- The paper introduces RELIC, a novel framework that evaluates LLMs’ compositional instruction-following by testing their ability to recognize languages from context-free grammars.
- It employs stochastic grammar generation and balanced positive/negative sampling to create synthetic tasks with varying complexity, revealing model accuracy trends and biases.
- Results show that as task complexity increases, LLMs shift from rule-based to heuristic strategies, underlining current limitations in handling complex reasoning.
RELIC: Evaluating Compositional Instruction Following via Language Recognition
The paper introduces the Recognition of Languages In-Context (RELIC) framework, designed to evaluate the compositional instruction-following capabilities of LLMs using language recognition. This framework addresses the limitations of existing benchmarks by providing a method to generate synthetic tasks of varying complexity, mitigating data contamination and benchmark saturation. The core idea behind RELIC is to assess whether a model can determine if a given string is derivable from a context-free grammar (CFG) provided in context. (Figure 1)
Figure 1: RELIC is an evaluation framework for compositional instruction following, where we (a)~stochastically generate context-free grammars (e.g., sets of instructions) of given complexities, (b)~sample positive and negative strings (e.g., tasks) for each grammar, and (c)~prompt models to classify whether the strings are generated by those grammars.
Methodology and Implementation
The {RELIC} framework involves stochastically generating CFGs parameterized by the number of terminal symbols (nt), non-terminal symbols (nn), lexical production rules (nlex), and non-lexical production rules (nnonlex). The production rules are of the form A→BC and A→t, where A, B, and C are non-terminal symbols, and t is a terminal symbol. Positive strings are sampled from the generated grammar, while negative strings are sampled from the vocabulary Σ+ and filtered to exclude strings parseable by the grammar. The difficulty of the task is modulated by varying the size of the grammar and the length of the strings. A static benchmark, {RELIC}-500, is released, consisting of 200 grammars and associated positive and negative examples. The implementation details include methods for grammar generation, string sampling, and ensuring minimal correlation between grammar parameters.
Experimental Setup
The authors evaluated eight LLMs on {RELIC}-500, including OpenAI's [gpt-4.1-nano](https://www.emergentmind.com/topics/gpt-4-1-nano), gpt-4.1-mini, gpt-4.1, o4-mini, o3, Google's Gemma~3 family (gemma-3-1b-it, gemma-3-4b-it) and DeepSeek-R1-Distill-Qwen-7B. The models were prompted with a description of the language recognition task, the grammar, and the string, and were asked to classify the string as either generated or not generated by the grammar. Regular expressions were used to extract the model's classification. The evaluation focused on class-balanced accuracy and macro F1 score to account for biases towards predicting one class over another.
Results and Analysis
The results indicate that the performance of all models decreases as the complexity of the grammar and the length of the example strings increase. (Figure 2) The number of non-lexical productions (nnonlex) is strongly anti-correlated with performance, and a roughly log-linear relationship is observed between nnonlex and accuracy.
(Figure 3) Model accuracy also varies significantly between positive and negative examples, indicating a bias towards one of the two classes, and this bias changes with sequence length. Spearman's rank correlation coefficients reveal that models generally agree on which grammars and examples are hard, although gpt-4.1-nano and gpt-4.1-mini show less correlation with other models.
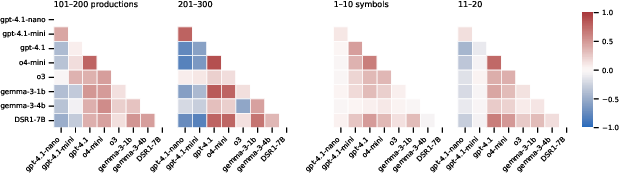
Figure 4: Spearman's rank correlation coefficients for the mean accuracy per grammar (left) and per example (right) between different models, binned by complexity. Models generally agree on which grammars and examples are hard, though gpt-4.1-nano/mini tend to disagree with other models. The strengths of these correlations increases modestly as grammar and example complexity grow.
Qualitative analysis of the chain-of-thought tokens shows that models often identify the correct strategy (constructing a parse tree) but fail to execute it to completion, resorting to heuristics or getting distracted by irrelevant information.
Model Strategies and Test-Time Compute
A quantitative analysis of model strategies, using o4-mini as a judge, reveals that models switch from rule-based to heuristic strategies as example complexity increases. (Figure 5)
Figure 5: As task complexity (example length) increases, the test-time compute (TTC) expended by models peaks early and then diminishes (top row; TTC is computed as the mean number of completion tokens produced for examples of a given length, relative to the length for which the mean number of tokens is highest; see \ref{fig:ttc for absolute TTC). As relative TTC stops increasing, models shift from pursuing rule-based approaches to relying on heuristic strategies (bottom row; this analysis is based on o4-mini's classification, which may underestimate the number of rule-based strategies). o4-mini and o3 do not provide full CoTs, so we cannot classify these models' strategies.
Test-time compute (TTC), measured by the number of intermediate chain-of-thought tokens, does not scale as expected with the length of the string. Instead, TTC peaks early and then diminishes, coinciding with the shift from rule-based to heuristic strategies.
Theoretical Implications and Discussion
The {RELIC} framework offers several strengths, including robustness to contamination and saturation due to its generative nature. It also evaluates sophisticated context use, requiring LLMs to apply a large number of production rules densely distributed within the context window. The task's theoretical difficulty aligns with the complexity classes AC1 and NC1-hard, suggesting that fixed-depth transformers cannot solve the in-context recognition task for general CFGs without using chain of thought. The authors discuss limitations, such as the method for generating negative examples, and suggest future work involving more adversarial negative sampling methods and extensions of the {RELIC} task.
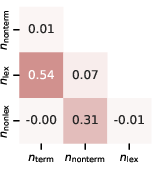
Figure 6: Correlations between generating hyperparameters for the released static set. Note that n_ and n_ are inherently correlated (see \cref{sec:term_lex_correlations for discussion).
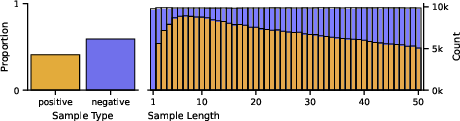
Figure 7: Proportions of example types represented in the static dataset, in aggregate (left) and broken down by example length (right).
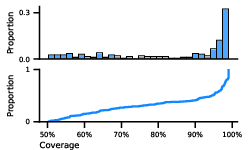
Figure 8: Distribution of grammars by coverage (i.e., the size of the language they generate, measured as the number of positive examples of lengths ell \leq 50, with a maximum of \num{10 examples/length, out of a theoretical maximum of \num{500}) shown as a histogram (top) and a cumulative distribution function (bottom).

Figure 9: Spearman's rank correlation coefficients for the per-example accuracies between different models, faceted by example length. On short examples of length leq 10, all models are moderately correlated with one another; on longer examples, gpt-4.1-nano and gpt-4.1.mini become less correlated with the other models.
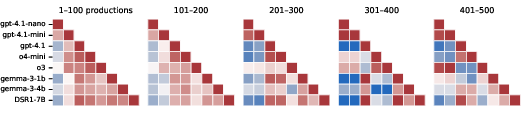
Figure 10: Spearman's rank correlation coefficients for the per-example accuracies between different models, faceted by example length. On short examples of length leq 10, all models are moderately correlated with one another; on longer examples, gpt-4.1-nano and gpt-4.1.mini become less correlated with the other models.
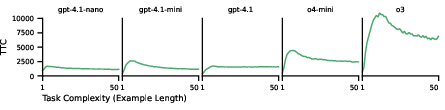
Figure 11: Absolute test-time-compute expended by models as a function of example length.
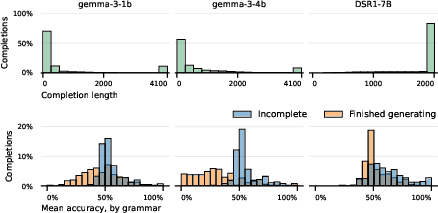
Figure 12: (top row) Among open-weights models, the Gemma 3 variants mostly generated completions well below the new token limit, while DSR1 routinely failed to finish completions within bounds. (bottom row) Within each grammar, models have a lower accuracy on finished completions than they do on incomplete generations.
Conclusion
The {RELIC} framework provides a valuable tool for evaluating and diagnosing the compositional instruction-following abilities of LLMs. The finding that models switch to heuristic strategies as task complexity increases highlights the limitations of current LLMs in performing complex reasoning tasks. The framework's generative nature and controllable complexity make it a promising approach for future evaluations as LLMs continue to improve.