- The paper’s main contribution is the Sui Generis score, which quantifies narrative uniqueness by measuring semantic plot echoes in LLM outputs.
- Empirical results from over 3,700 story segments reveal that human-written stories achieve significantly higher diversity than LLM-generated narratives.
- The study highlights practical implications for creative content and prompt engineering, advocating the Sui Generis score to improve narrative distinctiveness.
Echoes in AI: Quantifying Plot Homogenization in LLM Story Generation
Introduction
"Echoes in AI: Quantifying Lack of Plot Diversity in LLM Outputs" (2501.00273) rigorously interrogates narrative diversity in outputs from LLMs, focusing on GPT-4 and LLaMA-3. The paper presents evidence that text generated via LLMs frequently exhibits semantically repetitive plot structures—echoes—even when surface lexical realization varies. The central contribution is the Sui Generis score, a metric that quantifies the narrative uniqueness of a story element within the spectrum of possible LLM-generated continuations for a given prompt. Empirical results on both human-written and LLM-generated stories—drawn from WritingPrompts and Wikipedia-based TV plot summaries—demonstrate a pronounced deficit of plot originality in LLM generations compared to human-authored texts. Additionally, the Sui Generis score correlates with human assessment of surprise, tying computational measurement to cognitive notions of creativity and narrative expectation.
The Sui Generis Score: Methodology and Rationale
The Sui Generis score operationalizes plot-level uniqueness by measuring how often narrative elements from one story reappear in alternative continuations generated by an LLM, conditioned on varying amounts of story context. Specifically, stories are segmented, and for each segment si, alternative continuations are generated with prefixes of increasing length (j segments). For each alternative, the presence of an analogous plot element is detected via a binary function a(si,Cjk), estimated through LLM-based entailment judgments. The core intuition: elements echoed with less context (i.e., requiring little prompt information to reappear) are penalized more heavily, reflecting their lack of uniqueness.

Figure 1: Schematic illustrating how alternative continuations with longer or shorter prefixes yield narrative echoes; echoes induced with less context result in more severe penalization in the Sui Generis score.
The aggregate measure is a weighted average over the negative log-likelihood of echo occurrence across all prefix lengths, emphasizing repetition discovered with minimal context. This framework generalizes beyond lexical overlap and token-based perplexity by directly targeting semantic and plot-level recurrence.
Experimental Results: Human versus LLM Output
Applying the Sui Generis framework, the study evaluates over 3,700 story segments from both human and LLM-authored stories across two datasets. The principal findings are as follows:
- Human-written stories systematically attain higher Sui Generis scores compared to all LLM baselines, confirming that LLM generations lack both local and global narrative diversity.
- LLM generations are dominated by recurrent, idiosyncratic combinations of plot elements; human-authored continuations, even when prompted identically, tend to contain unique or rare plot components that lie outside the high-probability regions of the LLM output distribution.
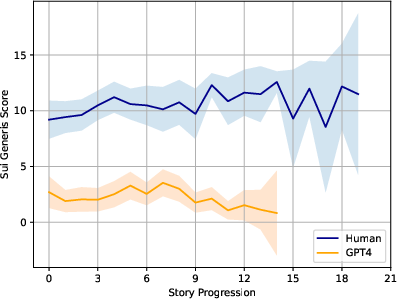
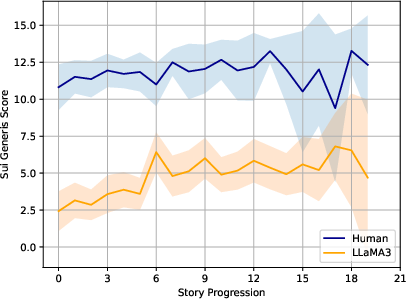
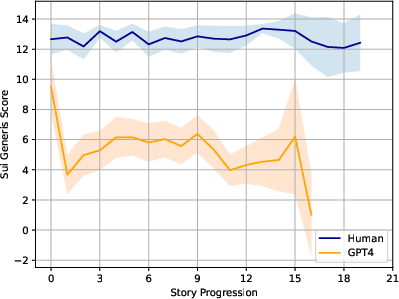
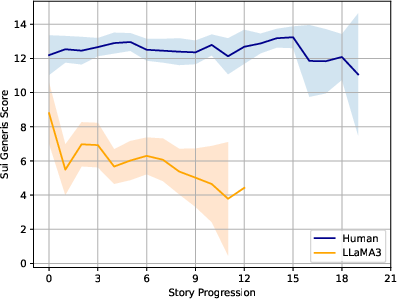
Figure 2: Comparison of average Sui Generis scores across segment positions, revealing a consistent gap between human versus GPT-4 story output.
Cross-model analysis shows that plot elements generated by LLaMA-3 are frequently echoed by GPT-4 and vice versa, indicating convergence to similar narrative attractors across models.
Semantic Echoes and Narrative Pacing
The study documents a distinct pacing pathology in LLM-generated narratives. Quantitative analysis of the Sui Generis "drop ratio" reveals abrupt declines in plot uniqueness following surprise events. This is associated with rapidly executed or unresolved plot turns—contrasting with the sustained and carefully resolved peaks in human-written stories. Human narratives tend to scaffold surprise through gradual development, whereas LLM outputs excessively condense narrative arcs, resulting in transient peaks in uniqueness followed by rapid reversion to formulaic content.
Correlation with Human Surprise Judgments
Significantly, the Sui Generis score exhibits moderate Spearman correlation (0.55) with pooled human assessments of segment-level surprise. For the highest and lowest Sui Generis values, human raters agree strongly with the automatic score, though mid-level scores introduce greater variance. Importantly, Sui Generis outperforms token-level measures like perplexity—which are sensitive to paraphrasing and local rewording—in capturing plot-level unexpectedness.
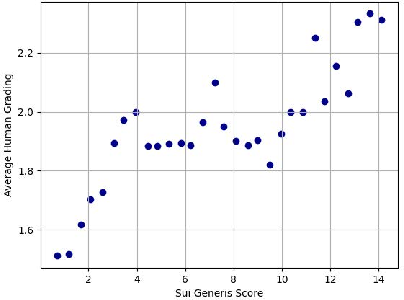
Figure 3: Scatter plot illustrating positive correlation between average human-graded surprisal and Sui Generis scores in LLaMA-3 outputs.
Comparative Analysis with Other Diversity Metrics
A direct comparison between the prompting-based semantic entailment used in the Sui Generis score and common text similarity/diversity metrics (self-BLEU, n-gram diversity, embedding distance, and topic overlap) shows that the Sui Generis approach aligns much more closely with human judgments of narrative repeatability. Surface-level features and shallow embeddings fail to track narrative echoing at the plot level, validating the necessity for bespoke metrics like Sui Generis when evaluating creative story generation.
Implications and Future Directions
The demonstrated lack of plot diversity in LLM generations has substantial implications for AI-assisted creative writing, gaming, education, and cultural content authoring. At scale, the mechanics of LLM sampling threaten to homogenize narrative spaces, reducing the collective pool of ideas and potentially eroding cultural variety in creative works.
From a practical standpoint, Sui Generis can serve as both an evaluation and generation-time optimization signal: maximizing for high Sui Generis scores can yield outputs with higher narrative uniqueness, albeit with significant computational cost due to the combinatorial nature of alternative sampling. The metric also extends to other sequential modalities (e.g., music, image, video) by redesigning the echo-detection function for those domains.
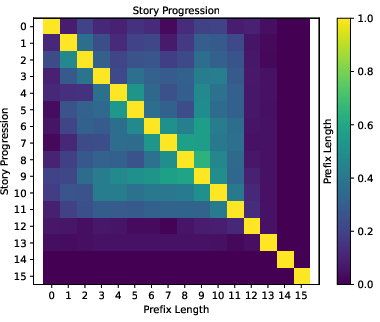
Figure 4: Heatmap of average echo scores (pi,j), illustrating that segment-level repeats are substantially more prevalent in LLM outputs compared to human-written stories.
Moreover, Sui Generis enables programmatic identification of 'echoic' (low-scoring) story segments which could benefit from human intervention, facilitating hybrid human-AI generative systems. The finding that certain prompts predispose both human and LLM writers to lower Sui Generis scores suggests that prompt engineering itself can modulate output diversity, opening new research avenues in control for creative generation.
Limitations
The approach depends on access to capable entailment models (e.g., GPT-4 for entailment assessment), and the computational demands scale quadratically with story length and the number of alternatives sampled. If LLMs gain stronger memorization ability or their training data overlaps heavily with the evaluation set, the method may misestimate genuine originality. Finally, further research is needed to map Sui Generis sensitivity to different segmentation, genre, and cross-linguistic settings.
Conclusion
This work establishes, through formal quantification, that LLM-generated narratives are characterized by extensive plot-level echoing across alternative generations, sharply contrasting with the uniqueness of human creative writing. The Sui Generis score provides a robust, semantically motivated mechanism to measure and optimize for narrative diversity, with direct ties to human-perceived surprise. Its adoption as a standard for creative language evaluation offers pathways to address issues of output homogenization in both automated and collaborative AI systems. Continued exploration is warranted to extend these insights to other creative domains and to integrate diversity regularization into the core generation and alignment loops of future LLMs.