- The paper introduces Mutual Information Preserving Pruning (MIPP), a dynamic method that maintains information transfer between consecutive layers.
- It utilizes the Transfer Entropy Redundancy Criterion for dynamic node selection, effectively avoiding layer collapse at high sparsity.
- Evaluations on various architectures show that MIPP outperforms static procedures by better preserving network accuracy and adaptability.
Introduction
The paper "Mutual Information Preserving Neural Network Pruning" presents a method to enhance the efficacy of neural network pruning through a technique called Mutual Information Preserving Pruning (MIPP). The objective of pruning is to reduce the complexity and resource consumption of a neural network while maintaining its performance. Structured pruning, which selects entire nodes or filters rather than individual weights, allows for structured models that are more compatible with hardware architectures.
Methodology
MIPP aims to preserve the mutual information (MI) between activations of adjacent layers during the pruning process. Maintaining MI ensures that the pruned network remains trainable, as the activations of pruned upstream layers can approximate those of downstream layers. The paper introduces a dynamic node selection mechanism using the Transfer Entropy Redundancy Criterion (TERC) which selects nodes based on their entropy transfer to subsequent layers.
Dynamic Pruning Mechanism
The proposed method deviates from traditional static ranking of nodes by dynamically evaluating and pruning nodes. This allows MIPP to adjust node selection iteratively, factoring in inter-node interactions and avoiding rigid structures that can lead to untrainable models. The approach is particularly beneficial in mitigating the risk of layer collapse at high sparsity levels.
MI Estimation and Feature Selection
For high-dimensional spaces common in neural networks, MI is estimated using a methodology that associates MI with the reduction in prediction error. This estimation supports feature selection by determining which nodes or features contribute to meaningful information transfer to subsequent layers. MIPP's framework is versatile enough to apply to feature selection tasks by identifying pixels that contribute significant entropy to downstream activations.
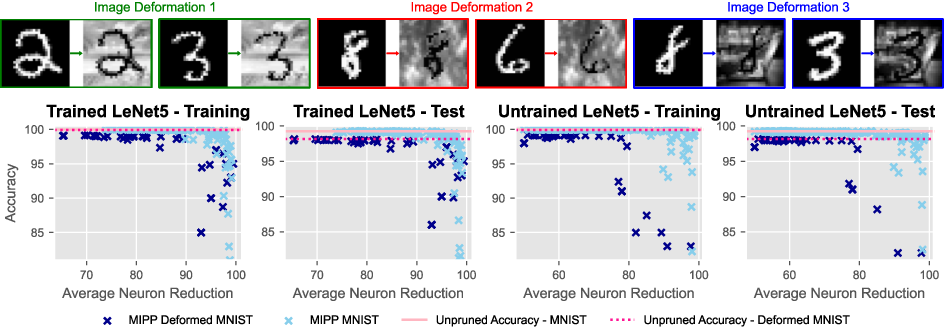
Figure 1: Top. Deforming MNIST for increased image complexity. These transformations were applied randomly with equal probability and then kept consistent during training, pruning, and re-training. Bottom. Changes in pruning ability of MIPP caused by image deformation.
Evaluation
MIPP's efficacy was evaluated across a variety of architectures and datasets, including LeNet5, VGG11, ResNet18, and ResNet50 on datasets like MNIST, CIFAR10, CIFAR100, and ImageNet. The experiments demonstrated MIPP's superior performance in maintaining network accuracy while achieving higher sparsity compared to baseline methods such as SynFlow, GraSP, ThiNet, and SOSP-H.
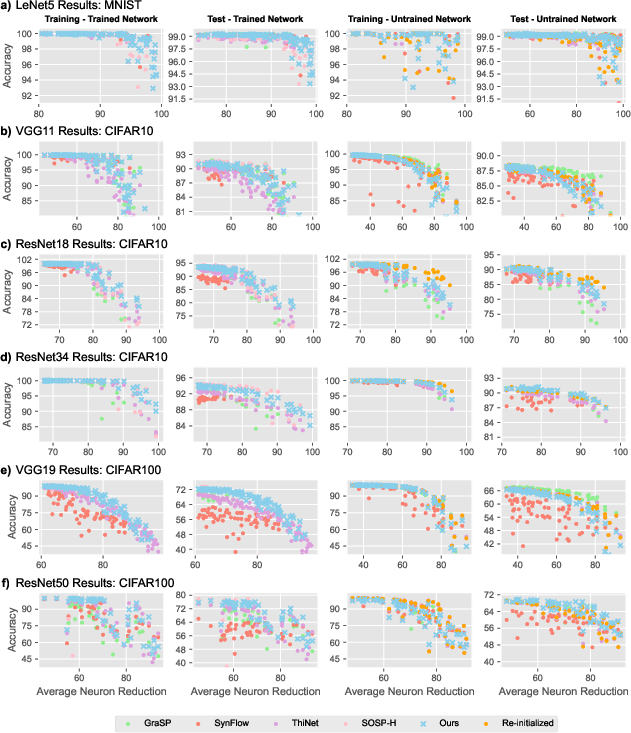
Figure 2: Pruning results for ours and other methods as applied to multiple datasets and models.
Layer Collapse Resistance
MIPP exhibited strong resistance to layer collapse, a prevalent issue in global pruning methods where entire layers can be inadvertently removed, rendering the network untrainable.
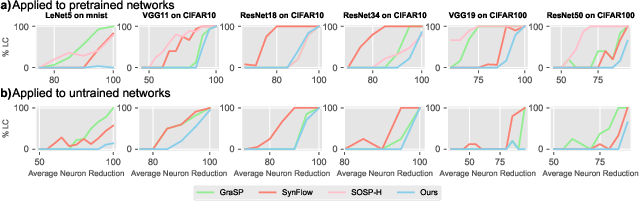
Figure 3: The percentage of runs that led to untrainable layer collapse. Specifically, we bin runs by the percentage of neurons removed, where one bin contains all the runs within a 5% increment. We then calculate the percentage of these runs that lead to layer collapse.
Per-Layer Pruning Ratios
MIPP dynamically establishes per-layer pruning ratios (PRs) tailored to the specific architecture and dataset. This adaptability enhances performance and generalizability, as observed through experiments on various models, including complex architectures like ResNet50.
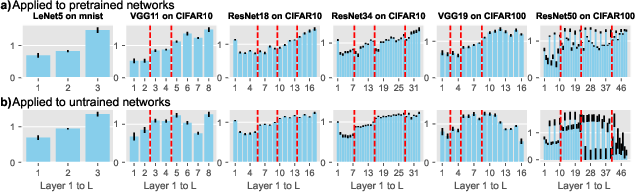
Figure 4: These experiments demonstrate the per-layer PR selected by MIPP. For the different layer-wise PRs we divide them by the average of all the layers in order to normalize. We omit results on ImageNet for space and clarity.
Conclusion
MIPP demonstrates a robust and flexible approach to neural network pruning, addressing crucial limitations of static pruning methods. By preserving MI between layers, MIPP maintains network re-trainability and exhibits strong performance across different datasets and architectures. Its dynamic and activation-based pruning approach ensures structural integrity and boosts the capability of pruned networks to generalize effectively. Future research directions might explore the adaptation of MIPP to other domains beyond vision, as well as further optimization of its pruning strategy for even more complex architectures.