- The paper introduces a novel method to embed multivariate time series data into the LLM token space using CNN and MLP architectures for enhanced forecasting.
- It extends Seq2seq models like MQCNN and MQTransformer by integrating pre-trained LLM decoders with innovative multivariate patching techniques.
- Empirical results on a retail demand dataset demonstrate that models such as Flan-T5 and MPT-7B achieve competitive accuracy improvements over traditional forecasting methods.
Using Pre-trained LLMs for Multivariate Time Series Forecasting
Introduction
The paper explores leveraging pre-trained LLMs to enhance multivariate time series forecasting. Traditional techniques in time series forecasting focus on statistical models to predict events over temporal sequences. This paper investigates whether the advanced capabilities of LLMs, trained extensively on vast linguistic datasets, can be redirected to forecast multivariate demand time series, offering a new method that embeds time series data into the LLM token space using novel strategies.
Methods
Forecasting Problem
The paper formulates the forecasting problem where it seeks to predict future values based on past observations and static features using a defined model Y^, parameterized by θ, optimizing quantile loss measures. This approach allows the integration of recent LLM achievements into structured time-series forecasting tasks.
Modern Forecasting Approaches
The paper builds upon existing Seq2seq architectures like MQCNN and MQTransformer, which use convolutional networks for encoding time series data and attention mechanisms for decoding, respectively. The innovation lies in employing LLMs as decoder models and using these architectures to map structured time series data into the token space traditionally occupied by language tokens.
Architectural Innovations
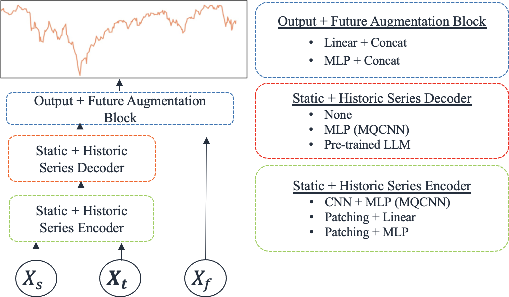
Figure 1: High level architectural design of our experiments, showcasing the use of multiple pre-trained LLMs.
The research segments the forecasting model into encoder, decoder, and output blocks. It uses CNNs and MLPs for encoding, introduces novel multivariate patching techniques, and experiments with linear and MLP adapter blocks for embedding input time-series into the LLM token space.
Multivariate Patching Strategy
This approach extends univariate patching to multivariate settings, allowing the model to better handle complex, structured time-series inputs by contextually segmenting and embedding these inputs into dimensions compatible with LLM architectures.
Empirical Evaluation
Experimental Setup
Experiments utilize a dataset from a major internet retailer, focusing on product demand forecasts over a significant temporal scope. The methods evaluated include MQCNN as a baseline and various configurations of LLM integrated systems, emphasizing the comparative performance against traditional and simpler linear models.
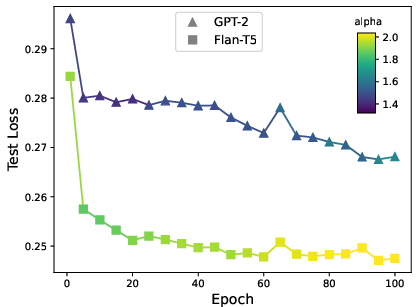
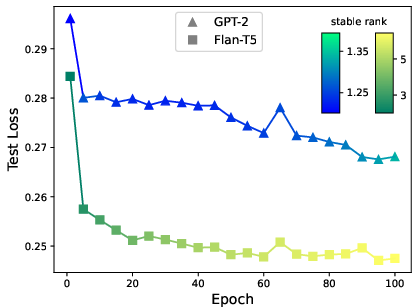
Figure 2: HTSR metrics predict forecasting accuracy across architectures (varying base FPTs) and within architecture across epochs.
Results
Empirical results demonstrate competitive performance of pre-trained LLMs, specifically noting their emergent capabilities for forecasting tasks. While LLMs like Flan-T5 and MPT-7B achieve notable accuracy improvements over baselines, integration complexities and computational constraints are acknowledged.
Model Diagnostics and Insights
HTSR Theory Application
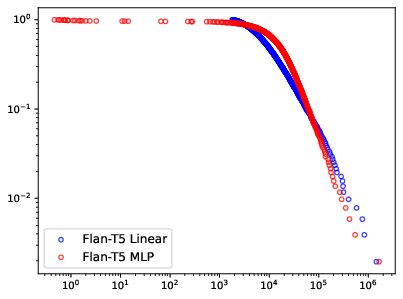
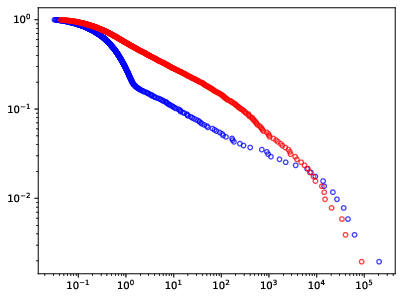
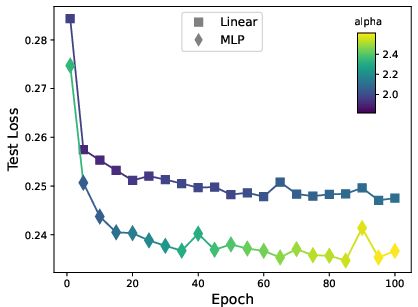
Figure 3: Layer-level weight analysis identifies sub-optimal model architecture and predicts forecasting accuracy.
The paper incorporates advanced diagnostics using Heavy-Tailed Self-Regularization Theory, employing layer spectral analysis as indicators of model robustness and adequacy. It finds correlations between normal spectral decay and model performance, guiding architectural refinements.
Discussion
The use of LLMs for non-textual data is promising but requires careful architecture adaptations. This paper captures the preliminary benefits and limitations of implementing LLM architectures for structured forecasting tasks and offers insights into future research directions for embedding latent information effectively into predictive models.
Conclusion
Pre-trained LLMs offer a novel avenue for enhancing multivariate time series forecasting, with model diagnostics and empirical results underscoring their potential. Future work should explore finer architectural tuning and extended empirical evaluations to consolidate these preliminary findings into robust forecasting frameworks.
