- The paper demonstrates that applying image restoration methods frame-by-frame leads to temporal artifacts due to misalignment and GAN loss biases.
- It introduces a Temporal Consistency Network with alignment smoothing that leverages cross-attended transformer layers to enhance temporal stability while preserving fine facial details.
- Benchmarking on the RFV-LQ dataset reveals improved restoration quality and speed, setting new standards for video-based face restoration evaluation.
Analysis and Benchmarking of Extending Blind Face Image Restoration to Videos
Introduction
The paper presents a comprehensive study on the extension of blind face image restoration (FIR) algorithms to the domain of face video restoration (FVR). While FIR methods have achieved notable success in recovering high-quality facial details from degraded images, their direct application to videos introduces unique challenges, primarily due to the lack of temporal consistency and the presence of alignment-induced artifacts. The authors address the absence of a standardized benchmark for real-world low-quality face videos by introducing RFV-LQ, a curated dataset that enables rigorous evaluation and comparison of both image-based and video-based restoration methods. The study systematically analyzes the strengths and limitations of current approaches and proposes a novel Temporal Consistency Network (TCN) with alignment smoothing to mitigate temporal artifacts while preserving restoration quality.
Benchmarking and Systematic Analysis
The RFV-LQ dataset comprises 329 real-world degraded face video tracks, extracted from diverse sources such as old talk shows, TV series, and movies. The dataset is constructed using robust face detection, tracking, and identity verification pipelines to ensure high-quality, diverse samples.
Qualitative and quantitative comparisons reveal that state-of-the-art image-based FIR methods (e.g., GFP-GAN, RestoreFormer++, CodeFormer) outperform video-based methods (e.g., EDVR, BasicVSR-GAN) in terms of restoration quality, particularly in recovering fine facial details such as teeth, glasses, and eyes.




















Figure 1: Qualitative comparison between video-based and image-based restoration methods, highlighting superior detail recovery by image-based approaches.
However, standard metrics such as FID are insufficient for capturing perceptual quality in critical facial regions. The authors introduce component-based FIDs (FID-Eyes, FID-Nose, FID-Mouth, FID-Hair), which provide a more accurate assessment of restoration quality in key facial components.
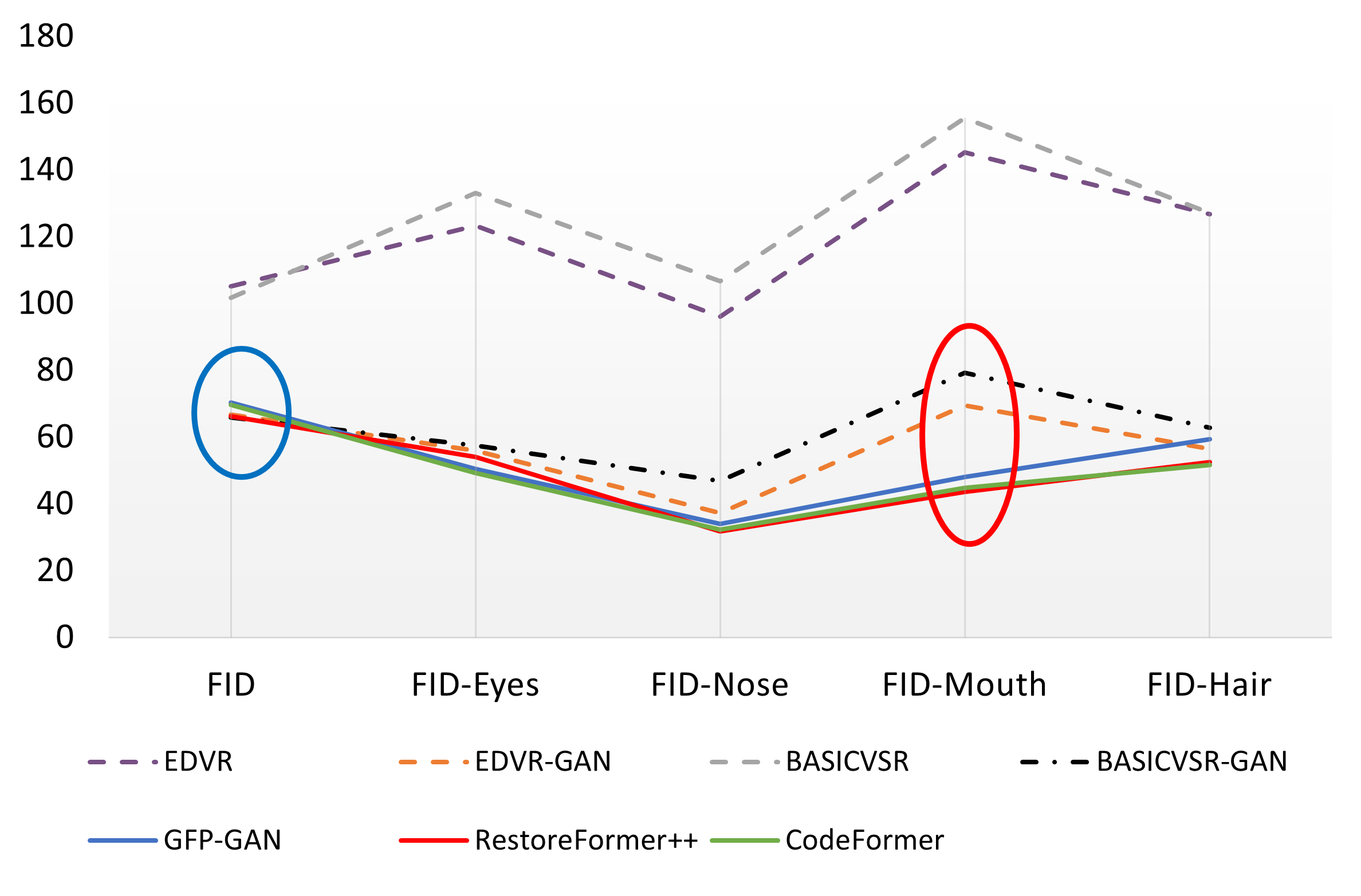
Figure 2: Component FIDs demonstrate the superiority of image-based methods in restoring specific facial regions, especially the mouth.
Despite their advantages, image-based methods exhibit pronounced temporal artifacts when applied frame-by-frame to videos. These manifest as jitters in facial components and noise-shape flickers between frames, as visualized through temporal stacking and warping error maps.







Figure 3: Visualization of jitters in facial components across frames, with image-based methods showing significant instability.







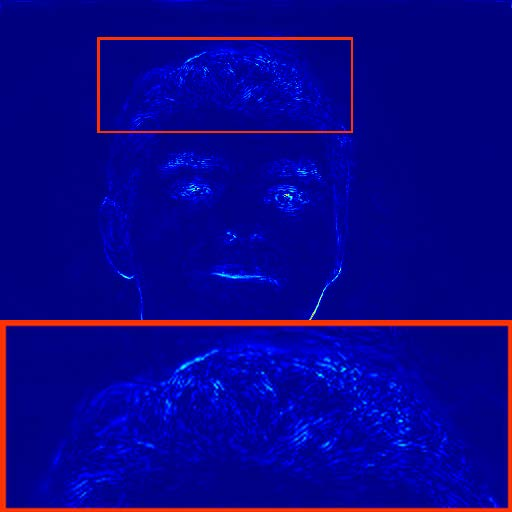

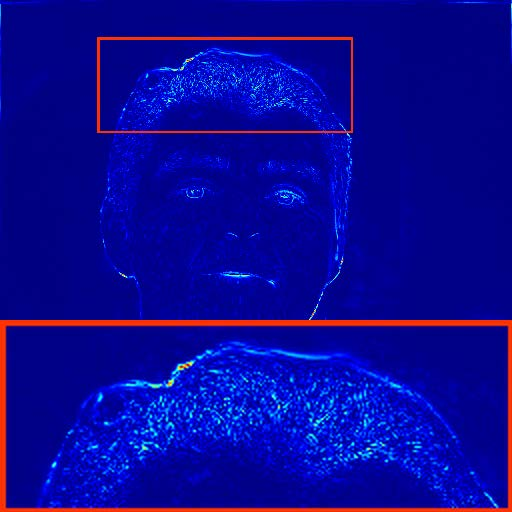
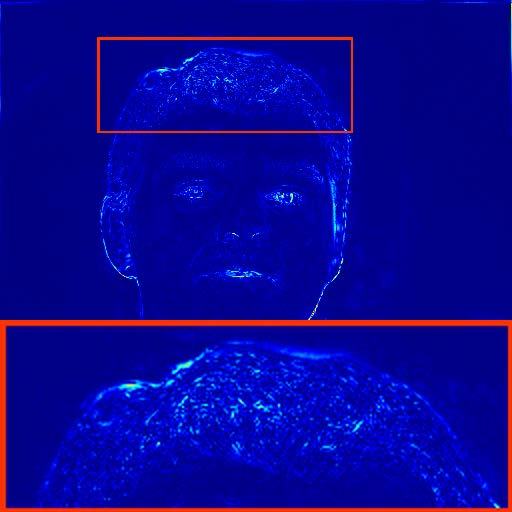

Figure 4: Warping error maps reveal noise-shape flickers in restored videos, particularly for methods employing GAN loss.
The analysis attributes these artifacts to three main factors: (1) the use of GAN loss, (2) the lack of temporal modeling, and (3) biases introduced by face alignment procedures. Notably, the alignment bias is shown to induce artificial landmark shifts, resulting in perceptible flickers even when the underlying facial motion is minimal.







Figure 5: Face alignment bias leads to landmark inconsistencies and restoration artifacts between consecutive frames.
Temporal Consistency Network and Alignment Smoothing
To address the identified challenges, the authors propose a two-pronged solution:
- Alignment Smoothing: By averaging detected facial landmarks across neighboring frames, the method reduces alignment-induced bias, leading to more stable facial component trajectories and mitigating jitters.
- Temporal Consistency Network (TCN): TCN is a lightweight, plug-and-play module based on Cross-Attended Swin Transformer Layers (CASTL). It is integrated into the decoder of existing FIR models, injecting temporal information from previous frames into the restoration process. This design preserves the high restoration quality of FIR models while enhancing temporal consistency.
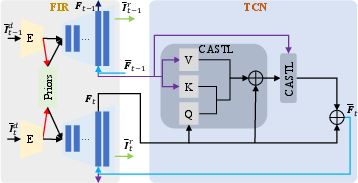
Figure 6: TCN framework integrates temporal modeling into FIR pipelines, leveraging cross-attention between current and previous frame features.
The training strategy involves freezing the weights of the original FIR models and training only the TCN on high-quality video data (VFHQ-800), filtered to minimize motion blur. The loss function combines pixel-wise, perceptual, adversarial, and temporal consistency terms.
Experimental Results
Extensive experiments on RFV-LQ demonstrate that the proposed method achieves a superior balance between restoration quality and temporal consistency compared to prior temporal consistency approaches (e.g., DVP, neural filtering with flawed atlas). Quantitative results show that while all methods reduce temporal artifacts (lower MSI and warping error), the proposed TCN maintains higher component FID scores, indicating better preservation of facial details.
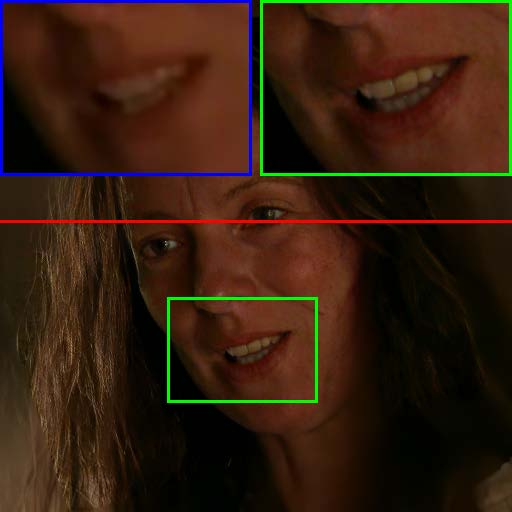
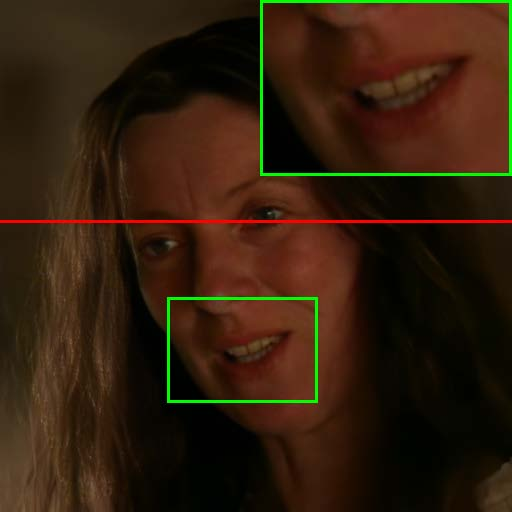
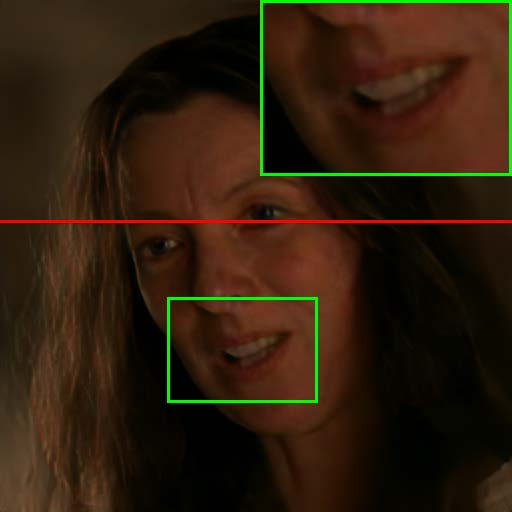

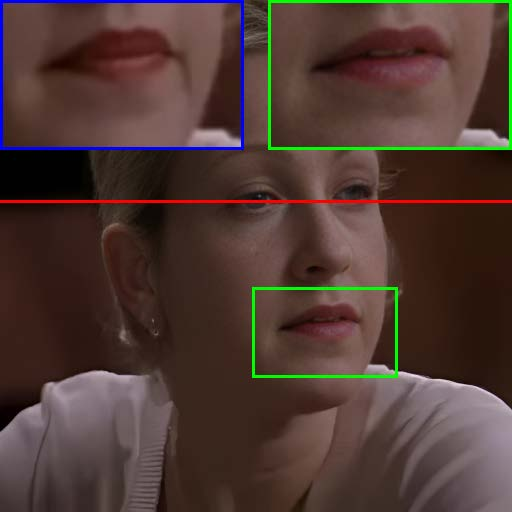
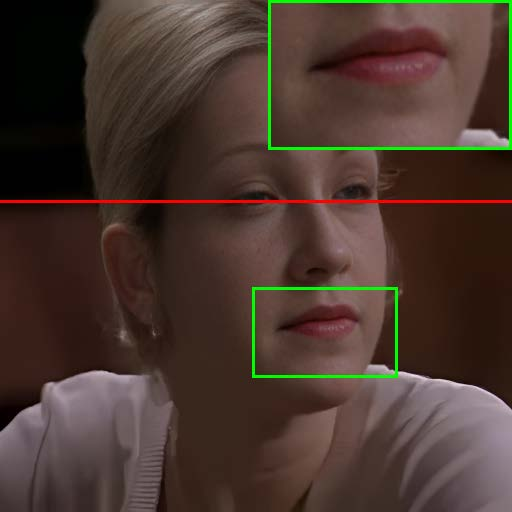
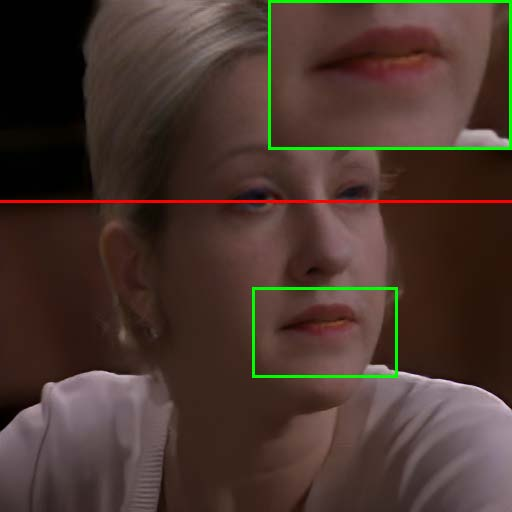
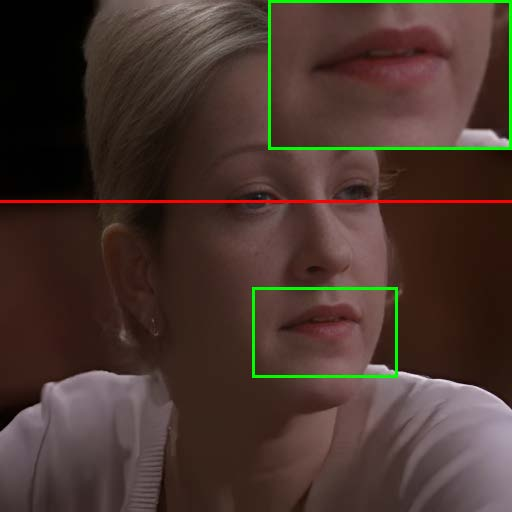















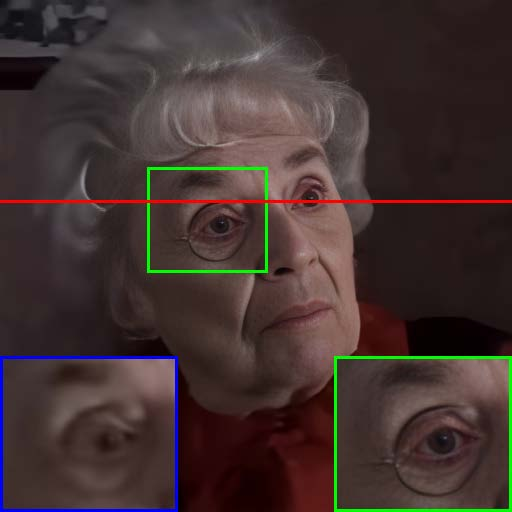
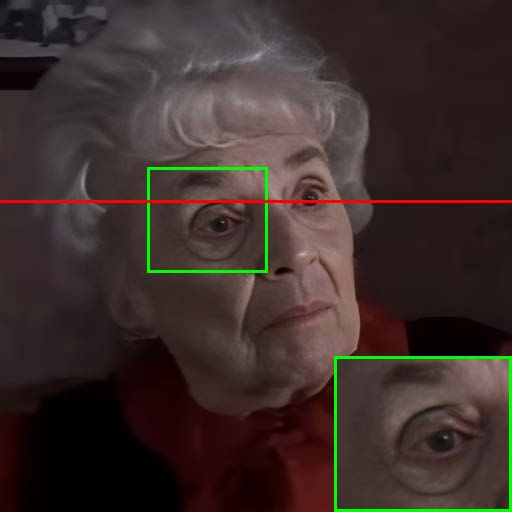

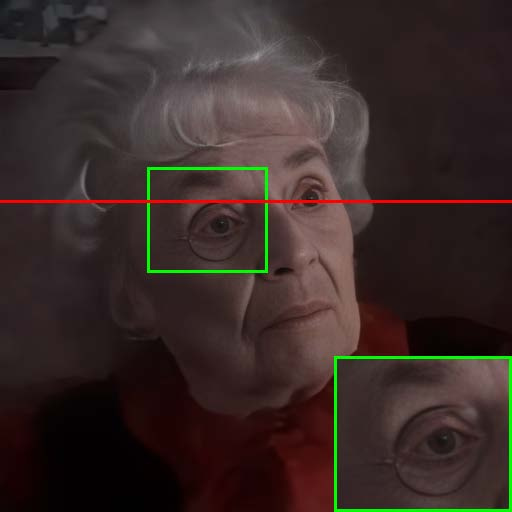










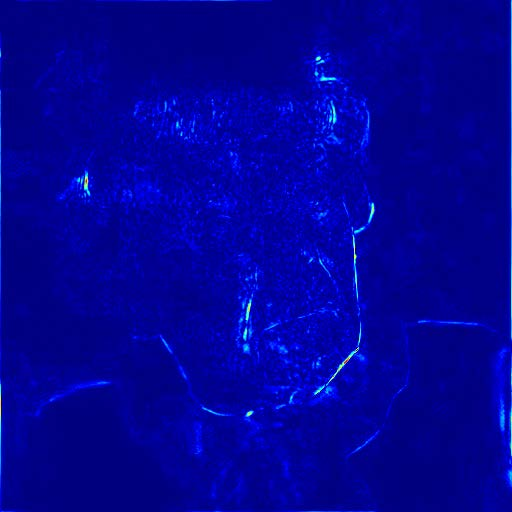

Figure 7: Visual comparison of restored results and temporal artifact reduction across methods, with TCN achieving optimal trade-off.
Ablation studies on the number of frames used for alignment smoothing (k) and the resolution at which TCN is applied reveal that k=3 and integration at 256×256 resolution yield the best results in terms of both quality and stability.





Figure 8: Temporal stacking visualization for varying k values, showing reduced jitters with increased smoothing.

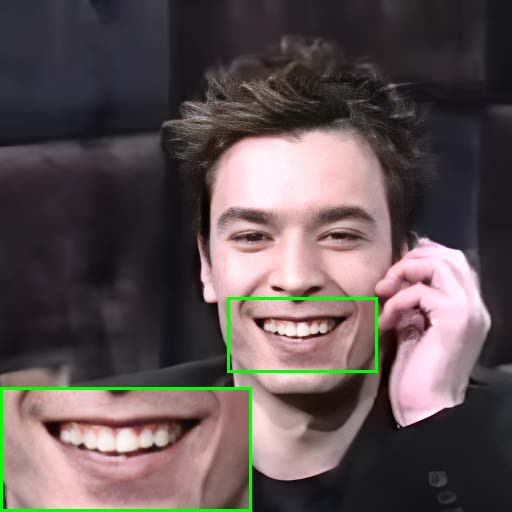
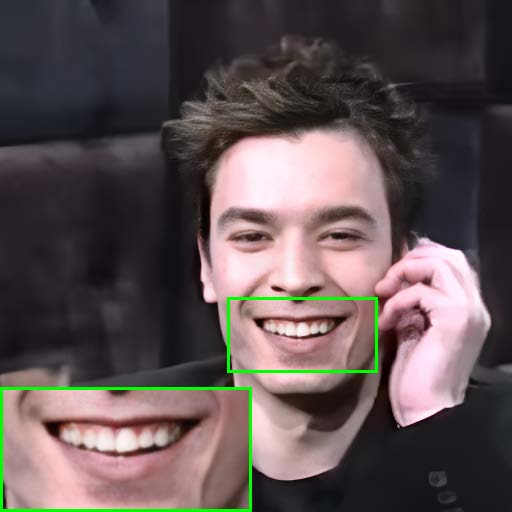

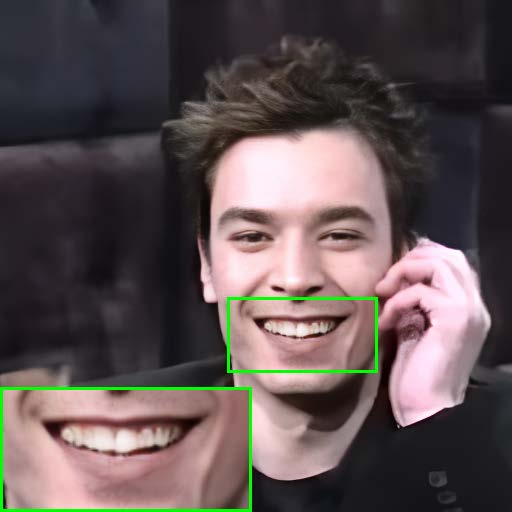





Figure 9: Warping error maps at different TCN integration resolutions, highlighting the trade-off between detail preservation and flicker reduction.
Efficiency analysis indicates that the proposed method is significantly faster than previous approaches, processing 100-frame videos in under 39 seconds on a Tesla T4 GPU, compared to 100–300 seconds for competing methods.
Implications and Future Directions
The study establishes that FIR methods, when extended to videos, require explicit temporal modeling and robust alignment strategies to avoid perceptual artifacts. The introduction of component-based FIDs sets a new standard for evaluating restoration quality in critical facial regions. The TCN framework demonstrates that transformer-based temporal modeling can be efficiently integrated into existing pipelines, offering a practical solution for real-world face video restoration.
Future research may explore:
- End-to-end training of FIR+TCN models on large-scale, high-quality video datasets to further close the gap between image and video restoration quality.
- Advanced alignment techniques leveraging 3D facial priors or self-supervised temporal consistency objectives.
- Application of TCN-like modules to other video restoration tasks, such as deblurring, denoising, and artifact removal, where temporal consistency is critical.
Conclusion
This paper provides a rigorous analysis of the extension of blind face image restoration algorithms to video, identifying key challenges and proposing effective solutions. The Temporal Consistency Network and alignment smoothing strategy enable high-quality, temporally stable face video restoration, validated by both qualitative and quantitative benchmarks. The work sets a foundation for future research in video-based face restoration and highlights the importance of temporal modeling and robust evaluation metrics in low-level vision tasks.