- The paper reveals that verbosity compensation is pervasive in LLMs, with models like GPT-4 showing verbosity rates over 50%.
- The study demonstrates a 27.61% performance gap on the Qasper dataset, linking verbose responses with increased uncertainty measured by perplexity and Laplacian scores.
- A cascade model selection algorithm is proposed to mitigate verbosity, reducing the Mistral model’s verbosity from 63.81% to 16.16% on Qasper.
Verbosity Compensation Behavior in LLMs
Introduction
The paper "Verbosity = Veracity: Demystify Verbosity Compensation Behavior of LLMs" (2411.07858) presents an investigation into the verbosity compensation (VC) behavior exhibited by LLMs. This type of behavior, akin to human hesitation in uncertain situations, entails LLMs generating excessively verbose responses that include repetition, ambiguity, or unnecessary details. The study identifies the pervasiveness of VC across various models and datasets, emphasizing that such verbosity does not correlate to improved performance.
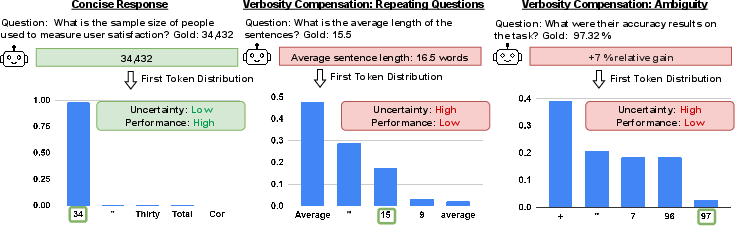
Figure 1: An illustration of comparison between concise and verbose responses. In the first response, LLM generates a concise answer, while in the second and third responses, LLM performs repeating, and ambiguity, leading to a verbose response with low performance and high uncertainty.
Experimental Framework
The research outlines an experimental setup involving 14 newly developed LLMs tested on five datasets, including both knowledge-based and reasoning-based question-answering tasks. To quantify VC, a verbosity detector is employed, categorizing responses as verbose if they exceed three tokens yet convey the same meaning as a concise counterpart. Across all datasets, VC frequency is substantial, with some models like GPT-4 exhibiting a rate of 50.40%.
Key Findings and Analysis
- Performance and Verbosity Correlation: The study reveals a significant discrepancy between the performance of concise and verbose responses, notably a 27.61% gap on the Qasper dataset. This performance gap underscores the urgency to disentangle verbosity from veracity since verbosity does not naturally diminish as LLM capabilities grow.
- Uncertainty Connection: Verbose responses are associated with higher uncertainty levels, suggesting that VC is a compensatory mechanism for model uncertainty. The study measures uncertainty using perplexity and Laplacian scores, observing increased uncertainty with longer responses across all datasets.

Figure 2: Uncertainty quantification of three open-sourced and one close-sourced models. The scores are averaged across all five datasets. The uncertainty increases with the increasing length of the generated output for all models.
- Cascade Model Selection Algorithm: In response to the identified verbosity behavior, the authors propose a cascade algorithm designed to mitigate VC by replacing verbose responses with those generated by larger models. This approach significantly reduces the VC frequency, as evidenced by reducing the Mistral model's verbosity from 63.81% to 16.16% on the Qasper dataset.
Implications and Future Directions
The implications of this research are multifaceted, impacting both the theoretical understanding of LLM behavior and practical applications. By highlighting the linkage between verbosity and uncertainty, the paper suggests new avenues for reducing model hesitancy and improving response efficiency. Practically, the findings advocate for architectural and algorithmic innovations aimed at enhancing LLM reliability.
As LLMs continue to evolve, addressing VC behavior is crucial for optimizing their utility in real-world applications. Future research might focus on refining verbosity mitigation strategies, exploring adaptive models that can discern and apply verbosity appropriately, and enhancing model training protocols to naturally eschew verbosity unless contextually justified.
Conclusion
This paper offers a comprehensive examination of verbosity compensation behavior in LLMs, revealing its pervasive nature and adverse impact on performance, particularly under uncertainty. Through methodical analysis and the introduction of a novel cascade algorithm, the study contributes significant insights into improving the efficiency and reliability of LLM responses, setting the stage for future advancements in AI language processing technologies.

