- The paper presents OPT-BENCH, a comprehensive benchmark assessing LLMs’ iterative refinement using historical feedback across 20 ML and 10 NP tasks.
- It details the OPT-Agent framework that mimics human problem solving by drafting, debugging, and improving solutions with varied temperature and draft settings.
- Experimental results reveal that incorporating historical context enhances performance, with optimal iteration and temperature settings critical for convergence and stability.
OPT-BENCH: Evaluating LLM Optimization in Large Search Spaces
This paper introduces OPT-BENCH, a benchmark designed to evaluate LLMs in large-scale search space optimization problems, and OPT-Agent, a framework for iterative solution refinement. The benchmark includes a diverse set of 30 tasks, comprising 20 machine learning challenges sourced from Kaggle and 10 classical NP-complete problems, which assesses the ability of LLMs to iteratively refine solutions based on historical feedback. The paper presents a comprehensive evaluation of nine LLMs from six model families, analyzing the impact of optimization iterations, temperature settings, and model architectures on solution quality and convergence.
OPT-BENCH Dataset and Agent Workflow
OPT-BENCH is composed of 20 machine learning tasks from Kaggle competitions and 10 NP-complete problems. The machine learning tasks cover regression, classification, and error prediction, while the NP problems encompass combinatorial optimization and graph theory, including graph coloring, the Hamiltonian cycle, and the knapsack problem. The dataset includes task descriptions, dataset specifications, submission formats, initial solutions, and evaluation metrics.
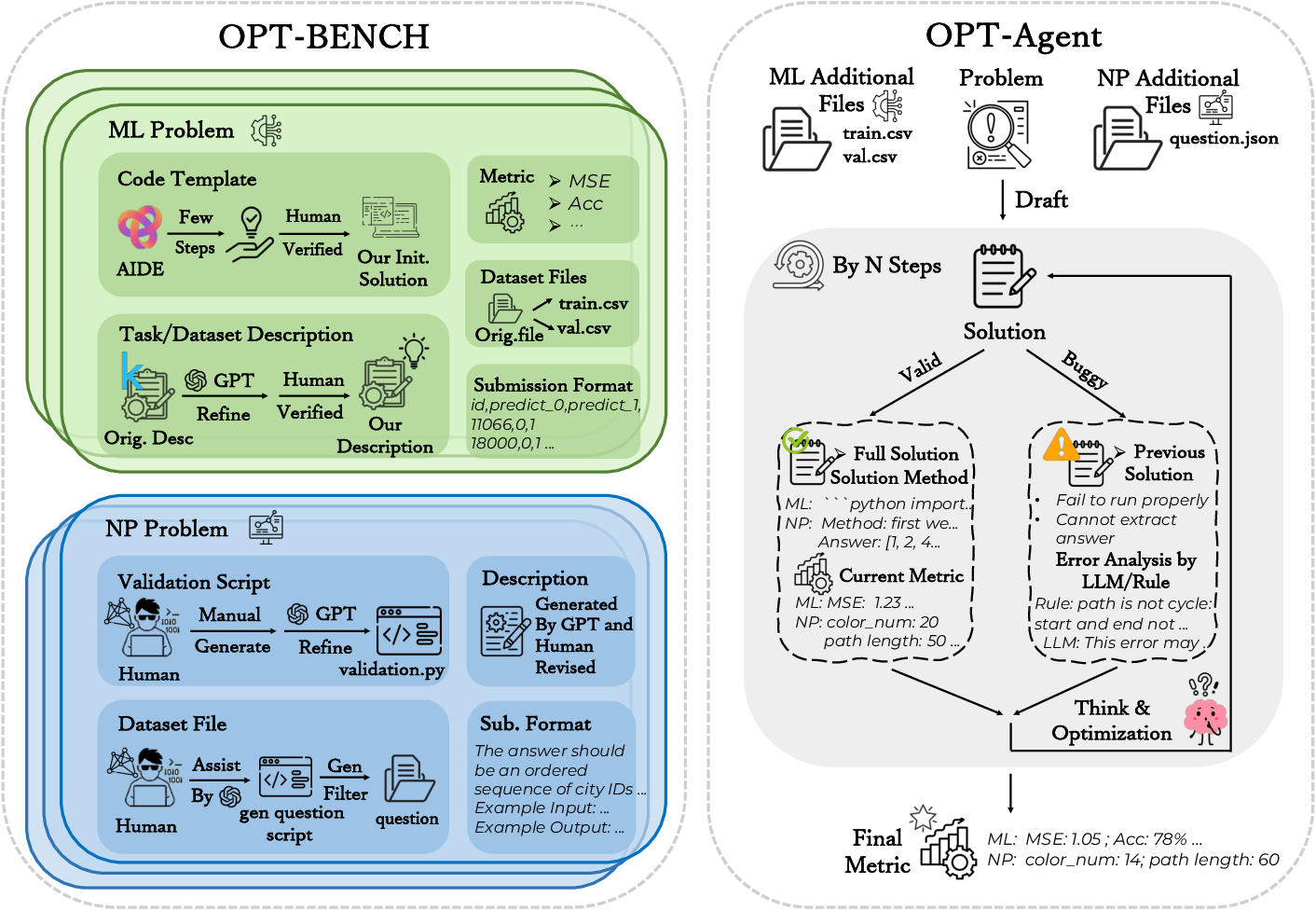
Figure 1: A high-level view of the OPT-BENCH framework and dataset, demonstrating the integration of ML and NP problems with iterative solution validation and optimization.
OPT-Agent is designed as an LLM-driven system that mimics human problem-solving strategies, beginning with an initial solution and iteratively refining it based on feedback. OPT-Agent performs three core actions: drafting, improving, and debugging. The drafting action generates an initial solution, the improving action optimizes valid solutions, and the debugging action corrects erroneous solutions. Historical information from previous solutions is leveraged to guide the optimization process.
Experiments and Results on OPT-BENCH
The experimental setup involves evaluating LLM performance on machine learning and NP tasks using metrics such as Win Count, Buggy Rate, Rank, and Improvement Rate (IR). Win Count assesses the impact of historical information, Buggy Rate measures the proportion of invalid solutions, Rank compares model performance, and IR quantifies the optimization capability of LLMs.
Experiments were conducted to assess the impact of historical information on LLM optimization, comparing OPT-Agent with and without historical context across optimization steps ranging from 5 to 20. Results indicate that incorporating historical information consistently improves optimization performance, with longer optimization horizons generally leading to better performance. However, some models exhibit diminishing returns with increasing steps, suggesting limitations in utilizing long context information. Models generally perform better on NP problems when historical information is included, with reduced Buggy Rates demonstrating the benefit of leveraging error messages for iterative correction.
Ablation Studies: Temperature and Draft Settings
Ablation studies were conducted to assess the effects of temperature and draft settings on LLM performance. The optimal temperature varies across models; lower temperatures enhance stability and consistency in optimization for some models, while higher temperatures lead to a decline in win counts and improvement metrics for others. Decoding temperature affects solution validity differently in NP problems, with moderate temperatures providing an optimal balance between solution validity and search diversity.
Unlike the refine setting, the draft setting requires models to generate solutions from scratch. Results show that open-source models consistently exhibit higher buggy rates, reflecting greater difficulty in producing valid solutions during draft optimization. However, all models achieve higher improvement rates than in the refine setting, indicating that draft optimization can outperform traditional refinement when valid solutions are found.
OPT-Agent leverages historical feedback to optimize the reasoning trace, guiding improvements in hyperparameters, regularization, learning rates, model structure, and feature engineering for ML tasks, and informing solution refinement and debugging for NP tasks. However, historical information is less effective for NP tasks compared to ML tasks, primarily because LLMs struggle to interpret and apply feedback incrementally in NP problems. In contrast, ML tasks benefit from more continuous and coherent reasoning, making historical feedback more valuable.
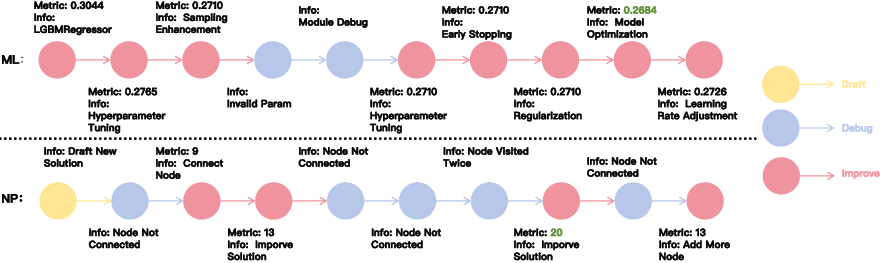
Figure 2: An overview of the OPT-Agent framework, illustrating the iterative process of drafting, debugging, and improving solutions for both ML and NP tasks.
Limitations and Future Work
The evaluation of LLMs on ML optimization tasks is challenged by the growing in-context prompt size, as accumulated code and historical data expand the context window, raising evaluation costs and nearing token limits. Future work will focus on methods to reduce the context window size. Additionally, since OPT-BENCH-ML encompasses diverse Kaggle competitions across various domains, averaging performance metrics may introduce scale inconsistencies.
Conclusion
The paper introduces OPT-BENCH, a benchmark comprising 20 machine learning tasks and 10 NP problems, and OPT-Agent, a framework that simulates human reasoning behavior. Experiments on nine LLMs demonstrate that leveraging historical context consistently enhances performance across ML and NP tasks, with iteration steps and temperature critically influencing convergence and stability.

