- The paper introduces DP-TempCoh, a novel framework integrating spatial-temporal-aware content prediction and motion prior-based statistics modulation to restore degraded face videos.
- It leverages discrete visual and motion priors to achieve high fidelity and seamless temporal transitions, outperforming state-of-the-art methods as measured by PSNR, LPIPS, and FID.
- An ablation study confirms the effectiveness of each module, emphasizing DP-TempCoh’s capability in maintaining identity preservation and realistic temporal coherence.
Discrete Prior-based Temporal-coherent Content Prediction for Blind Face Video Restoration
This essay provides a detailed overview of the paper "Discrete Prior-based Temporal-coherent Content Prediction for Blind Face Video Restoration" (2501.09960). The core objective of the paper is to effectively address the challenge of restoring face video sequences subjected to unknown degradations while ensuring temporal coherence through the utilization of discrete visual and motion priors.
Introduction
Blind Face Video Restoration (BFVR) involves recovering high-quality face sequences from degraded videos with unknown degradation patterns. The primary pursuit of BFVR is maintaining dynamic, temporal coherence without sacrificing fidelity of facial attributes. The introduction of DP-TempCoh tackles this challenge by leveraging discrete priors, synthesizing visually appealing results (Figure 1).

Figure 1: An example to visually compare the proposed DP-TempCoh with the competing image/video restoration methods: DiffBIR and FMA-Net, in restoration quality and temporal coherence.
Proposed Method
The paper introduces DP-TempCoh which integrates two novel modules: a visual prior-based spatial-temporal-aware content prediction module and a motion prior-based statistics modulation module. The overall architecture succinctly visualizes these components interacting in Figure 2, enhancing restoration through a structured transformation process.
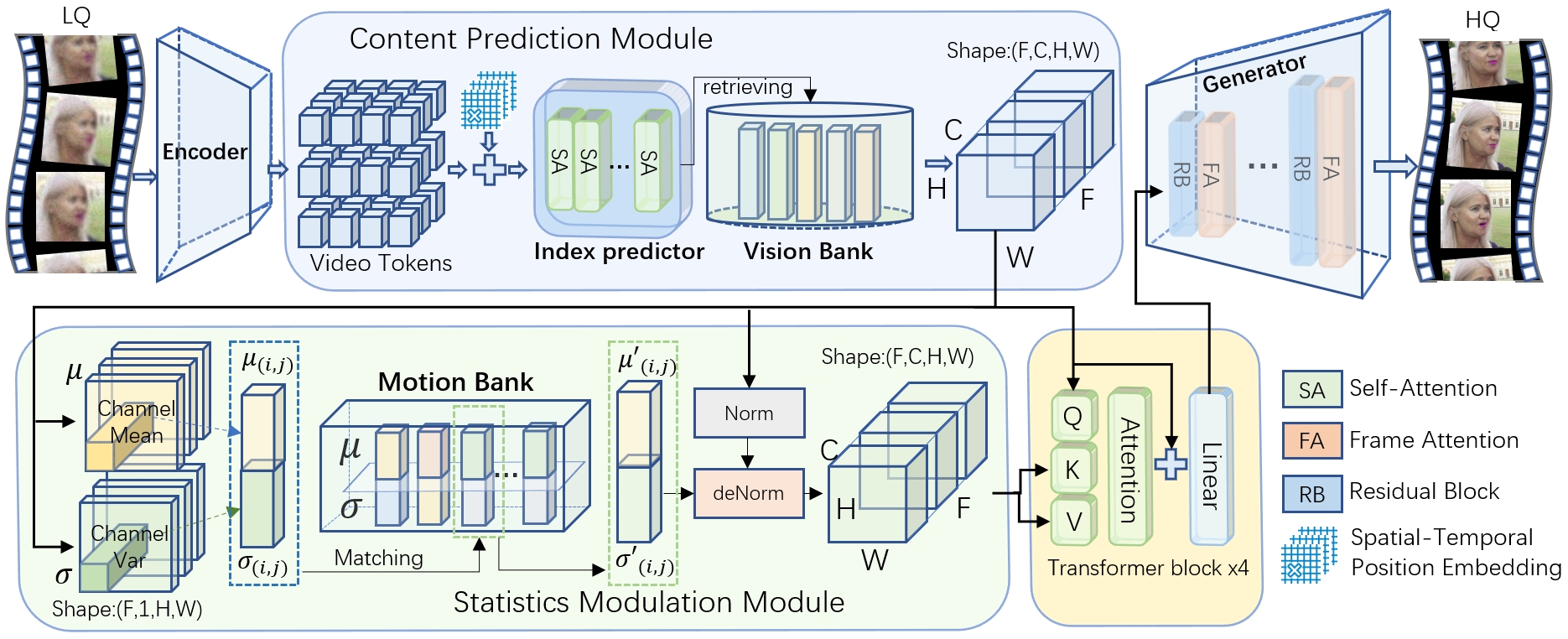
Figure 2: Overview of the proposed DP-TempCoh framework. An encoder E extracts the tokens z from a degraded face video segment.
Spatial-temporal-aware Content Prediction
This module generates high-quality content by predicting latent features from discrete visual priors. The prediction process leverages both spatial and temporal interactions across degraded video tokens to match high-quality latent banks effectively. The incorporation of self-attention mechanisms allows for nuanced contextual feature extraction.
Motion Prior-based Statistics Modulation
Improving temporal coherence entails managing cross-frame statistical properties like mean and variance. The paper details the construction of a statistics bank of motion priors, providing a robust platform for modulation of predicted content to achieve seamless temporal transitions.
Experiments
The paper reports extensive quantitative and qualitative evaluations showcasing DP-TempCoh’s superiority over state-of-the-art face restoration techniques. Quantitative metrics like PSNR, LPIPS, and FID demonstrate this model's efficacy in producing high-fidelity video outputs. The inclusion of a user study further underscores DP-TempCoh’s ability to deliver perceptually coherent results.
Ablation Study
An ablation study was conducted to examine individual module contributions, confirming the enhancement provided by the spatial-temporal-aware prediction and motion statistics modulation components as seen in Table 1 and Figure 3.

Figure 3: Visual comparison between DP-TempCoh and ablative models(defined in Table 1) on VFHQ-Test-Deg video.
Comparison with State-of-the-Arts
DP-TempCoh outperformed existing BFVR approaches across benchmark datasets (Table 2), delivering superior identity preservation and temporal consistency.

Figure 4: Visual comparison between DP-TempCoh and the competing methods on representative frames of in-the-wild videos.
Conclusion
Discrete Prior-based Temporal-Coherent Content Prediction exhibits enhanced recovery of high-fidelity, temporally coherent face videos under unknown degradation. Subsequent advancements could explore application across broader video types beyond faces, incorporating diverse textures and situational prompts. The synthesis of spatial-temporal and motion prior interactions defines a promising trajectory for future video restoration research.

