- The paper introduces the PEC mechanism, reducing checkpoint sizes by 54.2% while maintaining minimal accuracy loss in Sparse MoE training.
- It employs adaptive data-parallel sharding and asynchronous checkpointing with triple-buffering to enhance fault tolerance efficiently.
- Experimental results on an 8-expert GPT-MoE model show a 76.9% reduction in per-rank workload and significant efficiency gains.
MoC-System: Efficient Fault Tolerance for Sparse Mixture-of-Experts Model Training
The efficient handling of fault tolerance in large-scale neural networks, specifically in the Sparse Mixture-of-Experts (MoE) models, presents unique challenges due to the increased complexity and size of these models. This paper introduces the Partial Experts Checkpoint (PEC) mechanism and a corresponding fault-tolerant system designed to address these challenges effectively.
Background and Motivation
As transformer-based LLMs continue to scale, ensuring fault tolerance becomes paramount in distributed systems. The traditional checkpointing strategy, while effective for dense models, struggles with the additional complexities brought about by the sparsely-gated MoE models. In this context, MoE models, which aim to expand parameter counts while maintaining manageable computational demands, require tailored solutions to manage the increased checkpoint data volume efficiently.
Partial Experts Checkpoint (PEC) Mechanism
The PEC mechanism proposes selectively checkpointing only a subset of experts within an MoE layer, significantly reducing the checkpoint size to that of dense models. By doing so, it mitigates the storage and time overhead associated with traditional checkpoint methods.
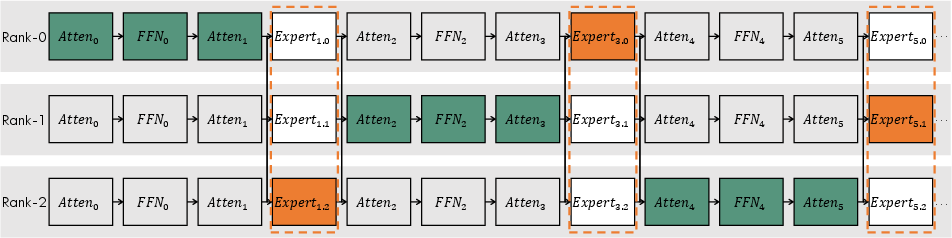
Figure 1: The saved components of training states in a PEC checkpoint, including the expert part with partial selection (orange) and the non-expert part with data-parallel sharding (green).
Effects on Model Quality
The introduction of PEC raises potential concerns regarding its impact on model training accuracy. The paper addresses this by introducing the Portion of Lost Tokens (PLT) metric, which serves to quantify accuracy losses. The empirical analysis suggests negligible accuracy degradation when the PLT remains below 7.5%, aligning well with existing dropout mechanisms inherent in deep learning frameworks.
Enhanced Fault-Tolerant System
The PEC system is further optimized with a series of enhancements aimed at mitigating the impact of faults without detracting from model quality. The key components include asynchronous checkpointing with triple-buffering, adaptive data-parallel sharding, and strategies like Dynamic-K to adapt to the varying fault scenarios over extended training periods.
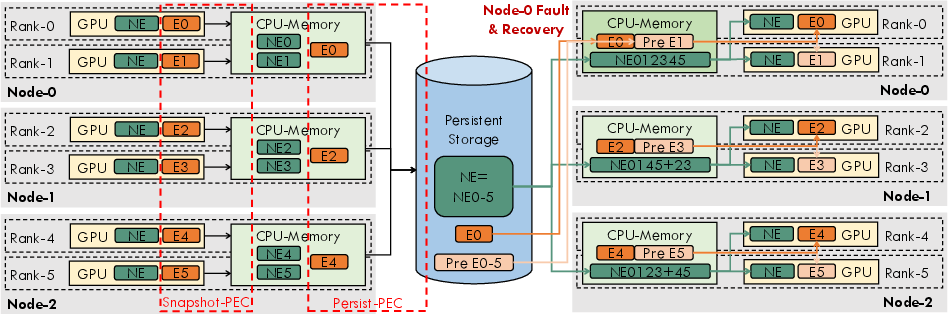
Figure 2: Schematic of two-level PEC saving and recovery within PEC fault-tolerant system.
Two-Level PEC Strategy
The two-level PEC approach implements a split between snapshot-PEC and persist-PEC methodologies, optimizing overhead management at different phases of the checkpoint process. This structure is pivotal in achieving full overlap with the training workflow, minimizing the residual overhead from the checkpointing operations.
Experimental Results
The paper's experimental evaluation, conducted using an 8-expert GPT-MoE model, demonstrates significant efficiency gains. A notable 54.2% reduction in checkpoint size is reported without sacrificing model fidelity. Furthermore, a 76.9% reduction in the per-rank checkpoint workload showcases the practical benefits of the PEC system.
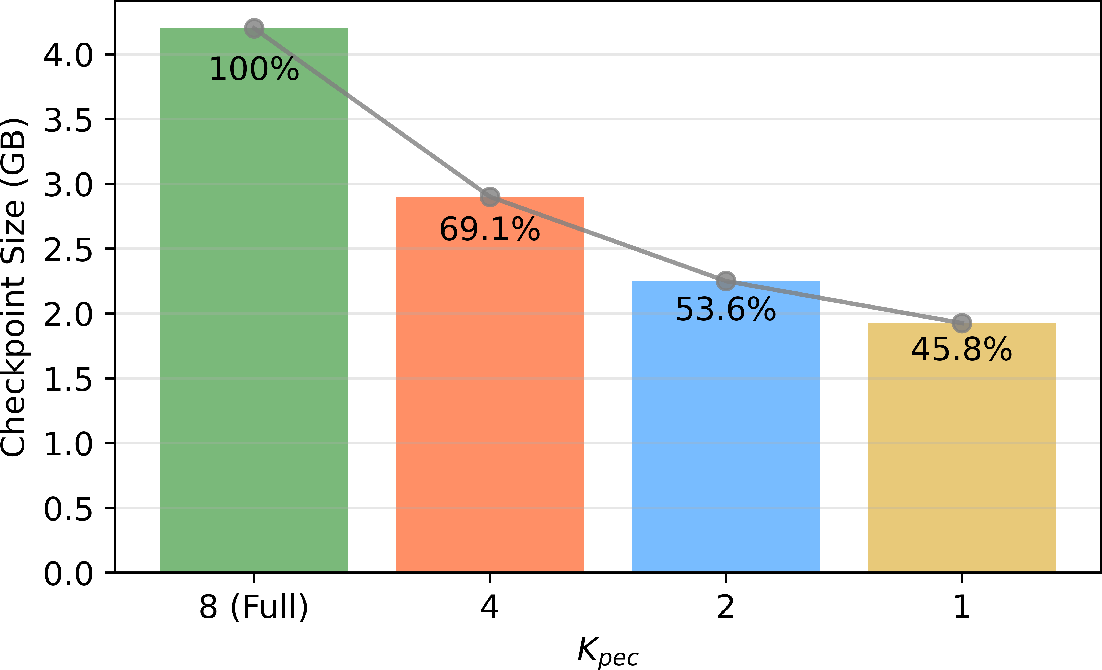
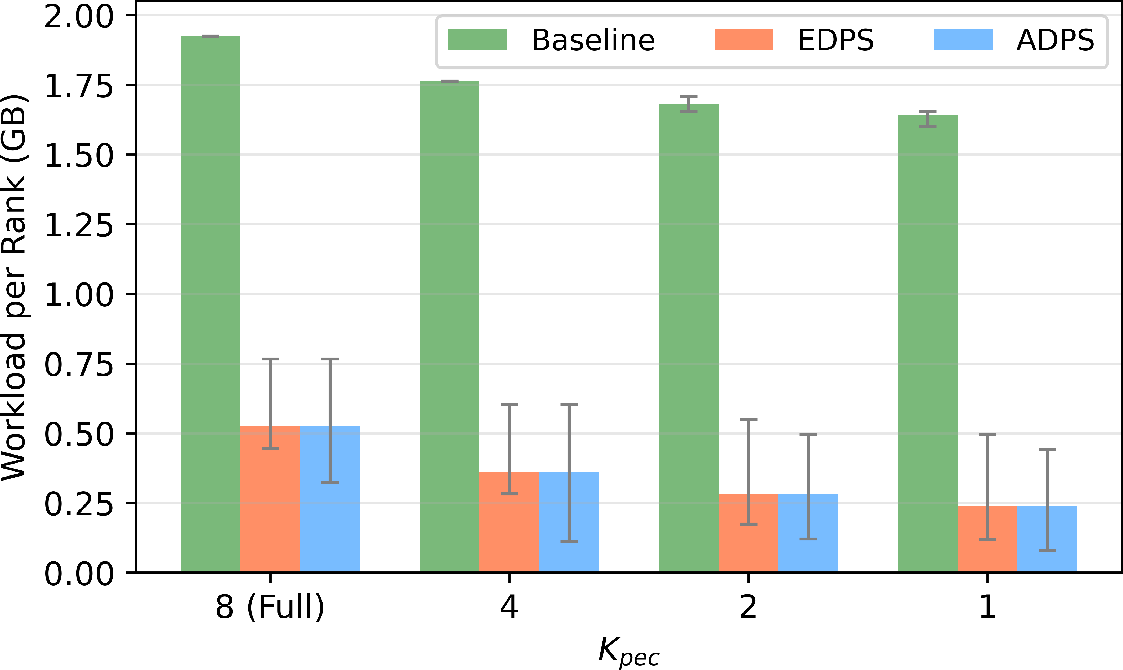
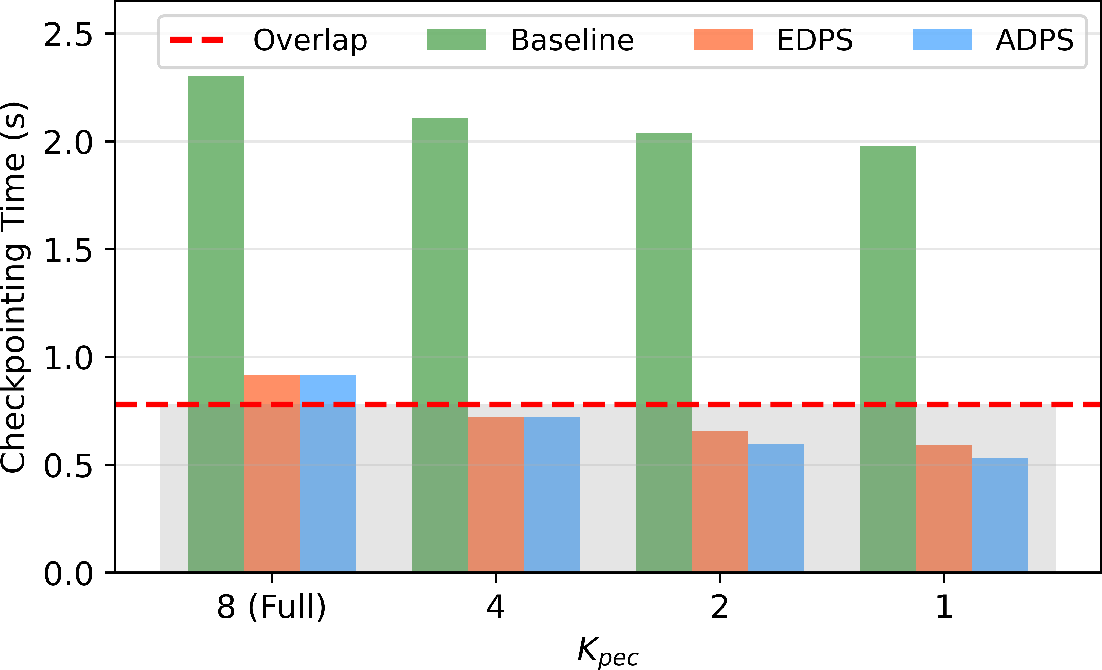
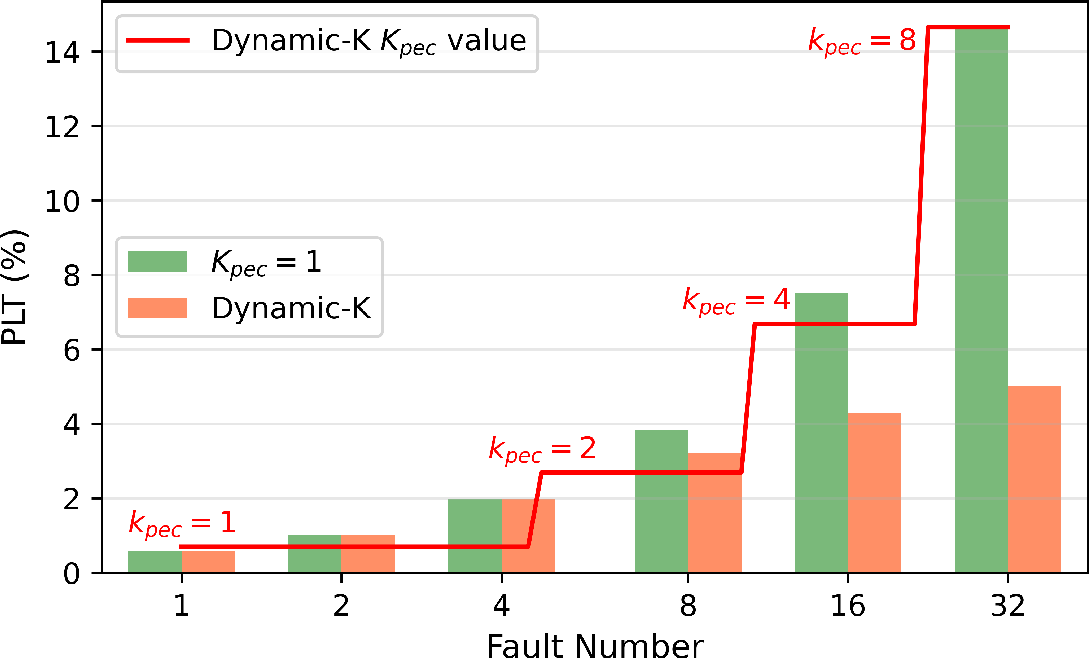
Figure 3: Experimental results of training GPT-MoE with PEC using sequential expert selection.
Comparison with Baseline
The adaptive and sequential strategies proposed under PEC outperform conventional checkpointing, significantly reducing duplicate data storage and improving overall training efficiency. The deployment of load-aware expert selection further fine-tunes the balance between resource allocation and fault-tolerant training.
Conclusion
The PEC mechanism and system offer significant advancements in the efficient realization of fault-tolerant training for MoE models. By addressing the inherent scalability challenges, PEC proves to be a pivotal development in enhancing the robustness and efficiency of AI infrastructures handling large-scale, sparse models. Future explorations aim to refine the balance between operational efficiency and model fidelity, leveraging advancements in gradient compression and optimization strategies. This continued innovation is critical in supporting the scaling demands of next-generation AI applications and infrastructures.