- The paper introduces a fusion approach combining LLMs with gradient-based reinforcement learning to enhance financial trading, showing superior performance on stocks and cryptocurrencies.
- The method employs a dual network design, where a partially fine-tuned policy network directs trading actions and a value network evaluates returns.
- The experiments demonstrate efficient adaptation and stability, with improved cumulative returns and Sharpe ratios compared to conventional trading strategies.
FLAG-Trader: Fusion LLM-Agent with Gradient-based Reinforcement Learning for Financial Trading
Introduction
"FLAG-Trader" (2502.11433) introduces a fusion approach that integrates LLMs with reinforcement learning (RL) for advancing financial trading systems. Traditional RL models encounter challenges such as inefficiencies in handling multimodal data, non-stationary market conditions, and reliance on manual feature engineering. FLAG-Trader addresses these issues by leveraging the LLMs' robust language processing capabilities alongside RL optimization to enhance decision-making in trading.
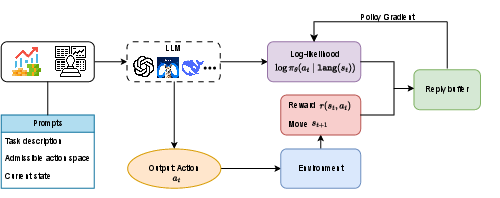
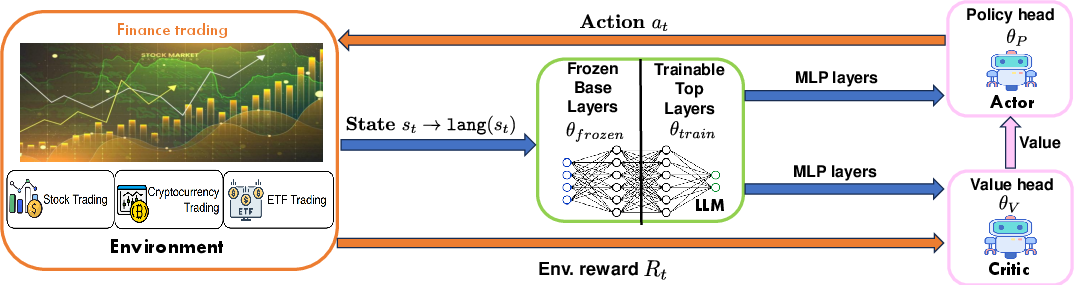
Figure 1: A high-level overview of the LLM-based reinforcement learning setup for financial trading, illustrating the state-action-reward architecture.
FLAG-Trader Architecture
The architecture employs a partially fine-tuned LLM as the policy network, which allows the model to utilize pre-trained knowledge effectively while adapting to financial contexts through gradient-based policy optimization. Only select parameters of the LLM are updated to retain general reasoning capabilities while ensuring computational efficiency.
- Prompt Input Design: Textual state representation is crafted into prompts incorporating market conditions and action frameworks, ensuring the LLM processes and outputs effective trading actions.
- Model Design: The FLAG-Trader uses a dual network structure:
Reinforcement Learning with LLMs
FLAG-Trader applies policy gradient methods to align LLM-based decision-making with trading performance metrics by integrating reward signals into the framework. The system uses Proximal Policy Optimization (PPO) to ensure stable learning and reduced divergence from prior policies.
Online Policy Gradient Learning
- Advantages Estimation: Evaluates policy performance and determines the necessary adjustments through mechanisms like Generalized Advantage Estimation (GAE).
- Loss Function and Parameter Updates: Employs meticulous loss functions for policy and value networks to facilitate robust training, using stochastic gradient descent for parameter updates.

Figure 3: The format of input prompt detailing task description, action space, current state, and output action.
Experiments and Results
FLAG-Trader is tested across multiple financial trading tasks like stocks and cryptocurrencies, where it consistently surpasses conventional trading strategies and LLM-agentic baselines. The experiment metrics such as cumulative return and Sharpe ratio underline enhanced performance, even allowing a small-scale LLM to outperform larger proprietary models.
Key advantages demonstrated include:
- Superior Performance: Consistently surpassing traditional strategies in various metrics.
- Efficient Adaptation: Integrating LLMs with RL fine-tuning allows smaller models to outperform larger counterparts by optimizing decision-making and resource use.
- Stable Policies: The architecture promotes convergence to efficient trading strategies, less reliant on initial prompt biases.
Conclusion
FLAG-Trader offers significant potential for enhancing financial trading systems by integrating LLMs with RL. The structured reinforcement learning approach effectively exploits LLMs for nuanced, adaptive decision-making in volatile markets. Future research directions include optimizing computational efficiency, addressing market non-stationarity, and integrating risk-sensitive constraints to further improve real-world trading applications.
This fusion of LLMs and RL heralds a sophisticated, scalable avenue for achieving robust financial trading systems that align with dynamic market conditions.