Designing Parameter and Compute Efficient Diffusion Transformers using Distillation
Abstract: Diffusion Transformers (DiTs) with billions of model parameters form the backbone of popular image and video generation models like DALL.E, Stable-Diffusion and SORA. Though these models are necessary in many low-latency applications like Augmented/Virtual Reality, they cannot be deployed on resource-constrained Edge devices (like Apple Vision Pro or Meta Ray-Ban glasses) due to their huge computational complexity. To overcome this, we turn to knowledge distillation and perform a thorough design-space exploration to achieve the best DiT for a given parameter size. In particular, we provide principles for how to choose design knobs such as depth, width, attention heads and distillation setup for a DiT. During the process, a three-way trade-off emerges between model performance, size and speed that is crucial for Edge implementation of diffusion. We also propose two distillation approaches - Teaching Assistant (TA) method and Multi-In-One (MI1) method - to perform feature distillation in the DiT context. Unlike existing solutions, we demonstrate and benchmark the efficacy of our approaches on practical Edge devices such as NVIDIA Jetson Orin Nano.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about making powerful image-generating AI models smaller and faster so they can run on tiny devices like smart glasses or VR headsets. These models are called Diffusion Transformers (DiTs). They usually need huge computers because they have billions of parts (parameters) and do a lot of math. The authors explore how to shrink these models down to just a few million parts while keeping the image quality good and the speed high. They also test their ideas on real hardware used at the edge, not just in big data centers.
What questions did the paper ask?
In simple terms, the paper asks:
- How can we design a small Diffusion Transformer that still makes good images and runs fast on small devices?
- Which design choices matter most: how many layers the model has (depth), how wide each layer is (width), and how many attention heads it uses?
- Can special training tricks, like learning from a bigger “teacher” model (distillation), make small models better?
- What’s the best balance between image quality, model size, and speed for edge devices?
How did they do it?
To explain the approach, here are the key ideas in everyday language:
- What is a diffusion model?
- Imagine starting with a super noisy picture and trying to clean it step by step until a clear image appears. That’s what diffusion models do: they learn how to turn noise into a realistic image. Doing it in many steps can make great images but takes time.
- What is a Diffusion Transformer (DiT)?
- It’s a version of a diffusion model that uses the transformer architecture (the same kind of tech used in chatbots). Transformers are powerful but can be heavy.
- What is knowledge distillation?
- Think of a big, smart model as a teacher and a small model as a student. The student watches the teacher’s answers and learns to copy them. The goal is to keep most of the teacher’s skill in a much smaller brain.
- What design “knobs” did they test?
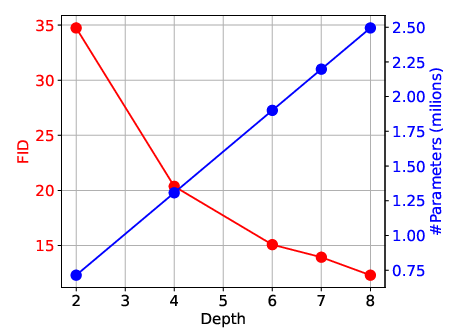
- Depth: how many layers (like the number of steps in a recipe).
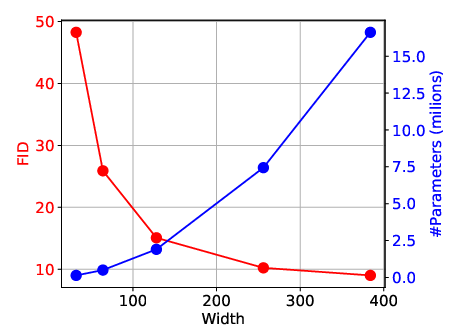
- Width: how big each layer is (like the size of a team working on each step).
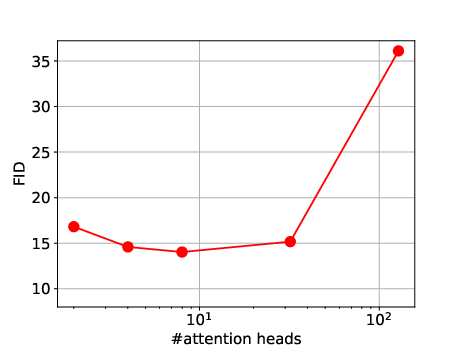
- Attention heads: how many different “spotlights” the model uses to look at the picture in parallel.
- Distillation setup: which training targets and loss functions to use when learning from the teacher.
- Two extra training ideas they tried:
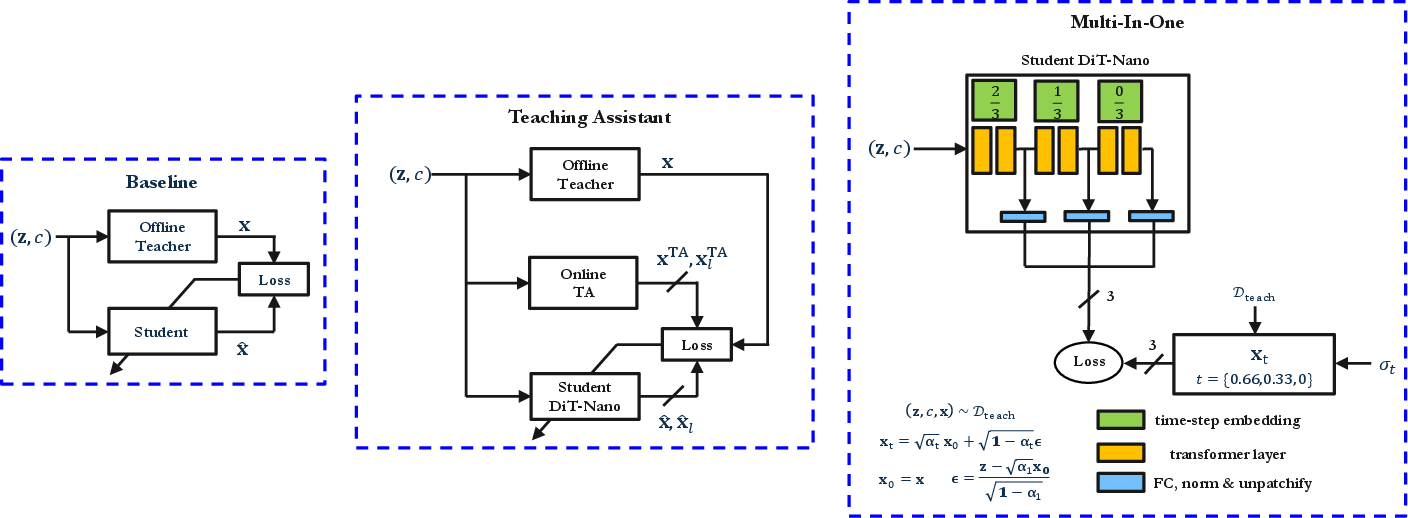
- Teaching Assistant (TA): Add a smaller helper teacher between the big teacher and the tiny student to make learning easier.
- Multi-In-One (MI1): Try to squeeze several diffusion steps into a single pass by telling certain layers to match what would happen at specific steps of the diffusion process. Think of it like practicing checkpoints of a long task inside one sprint.
- How did they measure success?
- Image quality: FID (Fréchet Inception Distance). Lower is better.
- Speed: latency, the time to generate images.
- Size: number of parameters (memory footprint).
- They tested on CIFAR-10 (a small image dataset) and measured real speeds on an NVIDIA Jetson Orin Nano, a popular edge device.
- A helpful detail about the loss function:
- They found that using LPIPS (a “perceptual” image similarity score—closer to how humans judge images) for training the student works much better than simple pixel-by-pixel differences.
What did they find, and why does it matter?
Here are the main takeaways and why they’re important:
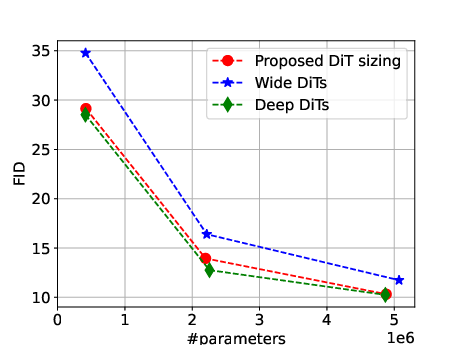
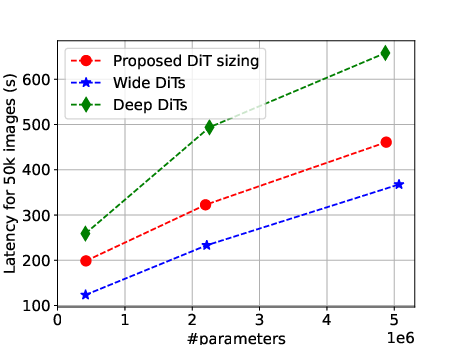
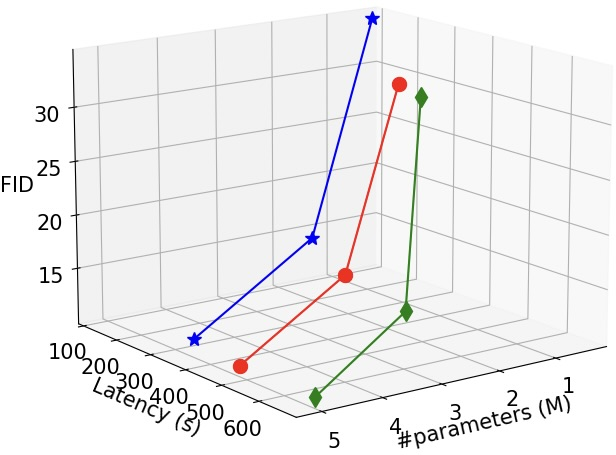
- There’s a three-way trade-off between quality, size, and speed.
- You can’t maximize all three at once. If you make the model too deep (many layers), it can get slow. If you make it too wide (large layers), it gets big and memory-hungry. You want a sweet spot that runs fast, fits on the device, and still makes nice images.
- Simple design principles that work well:
- Use LPIPS as the training loss when distilling diffusion models.
- Balance depth and width instead of cranking only one. Going only deeper or only wider gives “diminishing returns.”
- For the number of attention heads, pick a middle-ground value based on the width (a “sweet spot” rather than the smallest or largest possible).
- A practical rule they offer: choose depth roughly like “log base 2 of the width” (this is just a guideline to keep things balanced).
- The “Teaching Assistant” and “Multi-In-One” ideas did not beat their strong baseline.
- TA feature distillation (matching internal layers) didn’t help much. Using only the TA as a teacher gave a tiny improvement but at extra training cost.
- MI1, which tries to map multiple diffusion steps into one pass by guiding specific layers, performed worse than the simpler baseline.
- Sharing these “negative results” is helpful: it saves others from spending time on ideas that may not pay off for tiny models.
- They built competitive tiny models (“DiT-Nano”) with only a few million parameters.
- These models run on real edge hardware and matched or beat a previous state-of-the-art method in overall balance of size, speed, and image quality.
- This is a big deal because it moves high-quality image generation closer to running directly on devices like AR/VR headsets.
Why this is important for the real world
- Better on-device AI: Smaller, faster models mean less dependence on the cloud. That reduces delay, improves privacy, and saves bandwidth—key for AR/VR, smart cameras, and wearables that need quick responses.
- Clear guidelines for builders: The paper offers practical rules of thumb for designing small diffusion transformers. Engineers can use these to make informed trade-offs without trying thousands of combinations.
- Honest reporting helps progress: By showing when fancy tricks don’t help much, the paper encourages the community to focus on what truly improves tiny models.
- A path forward: Future work could extend the design rules to more settings, adjust other parts of the model (like the MLP ratio), or tune attention head counts per layer. The core message remains: balance is better than extremes, and smart training choices (like LPIPS-based distillation) can make small models surprisingly capable.
In short, the paper shows how to shrink big image-generating models into compact versions that still look good and run fast on small devices—and gives practical recipes so others can do the same.
Glossary
- AdamW: A variant of the Adam optimizer that decouples weight decay from the gradient update to improve generalization. Example: "We use AdamW optimizer with weight decay 0.01, a fixed learning rate of 0.0001, and a global batch size of 256."
- Adversarial setups: Training schemes that pit a generator against a discriminator or adversarial objective to improve generation quality or distribution matching. Example: "~\citep{yin2024one, yin2024improved} use adversarial setups and distribution matching losses to perform one-step generation."
- Attention heads: Parallel attention mechanisms within a transformer layer that allow the model to attend to information from different representation subspaces. Example: "When it comes to no. of attention heads (which can only take factors of as values), we find there is a sweet spot in the middle as shown in~\cref{fig: heads v/s FID}."
- cfg-scale: The classifier-free guidance scale, a factor controlling the strength of guidance at inference. Example: "We also employ classifier-free guidance during inference with a cfg-scale of 1.5."
- Classifier-free distillation: A distillation approach that removes the need for a classifier during training, often used to reduce steps while preserving conditional control. Example: "~\citep{meng2023distillation} propose a classifier-free distillation method to generate images using 1-4 timesteps."
- Classifier-free guidance: A guidance technique that conditions generation without an explicit classifier by interpolating between conditional and unconditional predictions. Example: "We also employ classifier-free guidance during inference with a cfg-scale of 1.5."
- Consistency-based distillation: Training methods that enforce consistency of model outputs across different noise levels or trajectories to speed up sampling. Example: "Trajectory and consistency-based distillation~\citep{berthelot2023tract, song2023consistency, zheng2024trajectory} has also been considered to improve the speed of diffusion model generation."
- Design-space exploration: Systematic evaluation of architectural and training choices (e.g., depth, width, losses) to find optimal designs under constraints. Example: "Design-Space Exploration: Among the several design knobs for distilling DiT models, we pick the following most relevant ones - depth, width, number of attention heads of the DiT model, and the setup (loss function and teacher models) for distillation."
- DiT-Nano: The paper’s proposed small, efficient Diffusion Transformer configuration optimized via design principles and distillation. Example: "We provide principles for designing an efficient SOTA (at the given model size) DiT model (DiT-Nano) by employing distillation."
- Diffusion Transformers (DiTs): Transformer-based architectures specifically adapted for diffusion generative modeling. Example: "Diffusion Transformers (DiTs)~\citep{peebles2023scalable} have become the de facto method~\citep{dhariwal2021diffusion} for generating images and videos..."
- DMD: A one-step diffusion distillation approach based on distribution matching; used here as a baseline for comparison. Example: "The simpler training setup of GET provides better results compared to DMD."
- EDM: Elucidated Diffusion Models, a diffusion framework used here as the teacher for distillation. Example: "The results below are shown for CIFAR-10 on DiTs distilled using EDM~\citep{karras2022elucidating} as teacher."
- Edge devices: Resource-constrained hardware platforms intended for on-device inference with strict memory, power, and latency limits. Example: "they cannot be deployed on resource-constrained Edge devices (like Apple Vision Pro or Meta Ray-Ban glasses) due to their huge computational complexity."
- EMA (Exponential Moving Average): A smoothed parameter averaging technique used at inference to improve sample quality and stability. Example: "During inference we use an Exponential Moving Average (EMA) model trained with an EMA decay of 0.9999."
- Embedding dimension: The width of transformer layers, defining the dimensionality of token representations. Example: "width (embedding dimension) affect the FID and no. of parameters."
- FID: Fréchet Inception Distance, a standard metric for evaluating the quality of generated images by comparing feature statistics. Example: "We use FID~\citep{heusel2017gans} as the metric to evaluate the generated image performance while using model size and latency (instead of FLOPs) as the metrics for efficiency."
- FLOPs: Floating Point Operations, a hardware-agnostic proxy for computational cost; contrasted here with measured latency. Example: "We use FID~\citep{heusel2017gans} as the metric to evaluate the generated image performance while using model size and latency (instead of FLOPs) as the metrics for efficiency."
- Forward diffusion: The process of adding noise to data according to a diffusion schedule; here referenced via the probability flow ODE. Example: "We derive below the equations for forward diffusion of the probability flow ODE."
- GET: A specific distillation setup from prior work used as a strong baseline in this paper. Example: "The GET setup with LPIPS loss is the most effective."
- HDiTs: Hourglass Diffusion Transformers, an architectural variant of DiTs with an hourglass structure. Example: "Hourglass DiTs (HDiTs)~\citep{crowson2024scalable}"
- Inception Score (IS): A generation quality metric based on classifier confidence and diversity across generated samples. Example: "IS in~\cref{tab: all params ablation} refers to Inception Score."
- Knowledge distillation: Training a smaller student model to mimic a larger teacher model’s behavior to reduce parameters and computation. Example: "To overcome this, we turn to knowledge distillation and perform a thorough design-space exploration to achieve the best DiT for a given parameter size."
- LPIPS: Learned Perceptual Image Patch Similarity, a perceptual loss measuring image similarity in deep feature space. Example: "We explore the possibility of combined feature distillation (see~\cref{fig: distillation methodology}) using the teacher and TA with LPIPS loss~\citep{zhang2018unreasonable}."
- MI1 (Multi-In-One): A distillation approach that maps multiple diffusion timesteps into a single forward pass by supervising specific layers with different timesteps. Example: "Multi-In-One (MI1) Method: This approach performs multiple diffusion timesteps in a single step by mapping the diffusion samples to specific layers of the student."
- MLP ratio: The expansion ratio of the feed-forward (MLP) sublayer in transformers; a design knob noted for future exploration. Example: "Future directions can include justifying the above guidelines analytically, or expanding the design-space to knobs like MLP ratio and diffusion timesteps..."
- Multi-step diffusion: A sampling process that denoises over several timesteps; contrasted with one-step student generation. Example: "The noise-image pair of the teacher model which does multi-step diffusion is used to calculate the intermediate noisy images..."
- NVIDIA Jetson Orin Nano: An embedded GPU platform used to measure real-world latency of distilled models. Example: "we demonstrate and benchmark the efficacy of our approaches on practical Edge devices such as NVIDIA Jetson Orin Nano."
- Offline distillation: A setup where teacher outputs are precomputed and stored to train the student without an online teacher. Example: "we consider here mainly the scenario of offline distillation (noise-image pairs of teacher are generated before training) due to compute resources."
- Online teacher: Using the teacher model during student training to generate targets on-the-fly. Example: "it is more expensive to have an online teacher model generate samples on the fly."
- Patch-size: The size of image patches tokenized for transformer inputs in vision models. Example: "Patch-size of 2 is used for all models."
- Progressive distillation: A multi-stage method that halves the number of diffusion steps each stage to accelerate sampling. Example: "Progressive distillation~\citep{salimans2022progressive} reduces the number of timesteps by two during each distillation stage, thus incurring a large training cost."
- Probability flow ODE: A continuous-time ODE formulation corresponding to diffusion processes, used here to generate intermediate supervision targets. Example: "The training targets are obtained using forward diffusion of the probability flow ODE."
- Pruning: Removing parameters or structures from a model to reduce size and computation. Example: "Quantization~\citep{chen2024q, wu2024ptq4dit} and pruning~\citep{fang2024tinyfusion} have been proposed for designing parameter-efficient DiTs."
- Quantization: Reducing numerical precision of weights/activations to shrink model size and speed up inference. Example: "Quantization~\citep{chen2024q, wu2024ptq4dit} and pruning~\citep{fang2024tinyfusion} have been proposed for designing parameter-efficient DiTs."
- SiTs: Scalable Interpolant Transformers, a transformer-based diffusion architecture alternative to DiTs. Example: "Scalable Interpolant Transformers (SiTs)~\citep{ma2024sit}"
- SOTA: State-of-the-art; denotes top-performing methods or results. Example: "We provide principles for designing an efficient SOTA (at the given model size) DiT model (DiT-Nano) by employing distillation."
- Teaching Assistant (TA) method: A distillation scheme that uses an intermediate-capacity model to bridge teacher and student via feature or output matching. Example: "Teaching Assistant (TA) Method: This approach is inspired by the original TA paper~\citep{mirzadeh2020improved} for distilling convolutional networks."
- Timesteps: Discrete noise levels in diffusion sampling; a key knob for speed-accuracy trade-offs. Example: "We do not consider timesteps as a design knob despite its importance since extensive studies have been performed on that already~\citep{peebles2023scalable, yin2024improved} (we do 1-step diffusion only)."
- U-Nets: Convolutional architectures with skip connections widely used for diffusion models before transformers. Example: "~\citep{karras2022elucidating} showed comprehensively how convolution-based U-Nets can be adapted to perform diffusion efficiently."
- VP conditional model: A variance-preserving diffusion model conditioned on labels or other inputs, used to generate training pairs. Example: "For training data we use the noise-image pairs generated from EDM~\citep{karras2022elucidating} VP conditional model provided in the GitHub repository of~\citep{geng2024one}."
- Weight decay: L2-regularization applied during optimization to reduce overfitting. Example: "We use AdamW optimizer with weight decay 0.01, a fixed learning rate of 0.0001, and a global batch size of 256."
Collections
Sign up for free to add this paper to one or more collections.

