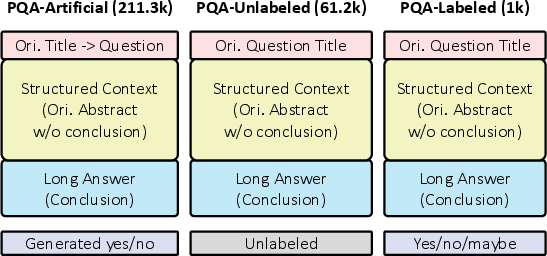
- The paper presents a comprehensive PubMedQA dataset that fills the gap in biomedical question answering by leveraging yes/no/maybe queries from structured abstracts.
- It employs a multi-phase fine-tuning approach with BioBERT using labeled, unlabeled, and artificially generated data to enhance model reasoning over quantitative data.
- The study demonstrates that BioBERT with auxiliary supervision achieves 68.1% accuracy, underscoring both its advancement and the ongoing challenges compared to human performance.
PubMedQA: A Dataset for Biomedical Research Question Answering
The study presents PubMedQA, a dataset specifically designed for biomedical question answering (QA) tasks, which fills a gap in the literature by focusing on yes/no/maybe questions derived from structured abstracts in PubMed. PubMedQA aims to evaluate models' abilities to reason over quantitative biomedical research data.
Dataset Composition and Characteristics
PubMedQA comprises three subsets: PQA-L (labeled), PQA-U (unlabeled), and PQA-A (artificially generated). The dataset's structure ensures a comprehensive representation of biomedical research, enabling sophisticated reasoning over abstract content:
The dataset predominantly features topics on clinical studies, reflected in its MeSH term distribution (Figure 2), including risk assessment and outcome prediction.
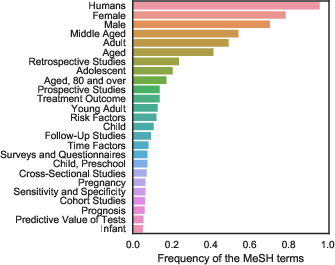
Figure 2: MeSH topic distribution of PubMedQA.
Evaluation Framework and Challenges
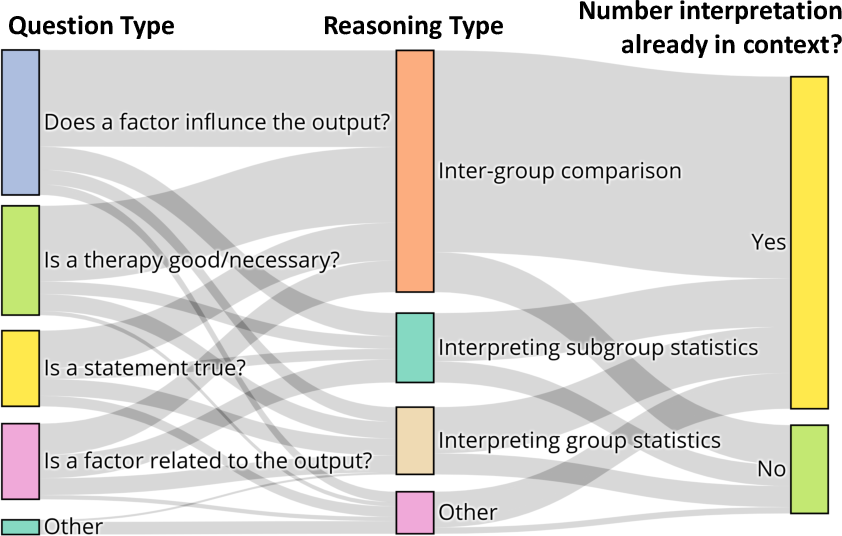
PubMedQA challenges models to engage in quantitative reasoning, reflected in the questionnaire composition and reasoning strategies required (Figure 3). Typical question formats include:
Methodology
The paper presents a multi-phase fine-tuning approach using BioBERT, enhanced by additional supervision via long-answer bag-of-word statistics. This method aims to leverage the unique structure of PubMedQA:
- Phase I: Pre-training on PQA-A using the question-and-context configuration.
- Phase II: Fine-tuning on bootstrapped instances from PQA-U.
- Final Phase: Fine-tuning on PQA-L elements.
This procedure, illustrated in Figure 4, underscores the incremental adaptation process of BioBERT across varying data subsets.
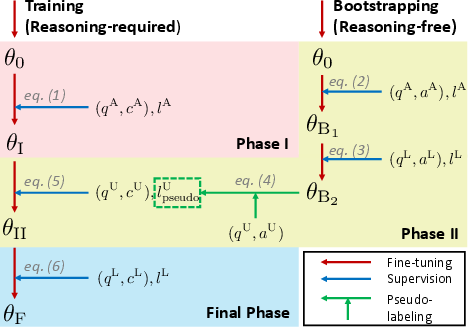
Figure 4: Multi-phase fine-tuning architecture. Notations and equations are described in \S \ref{notation}.
The adoption of BioBERT with additional supervision demonstrates a marked improvement compared to traditional models like ESIM and baseline methods. Despite this enhancement, performance still trails human benchmark levels on reasoning tasks, highlighting ongoing challenges in the domain:
- BioBERT achieves 68.1% accuracy, exceeding traditional methods but below human performance (78%).
- Additional supervision via long-answer statistics enhances model robustness, indicating the importance of auxiliary tasks.
Conclusion and Future Directions
The introduction of PubMedQA represents a significant stride in biomedical NLP, offering an intricate benchmark for evaluating models' capacity to perform reasoning over research abstracts. The paper outlines potential pathways for further exploration:
- Enhanced handling of contexts containing numerical data without explicit interpretations.
- Advanced auxiliary tasks potentially involving full answer generation, which could refine model capabilities in scientific reasoning.
Overall, PubMedQA stands as a comprehensive resource poised to stimulate advancements in AI-mediated biomedical research interpretation, particularly in applications of evidence-based medicine. The dataset's focus on reasoning over abstracts aligns with real-world clinical decision-making processes, reinforcing its relevance and applicability in biomedical AI development.