- The paper presents a spatio-temporal head with temporal attention layers to achieve consistent depth estimation in super-long videos.
- It introduces a Temporal Gradient Matching loss that monitors depth changes across frames, overcoming limitations of static optical flow methods.
- A novel inference strategy using overlapping frame interpolation and key-frame referencing enhances scaling consistency and reduces model drift.
Video Depth Anything: Consistent Depth Estimation for Super-Long Videos
The article titled "Video Depth Anything: Consistent Depth Estimation for Super-Long Videos" presents a novel approach for enhancing the accuracy and temporal consistency of depth estimation in super-long video sequences. Building upon Depth Anything V2, the proposed method effectively overcomes the limitations of previous approaches in handling videos beyond 10 seconds, offering a unique solution without sacrificing computational efficiency.
Model Architecture
The innovative architecture leverages a spatial-temporal head designed to replace the DPT head from Depth Anything V2, introducing temporal layers that facilitate the exchange of temporal information across frames. The model architecture comprises an encoder derived from Depth Anything V2 and a sophisticated spatio-temporal head.
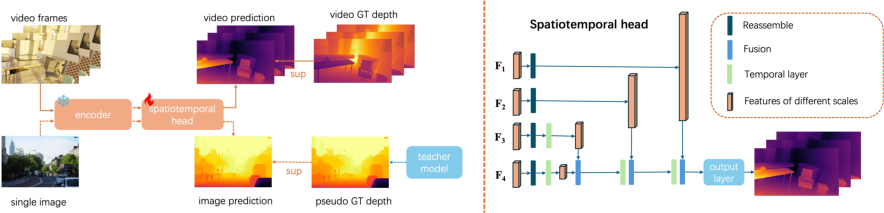
Figure 1: Overall pipeline and the spatio-temporal head. Our model integrates a robust spatial-temporal head for effective temporal data processing.
This head includes four temporal attention layers applied along the temporal dimension to capture temporal dynamics, while the backbone remains fixed to retain learned representations from static images during training.
To ensure temporal consistency without depending on cumbersome geometric priors, the authors introduce a simple yet effective Temporal Gradient Matching (TGM) loss. Unlike traditional Optical Flow Based Warping (OPW) loss, which relies on the assumption that corresponding objects maintain invariant depths across frames—a false assumption in dynamic settings—the TGM loss monitors depth changes at identical spatial coordinates across successive frames, aligning it with actual temporal depth variations.
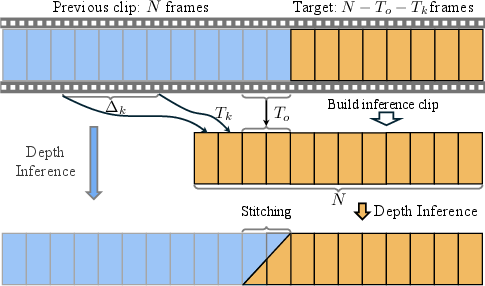
Figure 2: Inference strategy for long videos, ensuring smooth transitions between segments.
The TGM loss is complemented by scale- and shift-invariant losses, ensuring the model maintains high spatial precision while achieving temporal stability.
Inference Strategies for Long Videos
For handling extended video lengths, the paper introduces an inference strategy combining overlapping frame interpolation with key-frame referencing. This novel segment-wise processing strategy enriches the scaling consistency by referencing historical key frames, thereby reducing drift and enhancing depth coherence across lengthy sequences.
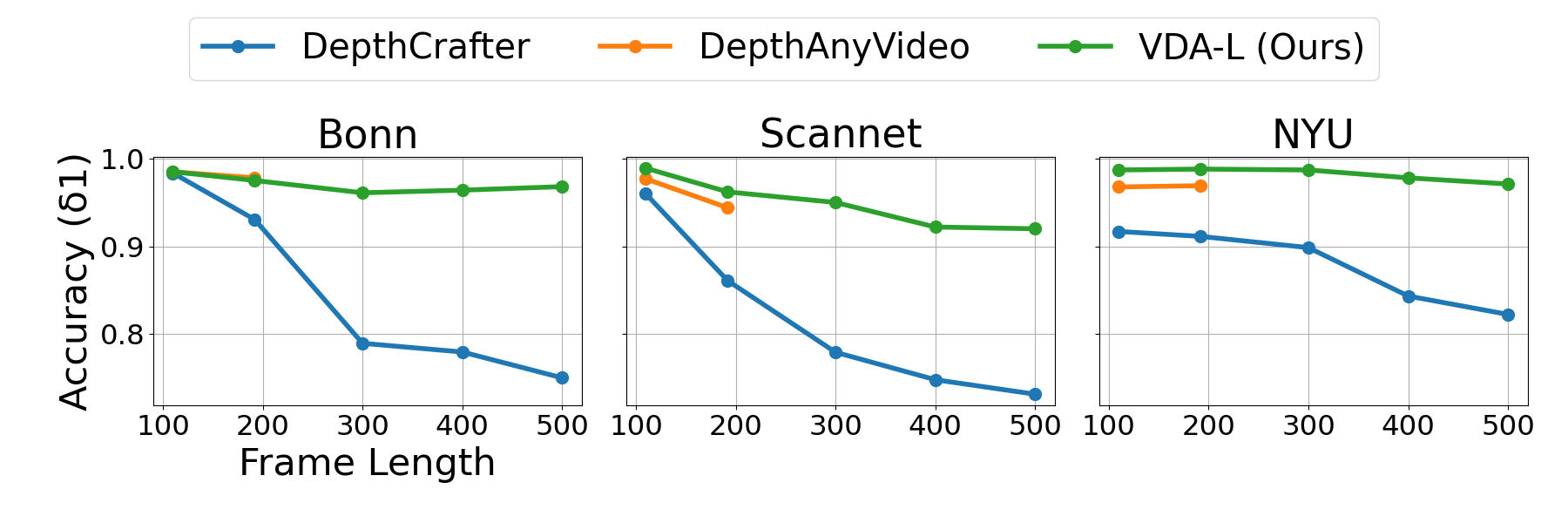
Figure 3: Video depth estimation accuracy enhances across varying frame lengths, achieved through optimized inference techniques.
Experimental Evaluation
Through stringent evaluations against contemporary methods such as NVDS, ChronoDepth, DepthCrafter, and DepthAnyVideo, the proposed model demonstrates top-tier performance in both geometric precision and temporal constancy across multiple datasets, establishing new benchmarks in zero-shot video depth estimation.
Qualitative measures show that the reconstructed depth maps by the model offer superior long-term consistency and spatial accuracy without significant overhead, making it highly suitable for real-world applications.
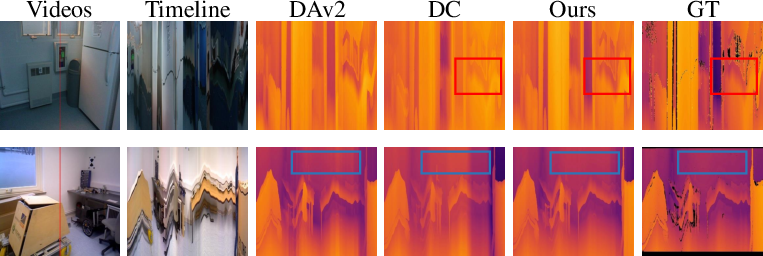
Figure 4: Real-world long video depth estimations demonstrate the superiority over existing methods.
Conclusion
In conclusion, Video Depth Anything ensures robust, consistent, and efficient depth estimation for super-long videos, outperforming current state-of-the-art methods in both spatial and temporal dimensions. This aligns with applications in robotics, augmented reality, and advanced video editing, where consistent depth maps are imperative. Future work could focus on maximizing model scalability for diverse real-world datasets, potentially integrating additional temporal priors for further enhanced efficiency.