- The paper introduces DSV-LFS, combining LLM-driven semantic prompts with dense visual matching to enhance few-shot segmentation.
- The approach employs a single-stage, end-to-end pipeline that integrates CLIP, LLaVA, and a prompt-based decoder to accurately segment target objects.
- Experimental results demonstrate significant gains, including a +17.43% mIoU improvement in 1-shot settings on challenging datasets.
DSV-LFS: Integrating LLMs and Visual Features for Few-Shot Segmentation
This paper introduces a novel approach, DSV-LFS, for few-shot semantic segmentation (FSS) that leverages LLMs to enhance feature representations. Addressing the limitations of current FSS methods, which often struggle with generalization due to incomplete feature representations, DSV-LFS uses LLMs to adapt general class semantic information to the query image. The approach combines dense pixel-wise matching with LLM-driven semantic cues to improve FSS performance, achieving state-of-the-art results on benchmark datasets.
Addressing Feature Representation Limitations in FSS
Current FSS methods often face challenges due to incomplete and appearance-biased feature representations, particularly when support images do not fully capture the variability of the target class. To overcome this, the paper argues for integrating detailed semantic information through class text descriptions. LLMs are utilized to encode these descriptions, providing a more robust integration of textual and visual cues. While previous methods have explored this direction, they often require multi-stage training or remain text-centric, which limits their efficiency and applicability. DSV-LFS introduces a single-stage, end-to-end pipeline that efficiently integrates support images and class descriptions for direct query image segmentation.
DSV-LFS: Architecture and Implementation
DSV-LFS comprises three primary modules. First, a multimodal LLM is employed to adapt the general class description to the query image, generating a semantic prompt. Second, a dense matching module identifies visual correspondences between the query and support images, producing a visual prompt. Finally, a prompt-based decoder combines these two prompts with query image features to segment the target object accurately.
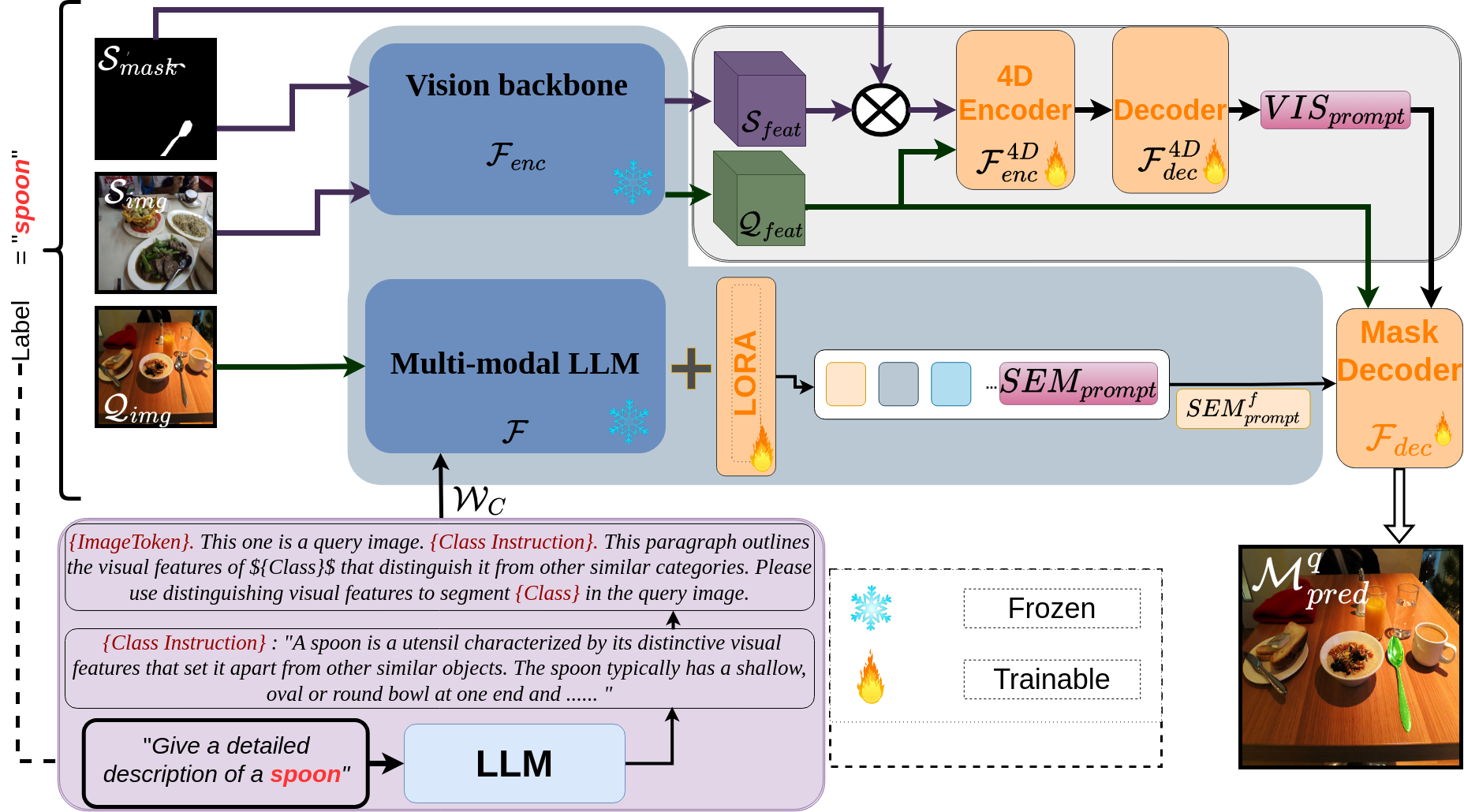
Figure 1: Technical Overview. The LLM first generates a class description WC based on an input prompt, which consists of a simple question regarding the visual features that distinctly define the class C with label ξ.
To generate class descriptions, ChatGPT 4.0 is queried with a prompt for each class to provide a detailed description of the visual characteristics that uniquely identify the object class. The input prompt for the class encoder module is constructed by combining an image token, a class instruction, and the class name. The expected output follows the format "Sure, the segmentation result is <SEMprompt>", where <SEMprompt> is a token added to the LLM vocabulary. This token enables the LLM to adapt the general class description to the visual features of the target object, providing query image-specific semantic information.
The class semantic encoder module adapts class descriptions to the query image, generating a context-aware semantic prompt that captures the specific characteristics of the target class within the query image. The <SEMprompt> token is introduced into the LLM vocabulary to request detailed, query image-specific semantic information. Features from the query image are extracted using CLIP and fed into the LLM along with the prepared description for the target object class. The LLM then generates a text response, and the last-layer embedding corresponding to the <SEMprompt> token is extracted and passed through an MLP projection layer to obtain the final semantic prompt.
The dense matching module generates a visual prompt VISprompt that encodes the similarity between the target object in the support set and the query image. This is achieved by leveraging dense matching between annotated support images and the query image. A diverse range of features is extracted from various depths of a vision transformer, forming a set of 4D hypercorrelation tensors. These hypercorrelations are then stacked together, and efficient center-pivot 4D convolutions are used to combine high-level semantic and low-level geometric cues to encode matching of support and query images. The encoder output is then passed to a decoder module, which generates the visual prompt.
The semantic and visual prompts guide a prompt-based decoder for accurate segmentation of the query image. The semantic prompt captures detailed attributes of the target object, while the visual prompt identifies the target regions in the query image. These prompts, combined with query image features, are integrated into the prompt-based decoder to directly generate segmentation on the query image. The decoder employs multi-head attention and transformer blocks to fuse the semantic and visual information, refining mask proposals through learnable queries.
The training loss combines the text generation loss and the segmentation mask loss, weighted by λtext and λmask, respectively. The text generation loss is formulated as the auto-regressive cross-entropy loss, while the segmentation mask loss combines per-pixel binary cross-entropy (BCE) loss and Dice loss, weighted by λBCE and λDice. For the K-shot scenario, the strategy proposed in \cite{min2021hypercorrelation} is adopted, where the model makes K separate forward passes, and a voting mechanism is applied at each pixel to determine the final segmentation.
Experimental Validation and Results
The proposed method is evaluated on the Pascal-5i and COCO-20i datasets. The mean intersection-over-union (mIoU) is used as the evaluation metric, and each experiment is performed five times using different random seeds to ensure robust and reliable results. The network combines the pre-trained multi-modal LLM LLaVA (llava-v1.5-7b) with the Segment Anything network.
On the Pascal-5i dataset, DSV-LFS achieves comparable results to the LLM-based approach of \cite{zhu2023llafs}, while significantly surpassing all non-LLM-based approaches. On the more challenging COCO-20i dataset, DSV-LFS achieves gains of +17.43\% mIoU in the 1-shot setting and +11.9\% mIoU in the 5-shot setting compared to existing approaches. In cross-domain experiments from COCO-20i to Pascal-5i, DSV-LFS achieves state-of-the-art results, demonstrating a gain of +1\% mIoU in the 1-shot setting compared to other cross-domain FSS methods. Ablation studies on the COCO-20i dataset demonstrate the effectiveness of both the semantic prompt and the visual prompt in improving segmentation performance.



Figure 2: Qualitative results. Examples of our method's performance on the COCO-20i dataset.
Qualitative results demonstrate the method's robustness against misclassification of base classes as novel classes and its ability to precisely segment target classes despite significant variations in scale, occlusion, appearance changes, and cluttered backgrounds.
Figure 3: Additional qualitative results on the COCO-20i dataset, showcasing the model's ability to handle complex and diverse visual scenarios.
Figure 4: Further qualitative examples highlighting accurate segmentation under various conditions and object complexities.
Figure 5: More qualitative results, emphasizing the model's precision in segmenting target objects despite visual challenges and variations.
Figure 6: Qualitative examples displaying robust segmentation performance in scenarios with complex backgrounds and object occlusions.
Figure 7: Additional qualitative results demonstrating the model's adaptability in handling diverse object classes and visual contexts.
Figure 8: Final qualitative examples, underscoring the model's consistent and accurate segmentation across a range of object types and image conditions.
Conclusion
The paper presents a novel approach to few-shot semantic segmentation that integrates LLM-derived semantic prompts with dense visual matching. The introduction of the <SEMprompt> token into the LLM vocabulary enables the generation of class-specific semantic prompts, which are combined with visual prompts <VISprompt> obtained through dense visual matching between query and support images. This dual-prompt strategy combines the broad knowledge-base of LLMs with object-specific visual features from limited samples, resulting in a robust segmentation performance. By integrating semantic and visual cues, DSV-LFS addresses FSS challenges and demonstrates the potential of LLMs to improve segmentation and guide future research on complex tasks.

