- The paper introduces a comprehensive evaluation framework for assessing text embedding models in aligning built asset information with standardized classification systems.
- The study evaluates 24 models across clustering, retrieval, and reranking tasks, demonstrating that larger models typically perform better while also revealing significant performance variability.
- The findings highlight the necessity for domain adaptation and tailored benchmarks to improve automated asset management and robust digital twin implementations.
Benchmarking Pre-trained Text Embedding Models in Aligning Built Asset Information
The paper "Benchmarking Pre-trained Text Embedding Models in Aligning Built Asset Information" (2411.12056) introduces a comprehensive evaluation framework for assessing the ability of text embedding models to map built asset information onto established classification systems and taxonomies. The study highlights the potential automation benefits offered by state-of-the-art LLMs and identifies existing gaps through a detailed benchmark across several tasks aimed at enhancing asset management practices.
Introduction
The mapping of built asset information to standardized classification systems is critical for efficient asset management, especially considering the growing popularity of digital twins and federated data access. However, aligning this data with pre-defined systems is fraught with challenges due to its diverse and multi-disciplinary nature. For instance, varying terminologies used by architects and engineers, and differences in regulatory standards, complicate this alignment process. With previous methods relying heavily on manual input, the potential for automation using NLP, particularly contextual text embeddings, is explored as a promising solution.
Development of Built Product Corpus
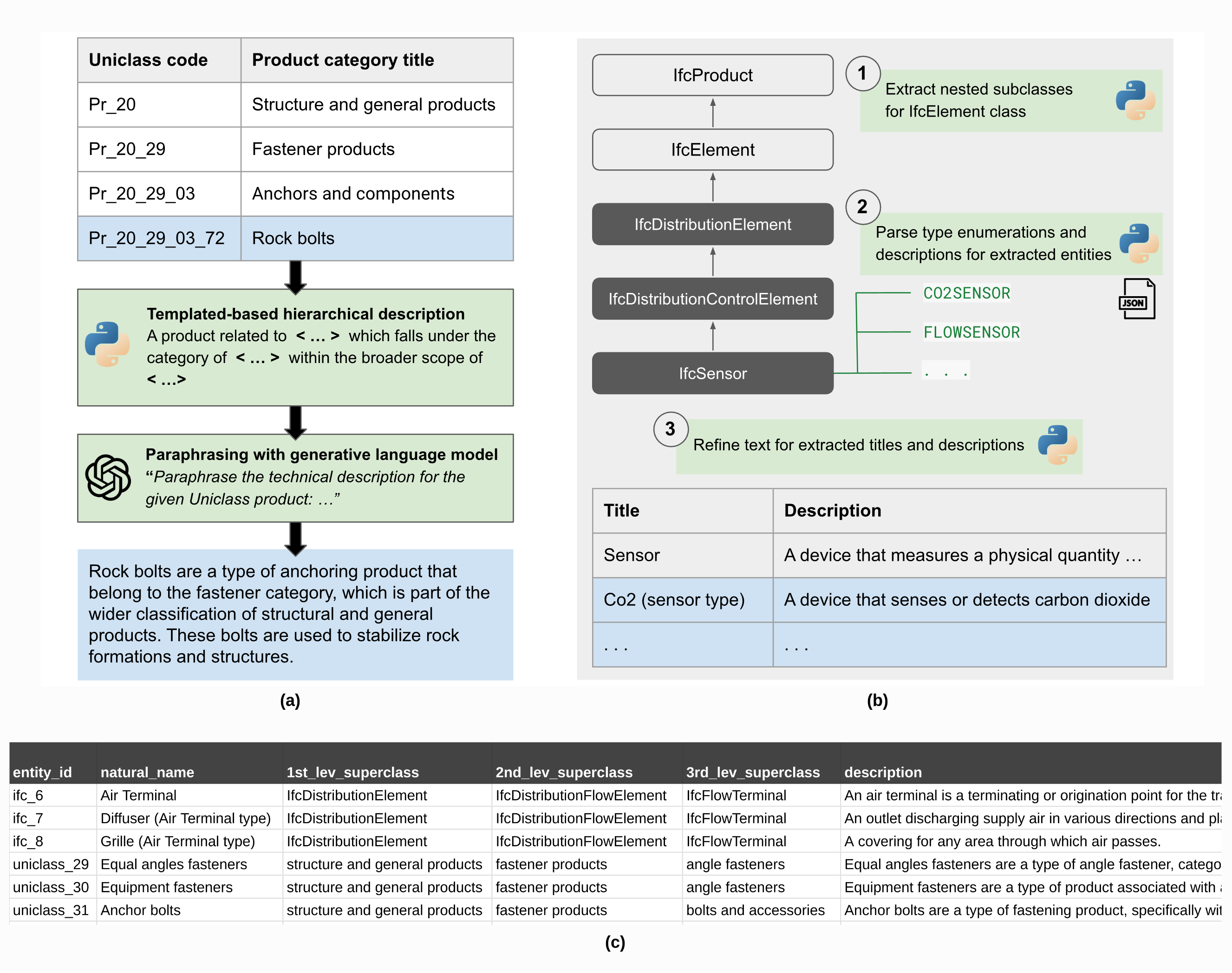
Figure 1: Overview of the main steps in developing the built product corpus, including extraction and hierarchical relation processes.
Two primary sources were used to develop the corpus:
- Industry Foundation Classes (IFC): Provides a comprehensive digital description, serving as a key resource for defining built asset entities.
- Uniclass: A unified classification system offering extensive coverage of product types, vital for ensuring classification consistency.
Corpus development involved extracting product names, descriptions, and hierarchical categories, followed by manual paraphrasing and review to ensure accuracy and consistency.
Benchmark Tasks
The benchmarking framework evaluates text embedding models across three main tasks: clustering, retrieval, and reranking, with considerations for text length and contextual representation. The proposed datasets cover various sub-domain subjects, ensuring diverse coverage and robust evaluation.
- Clustering: Tasks group similar products based on textual similarity, evaluated using V-measure scores for homogeneity and completeness.
- Retrieval: Tasks aim to retrieve relevant product descriptions based on a given query, focusing on how well models recognize contextually accurate mappings.
- Reranking: More focused than retrieval, reranking evaluates models based on their ability to rank smaller, challenging subsets of data, using negative sampling strategies.
Results and Discussion
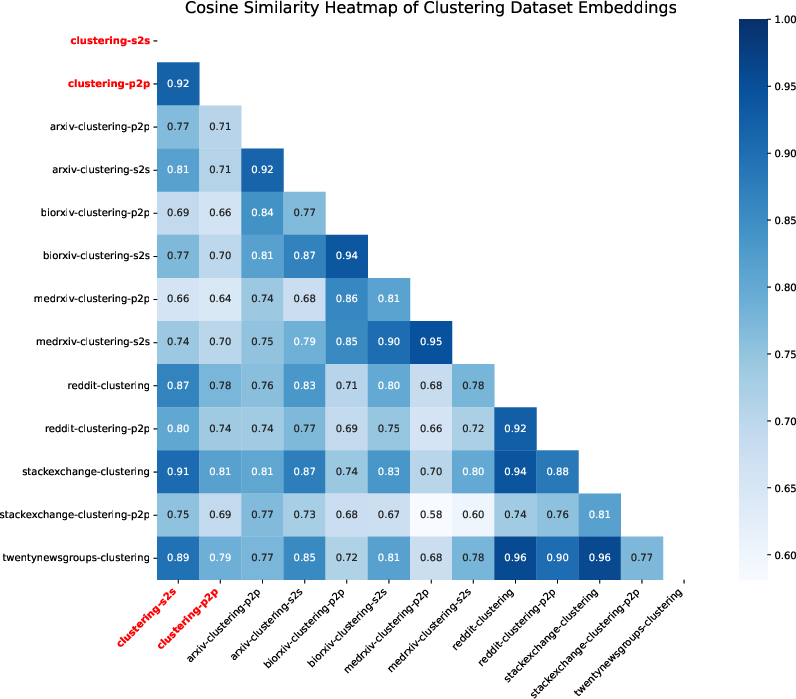
Figure 2: Thematic similarity heatmap between proposed clustering tasks and existing datasets, highlighting thematic overlaps.
The evaluation of 24 models indicates that larger models tend to perform better, although smaller models can still be competitive in some tasks. Performance varied notably across tasks, emphasizing the need for specialized domain benchmarking. Notably, proprietary models from OpenAI showed strong performance, aligning with findings in other underrepresented domains but raising questions on their efficacy without transparency into model specifics.
The thematic analysis of datasets comparing with MTEB benchmark datasets shows limited transferability, even with significant thematic similarities. This emphasizes the complexity of built asset data, necessitating tailored benchmarks for effective evaluation.
Conclusion
The study underscores the potential of using state-of-the-art text embedding models in automating built asset information mapping but highlights substantial variability in model performance across tasks and input types. It calls for further research into domain adaptation strategies, particularly instruction tuning, to improve alignment processes. The benchmark established provides a foundational tool for future evaluations, supporting the development of domain-specific models and tasks that address the intricacies of built asset information. Finally, dataset availability is crucial for advancing this field, advocating for larger, more diverse datasets encompassing multiple languages and domains.

