In-context Learning for Mixture of Linear Regressions: Existence, Generalization and Training Dynamics
Published 18 Oct 2024 in stat.ML and cs.LG | (2410.14183v2)
Abstract: We investigate the in-context learning capabilities of transformers for the $d$-dimensional mixture of linear regression model, providing theoretical insights into their existence, generalization bounds, and training dynamics. Specifically, we prove that there exists a transformer capable of achieving a prediction error of order $\mathcal{O}(\sqrt{d/n})$ with high probability, where $n$ represents the training prompt size in the high signal-to-noise ratio (SNR) regime. Moreover, we derive in-context excess risk bounds of order $\mathcal{O}(L/\sqrt{B})$ for the case of two mixtures, where $B$ denotes the number of training prompts, and $L$ represents the number of attention layers. The dependence of $L$ on the SNR is explicitly characterized, differing between low and high SNR settings. We further analyze the training dynamics of transformers with single linear self-attention layers, demonstrating that, with appropriately initialized parameters, gradient flow optimization over the population mean square loss converges to a global optimum. Extensive simulations suggest that transformers perform well on this task, potentially outperforming other baselines, such as the Expectation-Maximization algorithm.
The paper demonstrates the existence of a transformer architecture capable of emulating the gradient EM algorithm for learning mixture of linear regression models.
It establishes rigorous error and excess risk bounds along with convergence guarantees under both low and high signal-to-noise regimes.
The study analyzes pretraining sample complexity and validates theoretical predictions through extensive simulations in varied settings.
In-context Learning with Transformers for Mixture of Linear Regressions
The paper "In-context Learning for Mixture of Linear Regressions: Existence, Generalization and Training Dynamics" (2410.14183) explores the in-context learning (ICL) capabilities of transformers when applied to mixture of linear regression (MoR) problems. The work provides theoretical guarantees for transformers' ability to learn MoR models, including error bounds and excess risk analysis. Additionally, it analyzes the sample complexity of pretraining such transformers.
Problem Setup and Contributions
The paper addresses the MoR problem, which is widely used for handling data heterogeneity in applications such as federated learning and collaborative filtering. Specifically, it considers a linear MoR model where data samples (xi,yi) follow the equation yi=⟨βi,xi⟩+vi, with vi being observation noise and βi being an unknown regression vector drawn from a set of K distinct regression vectors {βk∗}k=1K. The goal is to predict the label yn+1 for a new test sample xn+1 in a meta-learning setting.
The key contributions of this work are:
Existence of Transformers for MoR: It demonstrates the existence of a transformer architecture capable of learning MoR models by implementing the Expectation-Maximization (EM) algorithm. The transformer performs multiple gradient ascent steps during each M-step of the EM algorithm. The paper provides error bounds on the transformer's ability to approximate the oracle predictor in both low and high signal-to-noise ratio (SNR) regimes. The results are extended to K-component mixture models for finite K in the high-SNR setting.
Excess Risk Bounds: The paper establishes an excess risk bound for the constructed transformer, demonstrating its ability to achieve low excess risk under population loss conditions.
Pretraining Analysis: It analyzes the sample complexity associated with pretraining these transformers using a limited number of ICL training instances.
Convergence Analysis of Gradient EM: The work derives convergence results with statistical guarantees for the gradient EM algorithm applied to a two-component mixture of regression models, where the M-step involves T steps of gradient ascent, extending the analysis to the multi-component case.
Theoretical Framework
The paper considers an attention-only transformer, TFθ(⋅), which is a composition of L self-attention layers:
where ti:=1{i<n+1} is the indicator for the training examples. The prediction y^n+1 is derived from the (d+1,n+1)-th entry of H~, denoted as y^n+1=ready(H~):=(h~n+1)d+1.
The performance of the transformer depends on the SNR, $\eta = {\|\beta^{*}\|_{2}/{\vartheta}$. The paper defines a threshold order of SNR as O(fn,d,δ(41,1,0,0,21))=O(dlog2(n/δ)/n)1/4). High SNR means the order of η is greater than this threshold, while low SNR means it is smaller.
A central theorem (Theorem 2.1) demonstrates the existence of a transformer that can implement the gradient EM algorithm. The prediction error $\Delta_{y}\coloneqq |\operatorname{read}_{y}\big(\mathrm{TF}(H)\big)-x_{n+1}^{\top}\beta^{\textsf{OR}|$ is bounded as:
A generalization bound for pretraining (Theorem 2.3) provides insights into the sample complexity needed to pretrain the transformer with a limited number of ICL training instances.
Transformer Implementation of the Gradient-EM Algorithm
The paper shows that the transformer implements the EM algorithm internally, using gradient descent (GD) in each M-step. It leverages the result from \cite{bai2023transformers} that attention layers can implement one-step GD for a certain class of loss functions. Specifically, the paper demonstrates that the loss function minimized in each M-step is approximable by a sum of ReLUs, which is a requirement for applying the result from \cite{bai2023transformers}.
The EM algorithm involves an E-step and an M-step. In the E-step, the transformer computes the weights wβ(t)(xi,yi. In the M-step, the transformer performs T steps of GD to maximize the expected log-likelihood. The paper provides lemmas (3.1 and 3.2) that guarantee the existence of transformers capable of performing the E-step and M-step, respectively.
Extension to Multi-Component Mixtures
The results are extended to MoR problems with K≥3 components. The transformer implements E-steps and computes the conditional probabilities γij(t+1) using scalar product, linear transformation, and softmax operations. It then uses T attention layers to implement gradient descent for each component. Theorem 4.1 provides prediction error bounds for the multi-component case under a stricter SNR condition.
Empirical Validation
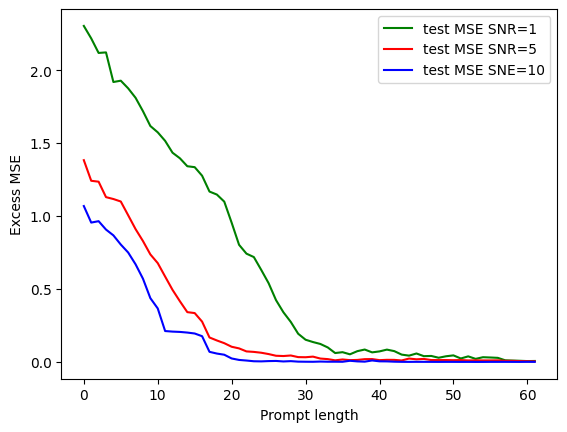
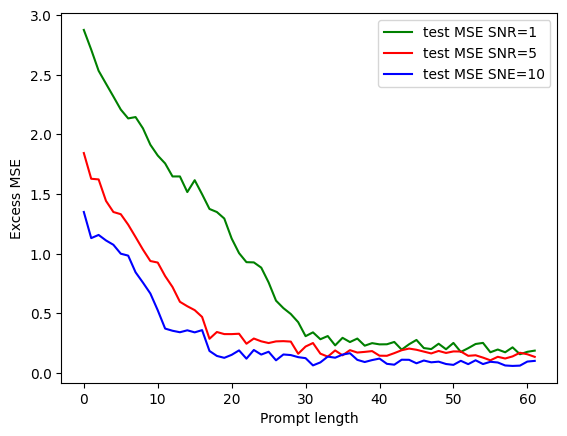
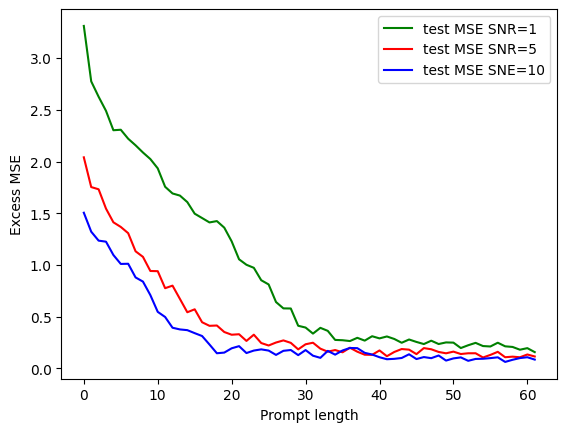
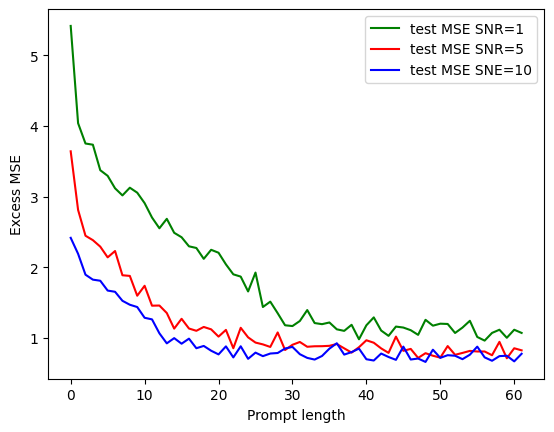
The paper presents simulation results to validate the theoretical findings. The experiments involve training transformers with Adam on prompts with varying numbers of components, SNRs, and prompt lengths. The results show that:
Transformers perform better with higher SNR.
Sufficient prompt length is needed to stabilize performance.
Increasing the number of components generally increases the excess test MSE.
Increasing the hidden dimension helps improve learning.
Increasing the dimension d of the input samples significantly raises the excess test MSE.
The figure above shows a plot of excess testing risk of the transformer with two components versus the prompt length with different SNRs
Implications and Future Directions
This work provides a theoretical foundation for understanding how transformers can perform ICL for MoR problems. The results suggest several promising directions for future research:
Looped Transformers: Investigating the use of looped transformers to reduce architectural complexity.
Training Dynamics: Understanding the training dynamics of transformers for linear MoR problems.
Non-linear MoR Models: Extending the results to general non-linear MoR models.
Conclusion
The paper makes significant contributions to the theoretical understanding of ICL with transformers for MoR problems. By demonstrating that transformers can implement the EM algorithm internally and providing theoretical guarantees for their performance, this work opens up new avenues for research in meta-learning and ICL.
“Emergent Mind helps me see which AI papers have caught fire online.”
Philip
Creator, AI Explained on YouTube
Sign up for free to explore the frontiers of research
Discover trending papers, chat with arXiv, and track the latest research shaping the future of science and technology.Discover trending papers, chat with arXiv, and more.