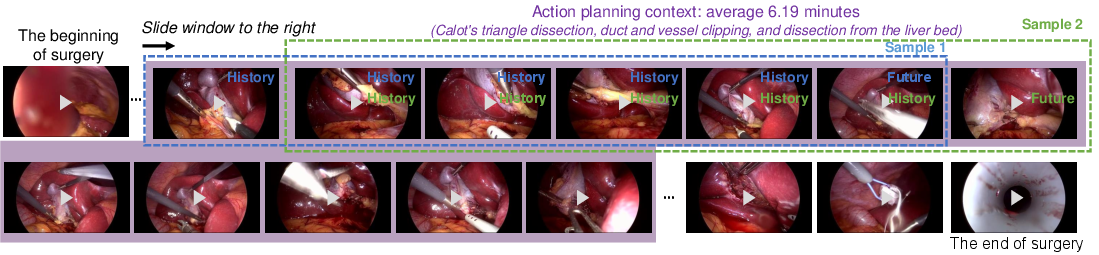
Figure 2: Example of the CholecT50-SAP dataset we constructed.
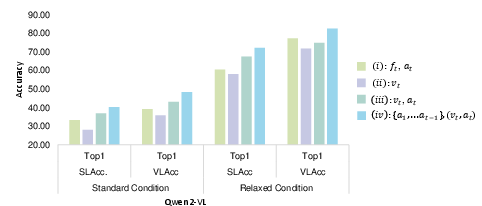
Metrics: The evaluation employs metrics like Sample-Level Accuracy (SLAcc), Video-Level Accuracy (VLAcc), and an additional metric, Relaxed Accuracy (ReAcc), that accommodates the inherent adaptability of surgical processes by allowing forecast actions within an immediate subsequent step.
Experimental Results
The experiments showcase the performance of various LLMs and VLMs in SAP tasks under zero-shot and fine-tuning settings. Notably, the IndirNHFM consistently outperforms the Direct Visual counterpart in both standard and relaxed conditions.
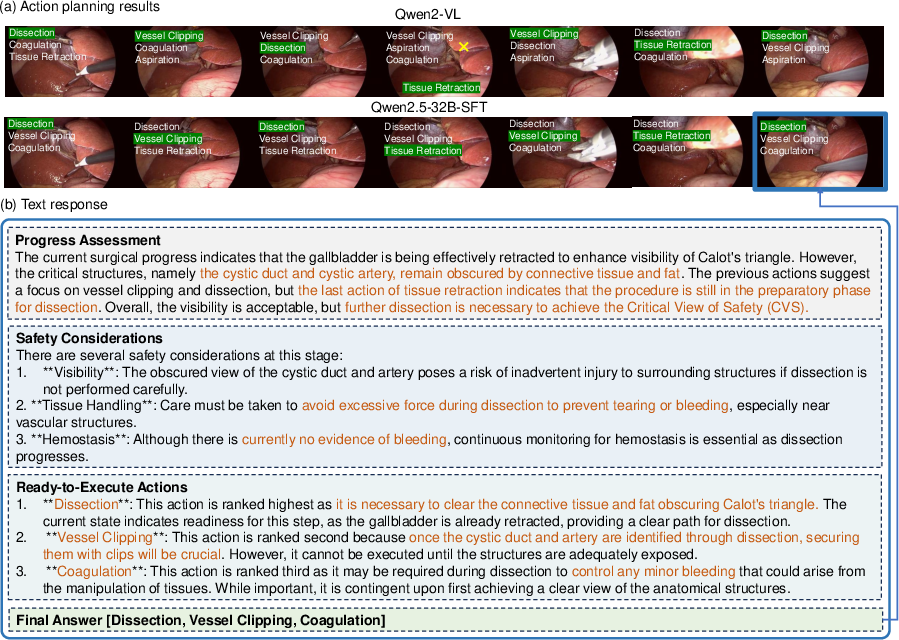
Figure 3: (a) Action planning results visualization. White text displays the planning results, showing the Top 3 future action predictions in order.
Key Findings:
Conclusion
The research presents an innovative approach to SAP using LLMs, with implications for enhancing intraoperative decision-making and automation in RMIS. By integrating the NHF-MM and a prompts factory, the framework efficiently anticipates surgical actions and addresses privacy challenges through fine-tuning.
Future inquiries could enhance the framework's reasoning capabilities, allowing it to incorporate prior steps' text responses into subsequent planning while broadening its procedural and robotic integration scope.