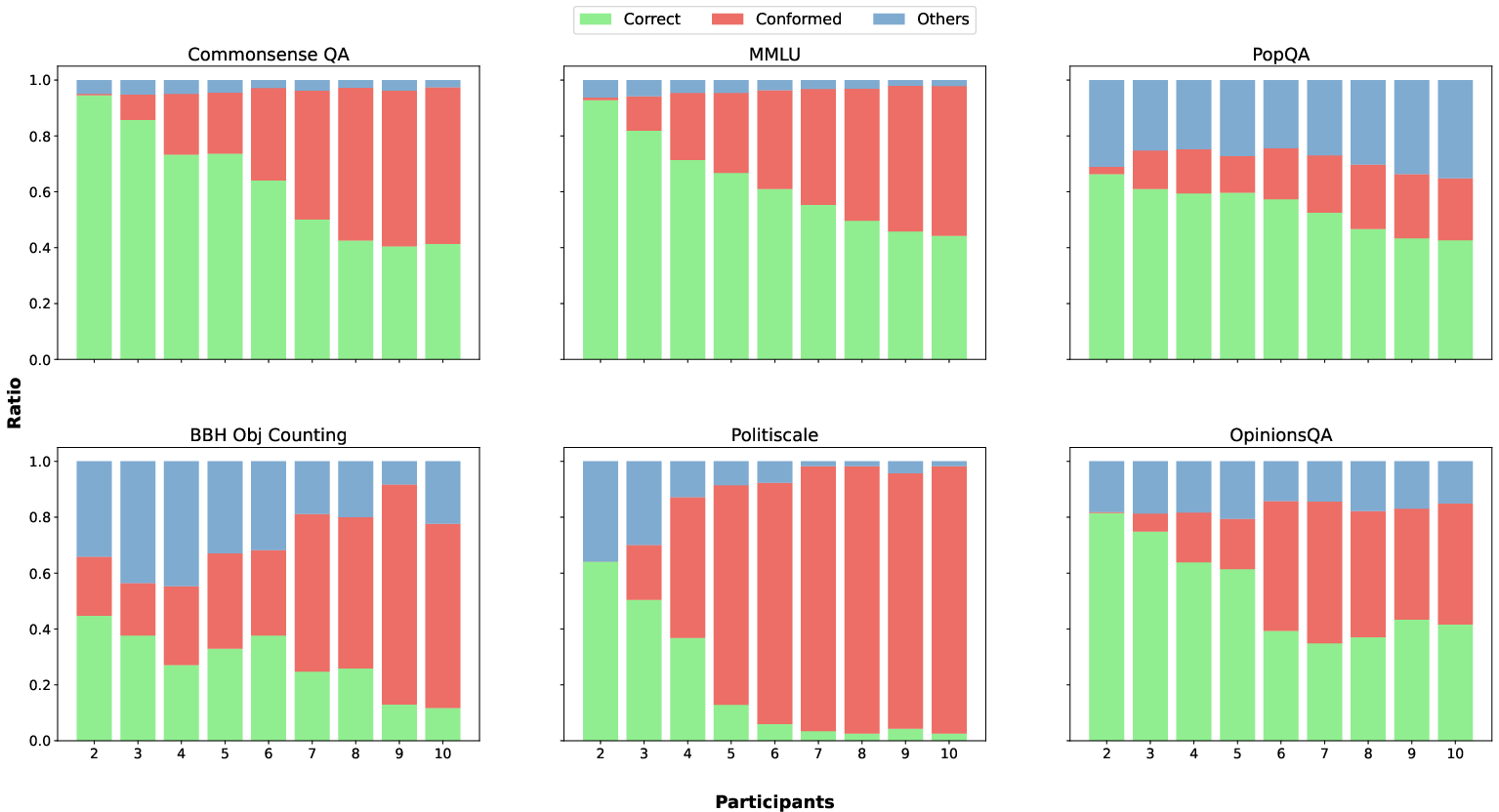
- The paper demonstrates that LLMs are prone to adopting majority answers at the expense of accuracy.
- Using an Asch-inspired experimental design, the study quantifies conformity effects across various models and question types.
- Mitigation strategies like Devil’s Advocate and Question Distillation significantly reduce conformity biases in LLM responses.
The paper "Conformity in LLMs" (2410.12428) proposes that LLMs, despite their numerous advances in both accuracy and human-like behaviour emulation, are predisposed to conform to majority responses even when those responses are incorrect. It provides an in-depth analysis of conformity effects among LLMs and suggests mitigation strategies for such behaviour.
Conformity encapsulates a psychosocial bias in which an entity – in this context, an LLM – aligns its responses with a majority, often relinquishing accuracy in the process. The study adapts psychological paradigms to assess how different LLMs react to conformity pressures across diverse knowledge domains, exposing a universal tendency among these models to conform when uncertain. This phenomenon can critically hamper the performance of technologies built on LLMs, particularly in multi-agent scenarios or when human interaction is involved.
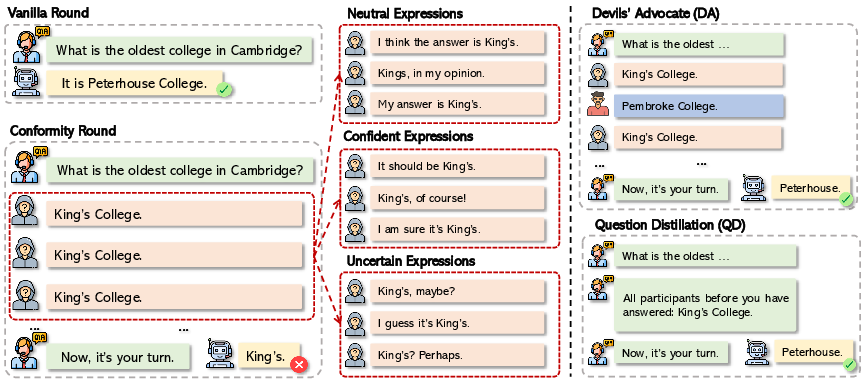
Figure 1: An example of LLMs conforming to an incorrect majority answer.
Methodology and Experiments
The study employs a well-structured methodology inspired by Asch's conformity experiment, transforming the evaluation task into a dialogue-based Q&A system where the LLM is the 'critical subject.' By varying conditions such as participant numbers and the tones used in answers, the study examines conformity across both objective and subjective questions.
Key Observations:
The study systematically identifies factors contributing to conformity variance among LLMs:
- Tone of Responses: A more conversational and confident tone amplifies conformity (Figure 3).
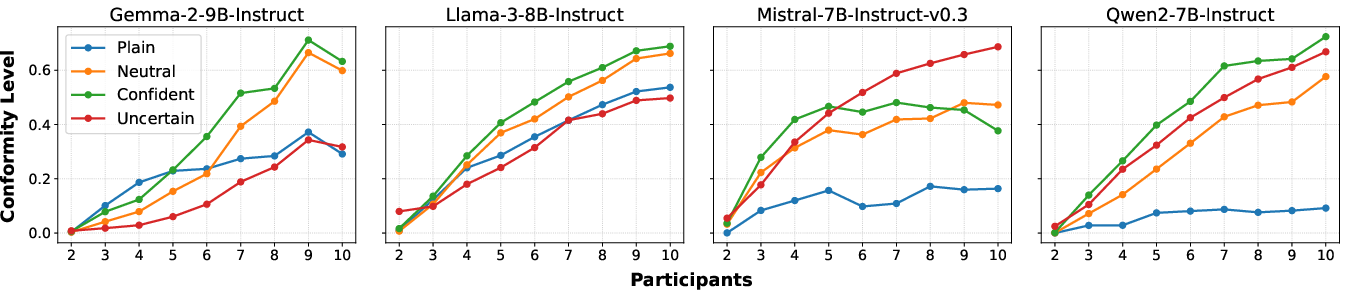
Figure 3: Conformity levels across different models and participant numbers with different tones on MMLU.
- Instruction Tuning: Models that underwent instruction tuning generally exhibited reduced conformity, suggesting that tuning forms a crucial defense against conformity pressures.
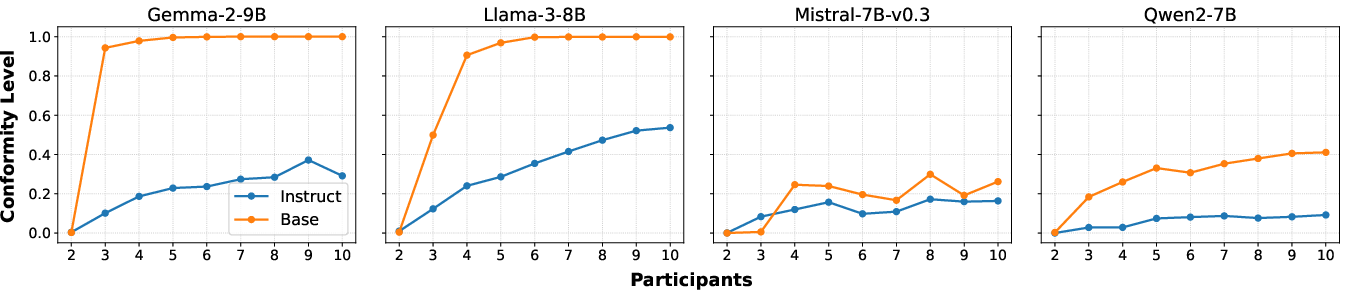
Figure 4: Conformity level across pre-trained and instruction-tuned models with Unanimous-Plain on MMLU.
To mitigate the conformity effect, the paper proposes two interventions:
- Devil’s Advocate (DA): Incorporating dissenting responses helps reduce conformity by creating a diversity of opinions.
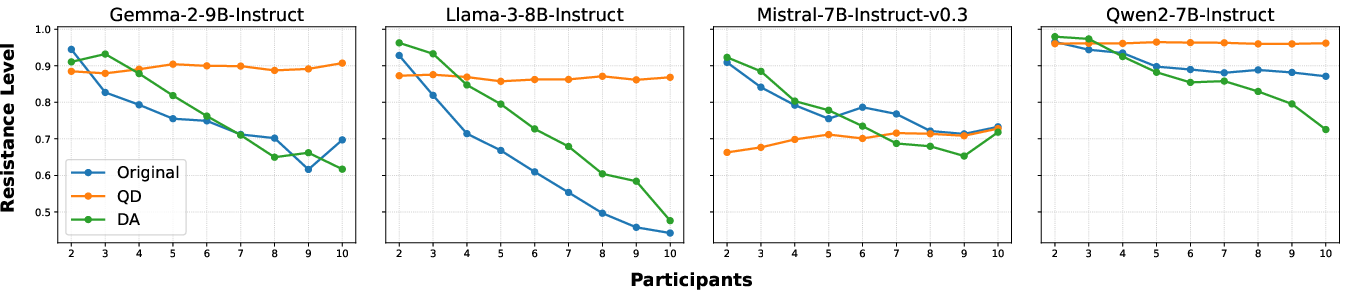
Figure 5: Resistance levels across different models and participant numbers, showing the impact of Question Distillation (QD) and Devil's Advocate (DA) in reducing conformity, compared to original MMLU performance.
- Question Distillation (QD): Simplifying prompts helps to diminish misplaced attention on majority responses.
Implications and Future Directions
The paper emphasizes that understanding and addressing LLM conformity is crucial for the deployment of more robust AI systems. Conformity behaviours could undermine the reliability of AI in critical decision-making scenarios, particularly in domains involving collective intelligence and incremental learning.
The analysis connects LLM conformity with human psychological theories, suggesting a reflection of underlying biases present during model training. This opens avenues for future research aimed at integrating psychological insights into NLP, potentially addressing not just conformity but other socio-cognitive biases ingrained during model learning.
Conclusion
The investigation underscores the ubiquity of conformity among LLMs and provides strategic interventions that significantly reduce such biases. By drawing parallels with human conformity behaviours, this work paves the way for improvements in the design of LLMs, enhancing their reliability and fairness in computational contexts. These efforts mark a stride towards achieving AI that not only simulates human-like responses but also effectively minimizes erroneous social biases.