Starjob: Dataset for LLM-Driven Job Shop Scheduling
Published 26 Feb 2025 in cs.LG and cs.AI | (2503.01877v2)
Abstract: LLMs have shown remarkable capabilities across various domains, but their potential for solving combinatorial optimization problems remains largely unexplored. In this paper, we investigate the applicability of LLMs to the Job Shop Scheduling Problem (JSSP), a classic challenge in combinatorial optimization that requires efficient job allocation to machines to minimize makespan. To this end, we introduce Starjob, the first supervised dataset for JSSP, comprising 130k instances specifically designed for training LLMs. Leveraging this dataset, we fine-tune the LLaMA 8B 4-bit quantized model with the LoRA method to develop an end-to-end scheduling approach. Our evaluation on standard benchmarks demonstrates that the proposed LLM-based method not only surpasses traditional Priority Dispatching Rules (PDRs) but also achieves notable improvements over state-of-the-art neural approaches like L2D, with an average improvement of 15.36% on DMU and 7.85% on Taillard benchmarks. These results highlight the untapped potential of LLMs in tackling combinatorial optimization problems, paving the way for future advancements in this area.
The paper introduces the Starjob dataset, a novel natural language representation of job shop scheduling tasks designed for fine-tuning LLMs.
The paper employs Rank-Stabilized LoRA on a quantized LLaMA model, achieving improvements of 15.36% on DMU and 7.85% on Tai benchmarks over traditional methods.
The paper demonstrates that integrating LLMs with natural language encodings can enhance solving NP-hard combinatorial optimization problems like job shop scheduling.
Starjob: Dataset for LLM-Driven Job Shop Scheduling
The paper "Starjob: Dataset for LLM-Driven Job Shop Scheduling" presents a novel dataset specifically designed to leverage LLMs in solving the Job Shop Scheduling Problem (JSSP). JSSP is a classic NP-hard combinatorial optimization problem that involves allocating jobs with varying processing times to machines in a manner that minimizes makespan. This study introduces a unique dataset, Starjob, and demonstrates the effectiveness of fine-tuned LLMs on this problem, offering new insights into their applicability in combinatorial optimization.
Introduction and Motivation
The traditional perception of LLMs' capabilities has been largely limited to natural language processing tasks, with their application to computationally demanding combinatorial optimization problems such as JSSP being underexplored. JSSP involves assigning NJ jobs across NM machines, optimizing for metrics like makespan Cmax. Existing methods often rely on mathematical programming, heuristic techniques, and recent AI approaches like reinforcement learning and graph neural networks. However, these methods struggle with scalability and complex constraints.
The authors aim to challenge these limitations by fine-tuning LLMs for JSSP using the newly introduced Starjob dataset. By leveraging LLMs' unique capacity for reasoning over natural language descriptions, the paper proposes an innovative approach to solving JSSP.
Dataset Overview
Starjob comprises 130,000 instances specifically crafted for training LLMs on JSSP. The dataset includes problem instances represented in natural language rather than the traditional matrix format, allowing LLMs to directly process job sequences and machine allocations. Accompanying each problem instance is a feasible solution, generated using Google's OR-Tools, formatted to facilitate computation over complex scheduling constraints.
The transformation from matrix-based representations to natural language encodings involves detailing job-machine-duration sequences, offering a job-centric perspective on scheduling challenges. This novel representation aids data-driven models in learning effective scheduling rules.
Methodology
The methodology section details the fine-tuning of LLaMA 8B, a 4-bit quantized LLM, on the Starjob dataset using Rank-Stabilized Low-Rank Adaptation (RsLoRA). RsLoRA enhances the stability of fine-tuning by maintaining well-conditioned outputs through a scaling factor γr=rα. This method prevents gradient collapse, ensuring effective learning even at higher ranks.
Proposed Solution Framework:
Fine-Tuning: Train LLM with problem-solution pairs.
Inference: Generate and examine S candidate solutions.
Optimization: Select the minimum makespan solution.
Evaluation and Results
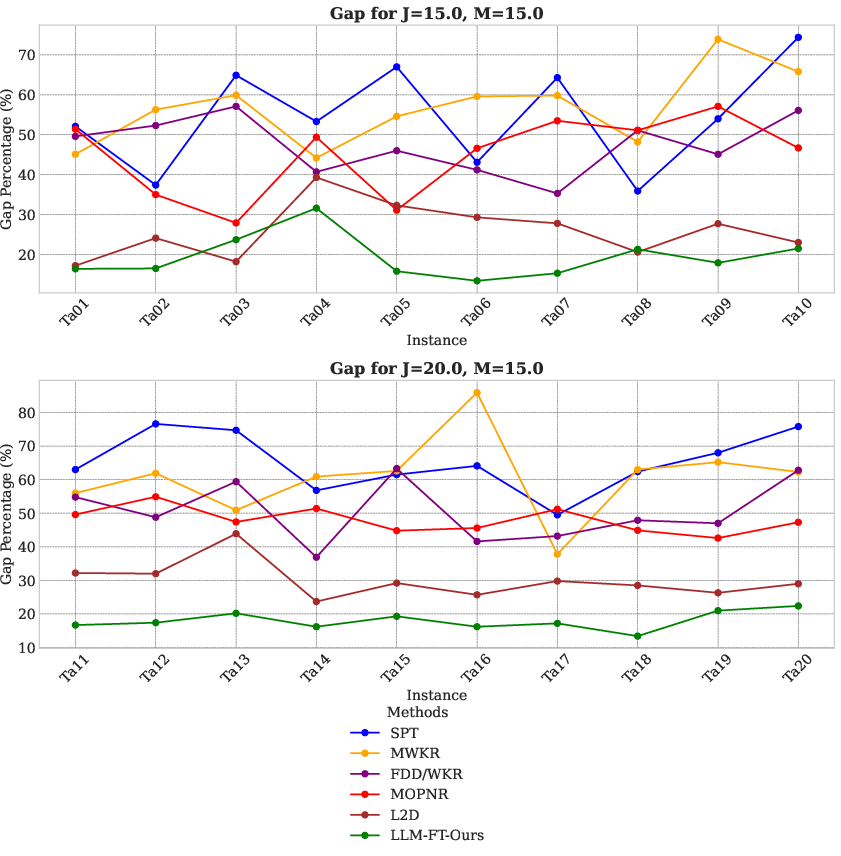
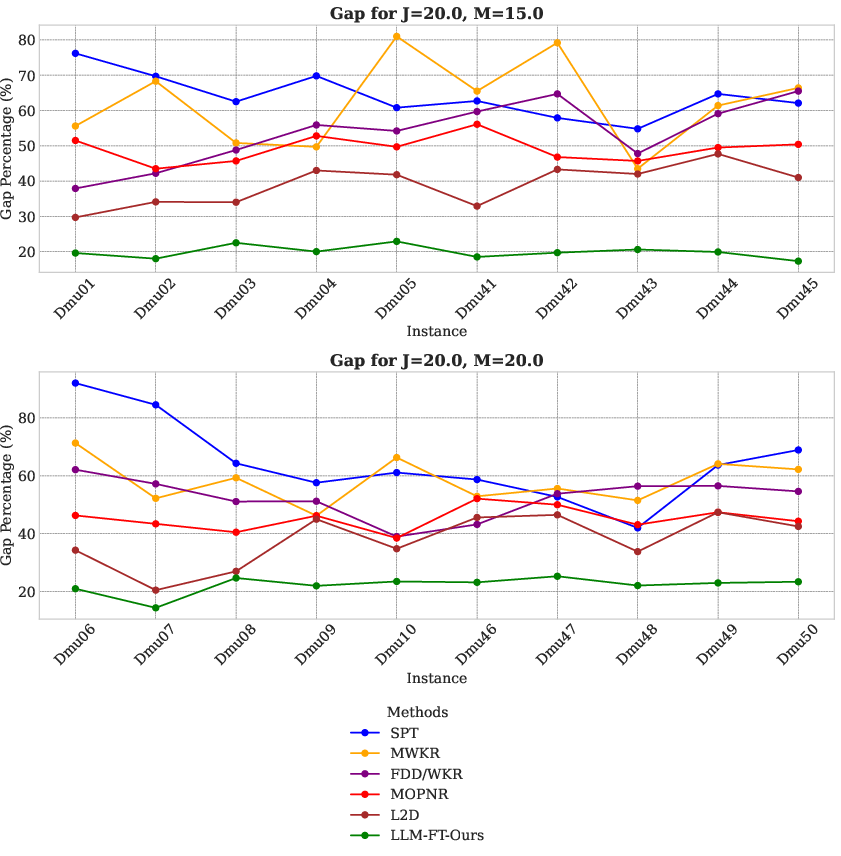
Evaluation employs two benchmarks, Tai and DMU, comparing the fine-tuned LLM against established methods like traditional Priority Dispatching Rules (PDRs) and neural techniques such as L2D. On benchmarks featuring large-scale JSSP instances (e.g., 1000 nodes), the fine-tuned LLM exceeds baseline methods with average improvements of 15.36% on DMU and 7.85% on Tai benchmarks.
Figure 1: Comparison of different methods on TAI\cite{taillard1993benchmarks} benchmark.
The results assert the superior performance and generalization capabilities of the LLM-based approach over existing heuristics and neural solutions, highlighting their potential use in complex scheduling scenarios.
Figure 2: Comparison of different methods on DMU\cite{dmu_dataset} benchmark.
Conclusion
The introduction of the Starjob dataset and the demonstrable success of fine-tuned LLMs on JSSP highlight the untapped potential of LLMs in tackling NP-hard combinatorial optimization problems. By framing JSSP within the context of natural language processing, this study not only extends the application domain of LLMs but also invites future work to explore integrated solutions with reinforcement learning and GNNs for enhanced scheduling efficiency.
Future Directions
Future research could involve expanding the application of LLMs to other scheduling problems, integrating with DRL and GNN approaches for even more robust performance. By further exploring LLMs' aptitude in optimization tasks, this study sets the stage for a broader computational paradigm in solving complex scheduling issues.
References
While the references section of the original document lists detailed works cited throughout the study, the authors' contribution is primarily grounded on leveraging previous frameworks in LLMs, OR-Tools for feasible solution generation, and comparative analyses based on established benchmark datasets.
“Emergent Mind helps me see which AI papers have caught fire online.”
Philip
Creator, AI Explained on YouTube
Sign up for free to explore the frontiers of research
Discover trending papers, chat with arXiv, and track the latest research shaping the future of science and technology.Discover trending papers, chat with arXiv, and more.