- The paper demonstrates that LLMs can self-verify and refine outputs, quantified by the generation-verification (GV) gap.
- It reveals that the GV gap increases with pre-training flops when employing effective methods like Chain-of-Thought prompting.
- Iterative self-improvement saturates after a few rounds, reducing generation diversity even as accuracy consolidates.
Mind the Gap: Examining the Self-Improvement Capabilities of LLMs
Introduction
The paper "Mind the Gap: Examining the Self-Improvement Capabilities of LLMs" investigates the self-improvement potential of LLMs by focusing on their ability to self-verify and refine their generations. This study is pivotal as LLMs are increasingly relied upon for various applications, including generating new training data. Understanding how these models self-improve could enhance both their training and real-time performance.
Self-Improvement Framework
The self-improvement framework in LLMs is characterized by the model's ability to generate, verify, and refine its outputs:
- Generation: Multiple candidate responses are generated from a given prompt.
- Verification: The responses are evaluated using few-shot prompting to predict their correctness.
- Model Update: The model is updated based on the self-verified responses through techniques like rejection sampling or RL-based distillation.
The paper formalizes the concept of a generation-verification gap (GV-Gap), which quantifies the improvement in performance when generations are re-weighted by the model's self-verification score. This gap is central for evaluating self-improvement effectiveness, showing how the model's verification can potentially guide its own outputs towards better performance.
Scaling Properties
Experiments across various model families reveal a scaling law for the generation-verification gap. Notably, the GV-Gap increases monotonically with pre-training flops when using effective verification methods like Chain-of-Thought (CoT) prompting (Figure 1). This demonstrates that larger models, which have undergone more extensive pre-training, can better leverage their self-verification capabilities to enhance performance.
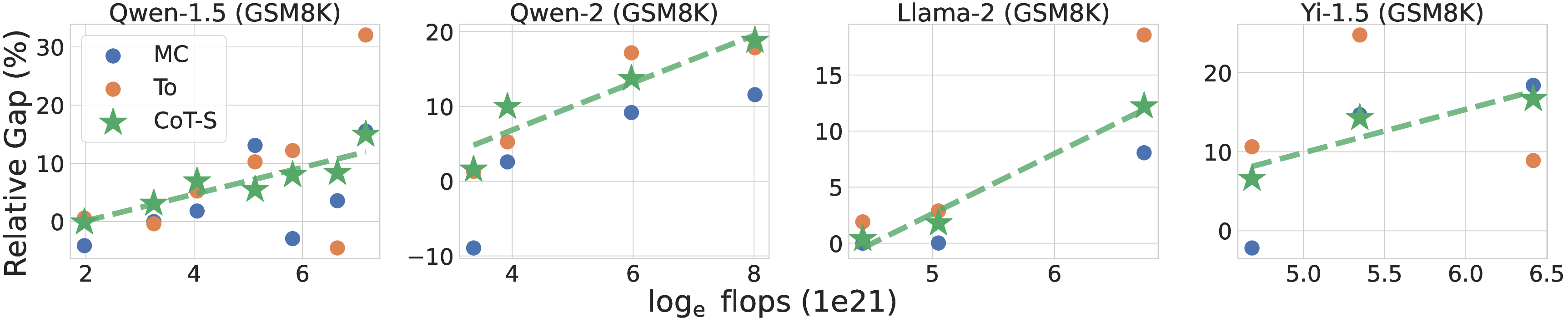
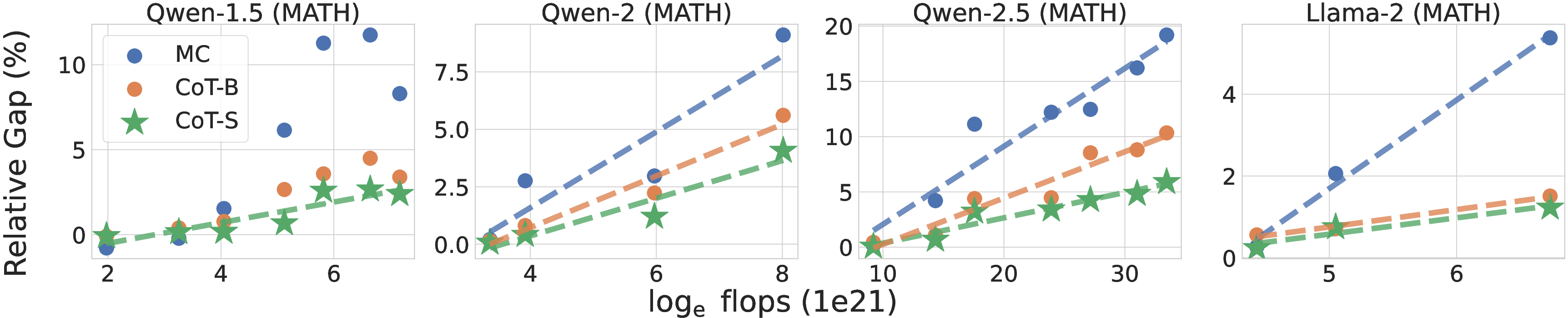
Figure 1: Changes in the relative generation-verification gap scaling with pre-training flops using CoT verification.
The study identifies specific conditions under which this scaling property holds, including the setup of proxy utility functions and effective reweighting strategies. The insights provide empirical guidance for pre-training and fine-tuning strategies that could harness this scaling phenomenon.
Iterative Self-Improvement
The research explores the dynamics of multi-round self-improvement, examining how successive rounds of generation, verification, and distillation impact model performance:
- Saturation: The GV-Gap typically diminishes to near-zero after a few rounds, indicating a saturation point beyond which further iterative improvements are negligible.
- Diversity Reduction: There is a noted decline in effective generation diversity, as represented by metrics like pass@k (Figure 2). This suggests that while models consolidate around more accurate responses, they may also simultaneously become less explorative.
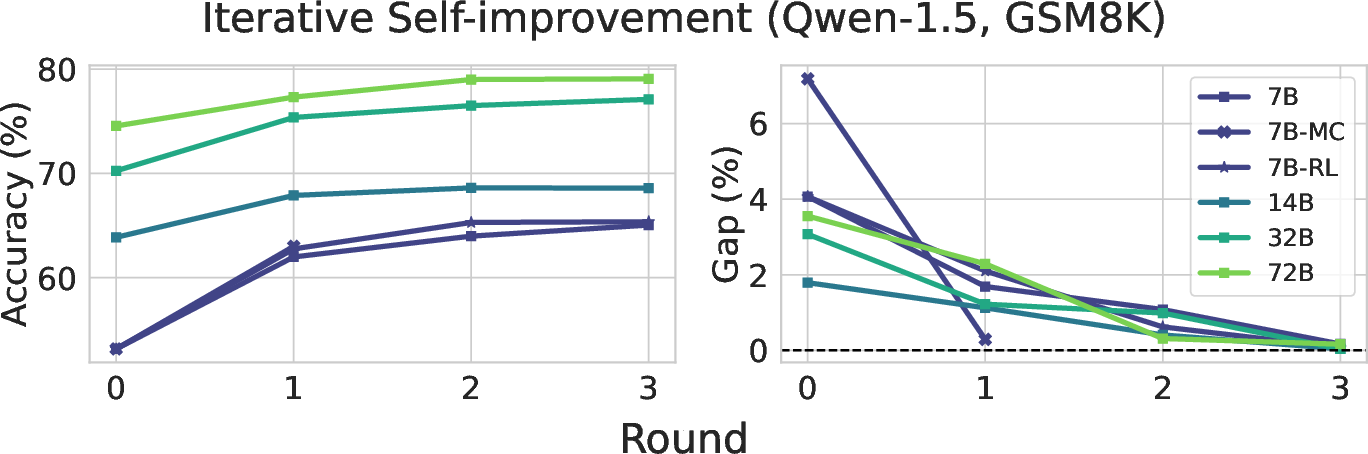
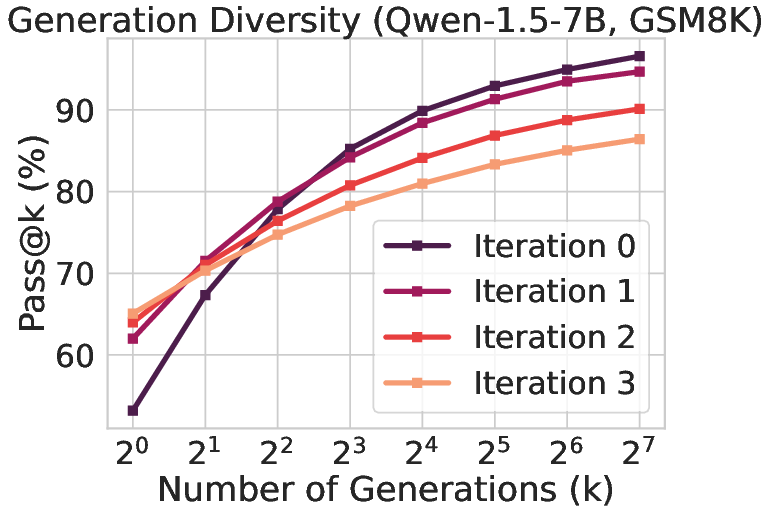
Figure 2: The iterative self-improvement process showing changes in generation accuracy and effective diversity.
Verification Mechanisms
A detailed examination of various verification mechanisms—Multiple Choice (MC), CoT, and Tournament formats—highlights their distinct impacts on self-improvement:
- Generalization: Consistency in gap behavior across different models suggests that optimal verification thresholds and mechanisms can be generalized from smaller to larger models.
- Distinction: Different verification methods yield non-trivial differences in outputs and gaps, indicating potential benefits from combining methods, such as through an ensemble approach.
Conclusion
The paper provides a comprehensive analysis of LLMs' self-improvement capabilities, anchored by the generation-verification framework. The findings reveal critical insights into the scaling properties of LLMs and the iterative self-improvement process, presenting new avenues for optimizing LLM training and deployment. Future research could explore more complex verification combinations and strategies to maintain or improve effective generation diversity over iterated refinements. These efforts promise to unlock further gains in LLM utility and applicability across domains.