How Good Are LLMs for Literary Translation, Really? Literary Translation Evaluation with Humans and LLMs
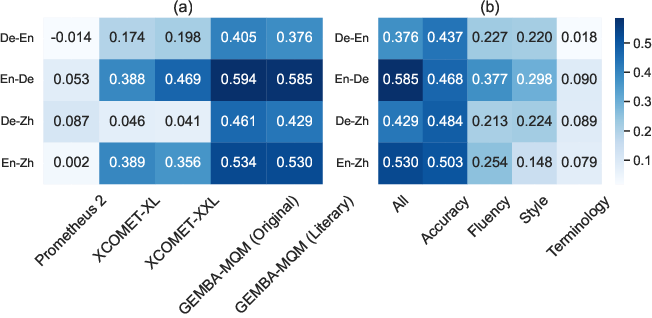
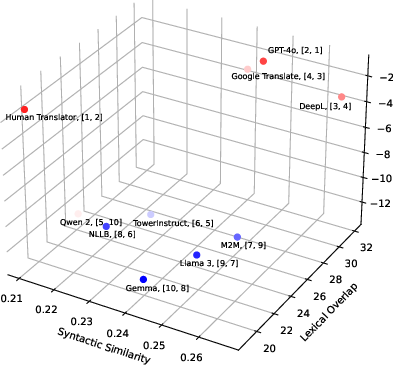
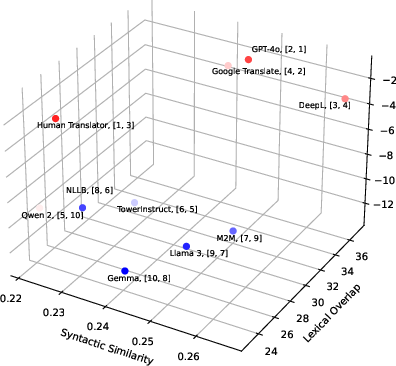
Abstract: Recent research has focused on literary machine translation (MT) as a new challenge in MT. However, the evaluation of literary MT remains an open problem. We contribute to this ongoing discussion by introducing LITEVAL-CORPUS, a paragraph-level parallel corpus containing verified human translations and outputs from 9 MT systems, which totals over 2k translations and 13k evaluated sentences across four language pairs, costing 4.5k C. This corpus enables us to (i) examine the consistency and adequacy of human evaluation schemes with various degrees of complexity, (ii) compare evaluations by students and professionals, assess the effectiveness of (iii) LLM-based metrics and (iv) LLMs themselves. Our findings indicate that the adequacy of human evaluation is controlled by two factors: the complexity of the evaluation scheme (more complex is less adequate) and the expertise of evaluators (higher expertise yields more adequate evaluations). For instance, MQM (Multidimensional Quality Metrics), a complex scheme and the de facto standard for non-literary human MT evaluation, is largely inadequate for literary translation evaluation: with student evaluators, nearly 60% of human translations are misjudged as indistinguishable or inferior to machine translations. In contrast, BWS (BEST-WORST SCALING), a much simpler scheme, identifies human translations at a rate of 80-100%. Automatic metrics fare dramatically worse, with rates of at most 20%. Our overall evaluation indicates that published human translations consistently outperform LLM translations, where even the most recent LLMs tend to produce considerably more literal and less diverse translations compared to humans.
- AI@Meta. 2024. Llama 3 model card.
- Nabil Al-Awawdeh. 2021. Translation between creativity and reproducing an equivalent original text. Psychology and Education Journal, 58(1):2559–2564.
- Tower: An open multilingual large language model for translation-related tasks. Preprint, arXiv:2402.17733.
- Jonas Belouadi and Steffen Eger. 2023. ByGPT5: End-to-end style-conditioned poetry generation with token-free language models. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7364–7381, Toronto, Canada. Association for Computational Linguistics.
- Missing information, unresponsive authors, experimental flaws: The impossibility of assessing the reproducibility of previous human evaluations in NLP. In Proceedings of the Fourth Workshop on Insights from Negative Results in NLP, pages 1–10, Dubrovnik, Croatia. Association for Computational Linguistics.
- Findings of the WMT 2023 shared task on quality estimation. In Proceedings of the Eighth Conference on Machine Translation, pages 629–653, Singapore. Association for Computational Linguistics.
- FastKASSIM: A fast tree kernel-based syntactic similarity metric. In Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, pages 211–231, Dubrovnik, Croatia. Association for Computational Linguistics.
- Yanran Chen and Steffen Eger. 2023. Menli: Robust evaluation metrics from natural language inference. Transactions of the Association for Computational Linguistics, 11:804–825.
- Evaluating diversity in automatic poetry generation. arXiv preprint arXiv:2406.15267.
- No language left behind: Scaling human-centered machine translation. arXiv preprint arXiv:2207.04672.
- Impact of translation workflows with and without MT on textual characteristics in literary translation. In Proceedings of the 1st Workshop on Creative-text Translation and Technology, pages 57–64, Sheffield, United Kingdom. European Association for Machine Translation.
- Training and meta-evaluating machine translation evaluation metrics at the paragraph level. In Proceedings of the Eighth Conference on Machine Translation, pages 996–1013, Singapore. Association for Computational Linguistics.
- Beyond english-centric multilingual machine translation. J. Mach. Learn. Res., 22(1).
- Experts, errors, and context: A large-scale study of human evaluation for machine translation. Transactions of the Association for Computational Linguistics, 9:1460–1474.
- Continuous measurement scales in human evaluation of machine translation. In Proceedings of the 7th Linguistic Annotation Workshop and Interoperability with Discourse, pages 33–41, Sofia, Bulgaria. Association for Computational Linguistics.
- Ana Guerberof-Arenas and Antonio Toral. 2022. Creativity in translation: Machine translation as a constraint for literary texts. Translation Spaces, 11(2):184–212.
- xcomet: Transparent Machine Translation Evaluation through Fine-grained Error Detection. Transactions of the Association for Computational Linguistics, 12:979–995.
- Damien Hansen and Emmanuelle Esperança-Rodier. 2022. Human-adapted mt for literary texts: Reality or fantasy? In NeTTT 2022, pages 178–190.
- BlonDe: An automatic evaluation metric for document-level machine translation. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 1550–1565, Seattle, United States. Association for Computational Linguistics.
- Marzena Karpinska and Mohit Iyyer. 2023. Large language models effectively leverage document-level context for literary translation, but critical errors persist. In Proceedings of the Eighth Conference on Machine Translation, pages 419–451.
- Prometheus 2: An open source language model specialized in evaluating other language models. arXiv preprint arXiv:2405.01535.
- Svetlana Kiritchenko and Saif Mohammad. 2017. Best-worst scaling more reliable than rating scales: A case study on sentiment intensity annotation. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 465–470, Vancouver, Canada. Association for Computational Linguistics.
- Tom Kocmi and Christian Federmann. 2023. GEMBA-MQM: Detecting translation quality error spans with GPT-4. In Proceedings of the Eighth Conference on Machine Translation, pages 768–775, Singapore. Association for Computational Linguistics.
- Waltraud Kolb. 2023. ‘i am a bit surprised’: Literary translation and post-editing processes compared. In Computer-Assisted Literary Translation, pages 53–68. Routledge.
- Kollektive-Intelligenz. 2024. Ki – aber wie? Übersetzertag 2024.
- Christoph Leiter and Steffen Eger. 2024. Prexme! large scale prompt exploration of open source llms for machine translation and summarization evaluation. arXiv preprint arXiv:2406.18528.
- The eval4nlp 2023 shared task on prompting large language models as explainable metrics. arXiv preprint arXiv:2310.19792.
- Multilingual denoising pre-training for neural machine translation. Transactions of the Association for Computational Linguistics, 8:726–742.
- LLMs as narcissistic evaluators: When ego inflates evaluation scores. In Findings of the Association for Computational Linguistics ACL 2024, pages 12688–12701, Bangkok, Thailand and virtual meeting. Association for Computational Linguistics.
- Using a new analytic measure for the annotation and analysis of mt errors on real data. In Proceedings of the 17th Annual conference of the European Association for Machine Translation, pages 165–172.
- Mqm-ape: Toward high-quality error annotation predictors with automatic post-editing in llm translation evaluators. arXiv preprint arXiv:2409.14335.
- Lieve Macken. 2024. Machine translation meets large language models: Evaluating ChatGPT’s ability to automatically post-edit literary texts. In Proceedings of the 1st Workshop on Creative-text Translation and Technology, pages 65–81, Sheffield, United Kingdom. European Association for Machine Translation.
- Ruth Martin. 2023. Reflections from an ai translation slam: (wo)man versus machine.
- Evgeny Matusov. 2019. The challenges of using neural machine translation for literature. In Proceedings of the Qualities of Literary Machine Translation, pages 10–19, Dublin, Ireland. European Association for Machine Translation.
- Mary L McHugh. 2012. Interrater reliability: the kappa statistic. Biochemia medica, 22(3):276–282.
- State of what art? a call for multi-prompt llm evaluation. Transactions of the Association for Computational Linguistics, 12:933–949.
- Monika Pfundmeier. Redaktion: Dorrit Bartel Nina George, André Hansen. 2023. Anwendungen von fortgeschrittener informatik und generativer systeme im buchsektor.
- Magdalena Nizioł. 2024. Künstliche intelligenz – gefahr oder hilfe für literarische Übersetzung?
- Salute the classic: Revisiting challenges of machine translation in the age of large language models. arXiv preprint arXiv:2401.08350.
- S Patro. 2015. Normalization: A preprocessing stage. arXiv preprint arXiv:1503.06462.
- Matt Post. 2018. A call for clarity in reporting BLEU scores. In Proceedings of the Third Conference on Machine Translation: Research Papers, pages 186–191, Brussels, Belgium. Association for Computational Linguistics.
- Llukan Puka. 2011. Kendall’s Tau, pages 713–715. Springer Berlin Heidelberg, Berlin, Heidelberg.
- Natália Resende and James Hadley. 2024. The translator’s canvas: Using LLMs to enhance poetry translation. In Proceedings of the 16th Conference of the Association for Machine Translation in the Americas (Volume 1: Research Track), pages 178–189, Chicago, USA. Association for Machine Translation in the Americas.
- Whence the 3 percent?: How far have we come toward decentering america’s literary preference? Global Perspectives, 5(1):93034.
- BLEURT: Learning robust metrics for text generation. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 7881–7892, Online. Association for Computational Linguistics.
- Bryan Stroube. 2003. Literary freedom: Project gutenberg. XRDS: Crossroads, The ACM Magazine for Students, 10(1):3–3.
- Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805.
- Gemma: Open models based on gemini research and technology. arXiv preprint arXiv:2403.08295.
- Exploring document-level literary machine translation with parallel paragraphs from world literature. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 9882–9902.
- Common flaws in running human evaluation experiments in NLP. Computational Linguistics, 50(2):795–805.
- Label Studio: Data labeling software. Open source software available from https://github.com/heartexlabs/label-studio.
- The riddle of (literary) machine translation quality. Tradumàtica tecnologies de la traducció, (21):129–159.
- Proceedings of the 1st Workshop on Creative-text Translation and Technology. European Association for Machine Translation, Sheffield, United Kingdom.
- Rob Voigt and Dan Jurafsky. 2012. Towards a literary machine translation: The role of referential cohesion. In Proceedings of the NAACL-HLT 2012 Workshop on Computational Linguistics for Literature, pages 18–25, Montréal, Canada. Association for Computational Linguistics.
- Findings of the WMT 2023 shared task on discourse-level literary translation: A fresh orb in the cosmos of LLMs. In Proceedings of the Eighth Conference on Machine Translation, pages 55–67, Singapore. Association for Computational Linguistics.
- (perhaps) beyond human translation: Harnessing multi-agent collaboration for translating ultra-long literary texts. arXiv preprint arXiv:2405.11804.
- GuoFeng: A benchmark for zero pronoun recovery and translation. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 11266–11278, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics.
- Gpt-4 vs. human translators: A comprehensive evaluation of translation quality across languages, domains, and expertise levels. arXiv preprint arXiv:2407.03658.
- Qwen2 technical report. arXiv preprint arXiv:2407.10671.
- Ran Zhang and Steffen Eger. 2024. Llm-based multi-agent poetry generation in non-cooperative environments. arXiv preprint arXiv:2409.03659.
- Bertscore: Evaluating text generation with bert. In International Conference on Learning Representations.
- Discoscore: Evaluating text generation with bert and discourse coherence. In Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, pages 3865–3883.
- More human than human: Llm-generated narratives outperform human-llm interleaved narratives. In Proceedings of the 15th Conference on Creativity and Cognition, pages 368–370.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.