Modulating State Space Model with SlowFast Framework for Compute-Efficient Ultra Low-Latency Speech Enhancement
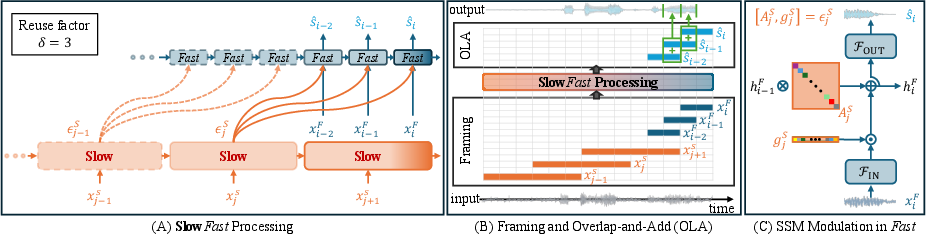
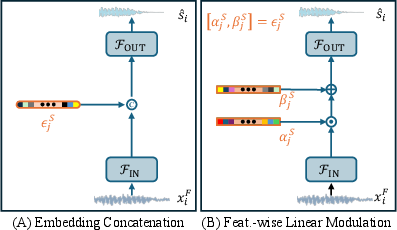
Abstract: Deep learning-based speech enhancement (SE) methods often face significant computational challenges when needing to meet low-latency requirements because of the increased number of frames to be processed. This paper introduces the SlowFast framework which aims to reduce computation costs specifically when low-latency enhancement is needed. The framework consists of a slow branch that analyzes the acoustic environment at a low frame rate, and a fast branch that performs SE in the time domain at the needed higher frame rate to match the required latency. Specifically, the fast branch employs a state space model where its state transition process is dynamically modulated by the slow branch. Experiments on a SE task with a 2 ms algorithmic latency requirement using the Voice Bank + Demand dataset show that our approach reduces computation cost by 70% compared to a baseline single-branch network with equivalent parameters, without compromising enhancement performance. Furthermore, by leveraging the SlowFast framework, we implemented a network that achieves an algorithmic latency of just 62.5 {\mu}s (one sample point at 16 kHz sample rate) with a computation cost of 100 M MACs/s, while scoring a PESQ-NB of 3.12 and SISNR of 16.62.
- “Tolerable hearing aid delays. v. estimation of limits for open canal fittings,” Ear and hearing, vol. 29, no. 4, pp. 601–617, 2008.
- “Augmented/mixed reality audio for hearables: Sensing, control, and rendering,” IEEE Signal Processing Magazine, vol. 39, no. 3, pp. 63–89, 2022.
- “Masked multi-head self-attention for causal speech enhancement,” Speech Communication, vol. 125, pp. 80–96, 2020.
- “Dense CNN with self-attention for time-domain speech enhancement,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 29, pp. 1270–1279, 2021.
- “Real-time single-channel speech enhancement based on causal attention mechanism,” Applied Acoustics, vol. 201, pp. 109084, 2022.
- “Lightweight causal transformer with local self-attention for real-time speech enhancement.,” in Interspeech, 2021, pp. 2831–2835.
- “Real-time speech enhancement using equilibriated rnn,” in ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020, pp. 851–855.
- “Dynamic gated recurrent neural network for compute-efficient speech enhancement,” in Interspeech, 2024, pp. 677–681.
- Yi Luo and Nima Mesgarani, “Tasnet: time-domain audio separation network for real-time, single-channel speech separation,” in 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2018, pp. 696–700.
- “Dual-path RNN: Efficient long sequence modeling for time-domain single-channel speech separation,” in ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020, pp. 46–50.
- “A two-stage end-to-end system for speech-in-noise hearing aid processing,” Proc. Clarity, pp. 3–5, 2021.
- “Binaural speech enhancement based on deep attention layers,” Proc. Clarity, pp. 6–8, 2021.
- “Deep neural network based low-latency speech separation with asymmetric analysis-synthesis window pair,” in 2021 29th European Signal Processing Conference (EUSIPCO). IEEE, 2021, pp. 301–305.
- “STFT-domain neural speech enhancement with very low algorithmic latency,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 31, pp. 397–410, 2022.
- “A simple rnn model for lightweight, low-compute and low-latency multichannel speech enhancement in the time domain,” in Interspeech, 2023.
- “A low delay, variable resolution, perfect reconstruction spectral analysis-synthesis system for speech enhancement,” in 2007 15th European Signal Processing Conference, 2007, pp. 222–226.
- “Unsupervised low latency speech enhancement with rt-gcc-nmf,” IEEE Journal of Selected Topics in Signal Processing, vol. 13, no. 2, pp. 332–346, 2019.
- “Knowledge boosting during low-latency inference,” in Interspeech, 2024.
- “Efficiently modeling long sequences with structured state spaces,” arXiv preprint arXiv:2111.00396, 2021.
- “Resurrecting recurrent neural networks for long sequences,” in International Conference on Machine Learning. PMLR, 2023, pp. 26670–26698.
- “Film: Visual reasoning with a general conditioning layer,” in Proceedings of the AAAI conference on artificial intelligence, 2018, vol. 32.
- “FSCNet: Feature-specific convolution neural network for real-time speech enhancement,” IEEE Signal Processing Letters, vol. 28, pp. 1958–1962, 2021.
- “A deep learning loss function based on the perceptual evaluation of the speech quality,” IEEE Signal Processing lLetters, vol. 25, no. 11, pp. 1680–1684, 2018.
- “Training supervised speech separation system to improve stoi and pesq directly,” in 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2018, pp. 5374–5378.
- Jean-Marc Valin, “A hybrid dsp/deep learning approach to real-time full-band speech enhancement,” in 2018 IEEE 20th international workshop on multimedia signal processing (MMSP). IEEE, 2018, pp. 1–5.
- “Low latency speech enhancement for hearing aids using deep filtering,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 30, pp. 2716–2728, 2022.
- “Ultra low complexity deep learning based noise suppression,” in ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2024, pp. 466–470.
- Cassia Valentini-Botinhao et al., “Noisy speech database for training speech enhancement algorithms and tts models,” 2017.
- “The voice bank corpus: Design, collection and data analysis of a large regional accent speech database,” in 2013 international conference oriental COCOSDA held jointly with 2013 conference on Asian spoken language research and evaluation (O-COCOSDA/CASLRE), 2013, pp. 1–4.
- “The diverse environments multi-channel acoustic noise database (demand): A database of multichannel environmental noise recordings,” in Proceedings of Meetings on Acoustics (ICA2013). Acoustical Society of America, 2013, vol. 19, p. 035081.
- “Perceptual evaluation of speech quality (pesq)-a new method for speech quality assessment of telephone networks and codecs,” in 2001 IEEE International Conference on Acoustics, Speech, and Signal Processing, 2001, vol. 2, pp. 749–752.
- “An algorithm for intelligibility prediction of time–frequency weighted noisy speech,” IEEE Transactions on Audio, Speech, and Language Processing, vol. 19, no. 7, pp. 2125–2136, 2011.
- “An algorithm for predicting the intelligibility of speech masked by modulated noise maskers,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 24, no. 11, pp. 2009–2022, 2016.
- “The hearing-aid speech perception index (haspi),” Speech Communication, vol. 65, pp. 75–93, 2014.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

