- The paper introduces an innovative autoregressive model that generates segmentation masks as visual tokens by integrating textual cues and visual features.
- It presents a novel data annotation pipeline and the SA-OVRS dataset with over 2M annotated masks and 5,800+ unique open-vocabulary labels.
- Experimental results show that LlamaSeg outperforms existing models on benchmarks, delivering enhanced mask quality and boundary accuracy.
LlamaSeg: Autoregressive Mask Generation for Image Segmentation
The paper "LlamaSeg: Image Segmentation via Autoregressive Mask Generation" (2505.19422) introduces LlamaSeg, a novel visual autoregressive framework designed to unify various image segmentation tasks through natural language instructions. This approach reframes image segmentation as a visual generation problem, representing masks as discrete "visual tokens." A LLaMA-style Transformer predicts these tokens directly from image inputs, integrating segmentation tasks into autoregressive architectures via next-token prediction. To facilitate large-scale training, the authors introduce a data annotation pipeline and the SA-OVRS dataset, which contains 2M segmentation masks annotated with over 5,800 open-vocabulary labels or textual descriptions. Additionally, the paper proposes a composite metric combining Intersection over Union (IoU) with Average Hausdorff Distance (AHD) to evaluate mask quality more accurately.
Methodology
LlamaSeg's framework consists of a mask tokenizer and an autoregressive model (Figure 1). The mask tokenizer, based on VQGAN [esser2021taming], converts segmentation masks into discrete tokens. The autoregressive model, built on the LLaMA architecture [touvron2023llama, touvron2023llama2], takes encoded image sequences as input and generates mask tokens. Language instructions provide object cues, unifying general semantic segmentation and language-guided segmentation. The model concatenates textual and visual features into a unified sequence for simultaneous processing.
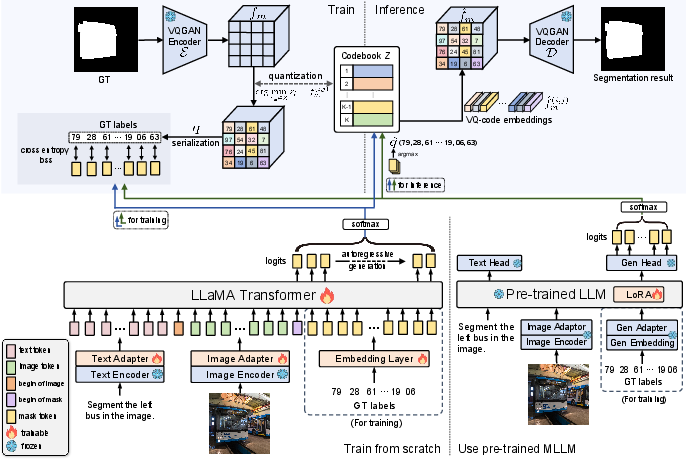
Figure 1: Overall framework of LlamaSeg, comprising a mask tokenizer and an autoregressive model, with GT labels used for training supervision.
For training, the ground truth mask is encoded into code indices, serving as targets for the LLaMA model. During inference, the generated mask tokens are decoded to produce the segmentation mask. The image and text features are extracted using frozen SigLIP2 [tschannen2025siglip] and projected to align with the LLaMA embedding dimension via trainable adaptors. Learnable separators distinguish between text, image, and mask tokens.
Data Annotation Pipeline
The authors address the limitations of existing segmentation datasets by introducing a new data annotation pipeline and the SA-OVRS dataset (Figure 2). This dataset includes 2M segmentation instances annotated with open-vocabulary labels or diverse textual descriptions, covering over 5,800 unique labels. The pipeline uses SA-1B [kirillov2023segment] dataset masks and employs Qwen2-VL-72B [wang2024qwen2] as the captioning model to generate open-vocabulary labels. GroundingDINO [liu2024grounding] then matches these labels with corresponding masks, using a rigorous matching and filtering algorithm to ensure data validity. The pipeline also generates unique textual descriptions for each mask, enhancing data diversity through referring and reasoning segmentation data.
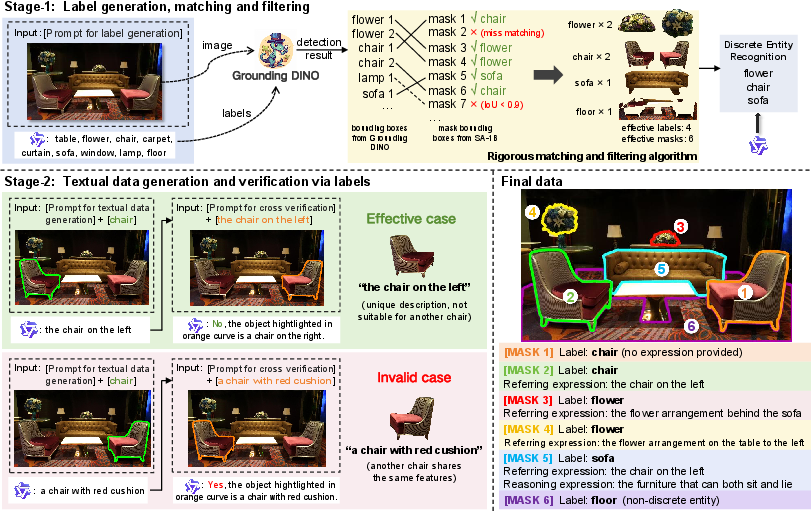
Figure 2: The two-stage data generation pipeline involves generating labels, matching them with masks, identifying discrete entities, and creating textual data based on the labels.
Experimental Results and Analysis
The model was evaluated on closed-set and open-vocabulary semantic segmentation tasks using mean IoU (mIoU), and on referring segmentation tasks using cumulative intersection over cumulative union (cIoU). To evaluate contour accuracy, the authors proposed average Hausdorff Distance (dAHD) under multi-level IoU thresholds. Experimental results demonstrate that LlamaSeg outperforms existing visual generative models across multiple benchmarks and yields more detailed segmentation masks (Figure 3).
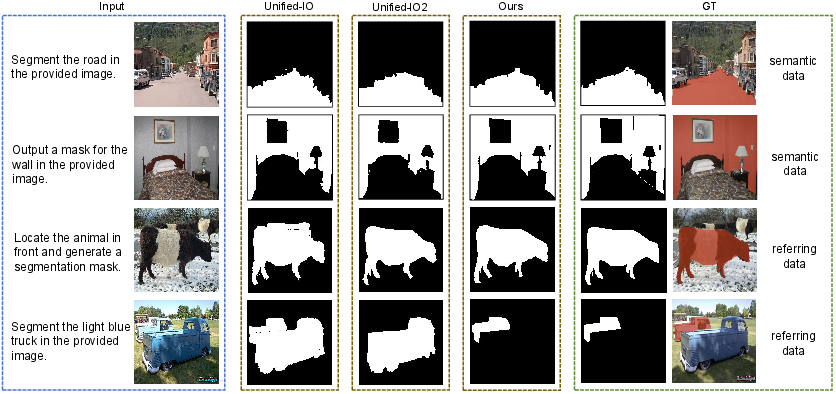
Figure 3: A visual comparison demonstrates LlamaSeg's superior mask quality and segmentation results compared to existing visual generative models.
Specifically, with 0.77B parameters, LlamaSeg outperforms Unified-IO by 10.6/3.8/11.8 on the ADE20K, COCOStuff, and PAS-20 datasets, respectively. Furthermore, LlamaSeg demonstrates superior alignment with ground truth contours, indicating accurate segmentation of object boundaries, as evidenced by lower mAHD values compared to Unified-IO models. Ablation studies on the mask tokenizer and decoding strategies further validate the effectiveness of the proposed approach. Analysis of attention maps reveals that the model can learn 2D spatial relationships from 1D tokens (Figure 4).
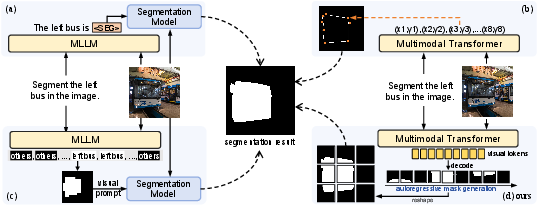
Figure 4: Different implementations of image segmentation in autoregressive frameworks, with visual tokens as masks in LlamaSeg.
Implications and Future Directions
The research demonstrates the potential of autoregressive models for fine-grained visual tasks with deterministic ground truth. The introduction of the SA-OVRS dataset addresses a critical need for large-scale, diverse segmentation data suitable for training autoregressive models. The composite evaluation metric, combining IoU and AHD, provides a more nuanced assessment of mask quality. Future research directions could explore the application of LlamaSeg to other vision tasks, further scaling the model and dataset, and investigating alternative mask tokenization strategies.

