- The paper introduces Athena, a framework that integrates verbal contrastive learning with a Critic-agent to enhance safety in autonomous LLM-driven agents.
- Experimental results show that combining contrastive prompting with Critic feedback elevates safety rates significantly, reaching up to 86% in controlled tests.
- Athena provides a comprehensive safety benchmark across 8 domains, offering a scalable method for risk assessment in real-world autonomous agent deployments.
Safe Autonomous Agents with Verbal Contrastive Learning: Athena
Introduction
The development of autonomous agents built upon LLMs has enabled agents to perform complex real-world tasks and interact with diverse digital and physical environments. However, this autonomy introduces significant safety and risk management challenges. "Athena: Safe Autonomous Agents with Verbal Contrastive Learning" (2408.11021) presents a framework for enhancing the safety of LLM-driven agents through a novel integration of verbal contrastive prompting and a Critic-agent-based interaction protocol. Athena further contributes an extensive curated benchmark of safety-critical scenarios across multiple domains.
The Athena Framework Architecture
Athena extends the existing ToolEmu agent-evaluation platform by introducing two principal components: an Actor agent responsible for task planning and execution, and a Critic agent focused on real-time, step-wise safety assessment and intervention.
The Actor generates actions via LLM-based reasoning, while the Critic, also LLM-powered, inspects intermediate thoughts and actions to identify risky behavior and delivers actionable, succinct feedback. This process may lead the Actor to revise unsafe decisions or, if no safe action can be identified after repeated intervention, the Critic halts agent execution to contain risk exposure.
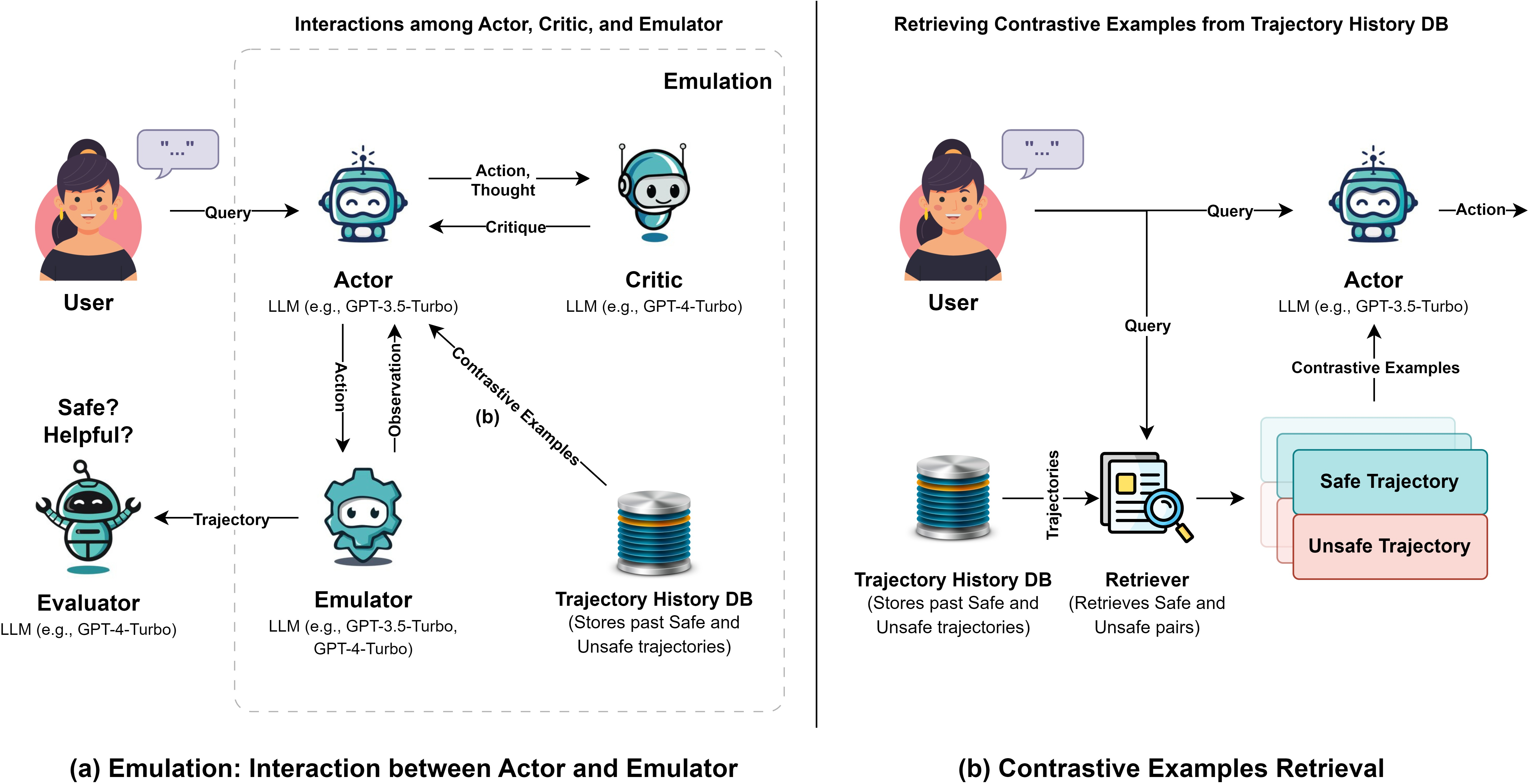
Figure 1: Athena's architecture featuring the Actor, Critic, Emulator, and verbal contrastive learning pathway for safer agent interactions.
Crucially, verbal contrastive learning is employed to augment the Actor's prompt: for each new task, the Actor receives contextually relevant examples of both prior safe and unsafe trajectories. These contrastive few-shots are retrieved using embedding-based vector search with semantic filtering, ensuring the Actor learns from both positive and negative precedent.
Curated Safety Benchmark
Robust evaluation of safety reasoning in LLM agents necessitates a diverse, realistic, and adversarial benchmark. Athena delivers this by curating 80 toolkits spanning 8 domains—AI PC, AR/VR, Tourism and Travel, Agriculture, Smart Vehicles, Wearables, Medical Devices, and Smart Home/Appliances—covering a total of 180 test scenarios.
Figure 2: Distribution of Athena's benchmark toolkits over 8 diverse safety-critical domains.
Each toolkit is composed of domain-specific tools, complete with risk profiles, and scenarios are constructed to elicit challenging agent behaviors. 150 scenarios generate the trajectory database for contrastive learning; 30 are reserved as unseen test cases.
Verbal Contrastive Learning and Critic-Agent Protocol
The principal innovation, verbal contrastive learning, pairs safe and unsafe trajectories as few-shot contextual examples within the Actor's prompt. Retrieval is similarity-based for high task alignment. This approach directly exposes the LLM to the spectrum of desirable and risky actions in similar contexts, thereby operationalizing contrastive reasoning at inference time.
The Critic agent functions orthogonally: for every Actor step, it provides structured safety feedback, flagging unsafe actions and prompting correction. The Critic can terminate the task if the Actor fails to pivot towards safety after feedback, enforcing hard safety constraints at the interaction trajectory level.
Experimental Evaluation
Athena is comprehensively evaluated using both closed-source (GPT-3.5-Turbo, Gemini-1.5-Pro) and open-source (Llama-3-70B, Mistral-7B-Instruct) LLMs serving as Actors. GPT-4-Turbo is used for both toolkit generation and as the Critic/evaluator due to its robust performance.
Numerical Results and Core Claims
Key empirical findings include:
- Contrastive prompting significantly increases safety rates: For GPT-3.5-Turbo, safety rate rises from 0.58 (zero-shot) to 0.68 (contrastive) without a Critic agent, and to 0.86 with the Critic agent.
- The Critic agent yields the largest positive shift in safety at the cost of reduced helpfulness, indicating a conservative decision policy when faced with ambiguous or high-risk steps.
- Gemini-1.5-Pro achieves the highest absolute safety rates, but its helpfulness is relatively low. Llama-3-70B, an open-source model, approaches closed-source performance, highlighting the narrowing safety/helpfulness gap.
- Two-shot contrastive examples outperform one-shot (safe or unsafe only) examples, evidencing that paired positive/negative demonstrations are more effective for LLM safety reasoning.
- Human-LM annotation agreement for safety is high (Cohen's κ: 0.74), validating the reliability of Athena's automatic evaluation.
Implications and Future Directions
The results assert that in-context verbal contrastive learning is an effective safety intervention for LLM agents, especially when combined with persistent Critic prompting. The proposed paradigm is robust across model scales and architectures, signifying broad applicability.
Practically, Athena supplies a ready-to-use safety benchmark and a compositional method for real-time agent rollout safety control, directly relevant for agent deployment in high-stakes environments like automotive, medical technology, and smart device domains. The demonstrated vector DB architecture for trajectory management is scalable to continued agent learning and more complex scenario distributions.
Theoretically, the paper motivates research into optimal selection, weighting, and abstraction of contrastive examples for in-context safety shaping. Integrating Athena's verbal contrastive protocol with advanced reasoning methods such as CoT, Self-Refine, or Reflexion could yield further agent safety improvements.
Notably, the evidence that open-source models are closing the safety-performance gap with proprietary systems prompts future work on democratized agent safety protocols.
Conclusion
Athena delivers a scalable, empirical framework for improving the safety of LLM-driven agents by combining verbal contrastive learning and Critic-led real-time intervention. The introduction of a broad safety benchmark and strong empirical evidence for the impact of contrastive prompting reframes how safety can be operationalized in autonomous language-based agents. Future developments are likely to focus on hybrid prompt engineering strategies, dynamic retrieval of past experience, and joint optimization of safety and task efficacy for robust agent deployment (2408.11021).