- The paper presents a novel predictive model integrating QGeoGNN, ANN, and LGB to enhance column chromatography efficiency.
- The automated data acquisition platform minimizes manual errors by systematically collecting large datasets for effective feature engineering.
- Transfer learning adapts the model across different column sizes, validated by experiments using the separation probability metric S_p.
Intelligent Chemical Purification Technique Based on Machine Learning
Introduction
The paper presents an innovative approach to enhance column chromatography using artificial intelligence and machine learning techniques to improve data collection standardization and address inefficiencies in chemical separation processes. Traditional column chromatography, despite its pivotal role in chemical separation and purification, suffers from inefficiencies due to its trial-and-error nature and dependency on accumulated expertise. The integration of machine learning aims to resolve these issues by developing predictive models that improve chromatographic process efficiency and quality, utilizing transfer learning to adapt the model across different column specifications.
Automated Data Acquisition
A central pillar of the research involves the establishment of an automated platform for precise data acquisition, significantly mitigating the errors associated with manual data collection. The automated system consists of key components, namely a pumping unit, autosampler, UV detector, and control terminal, which together facilitate the automation of the experimental workflow. The platform systematically collects large volumes of experimental data, creating a robust foundation for further data-driven modeling.
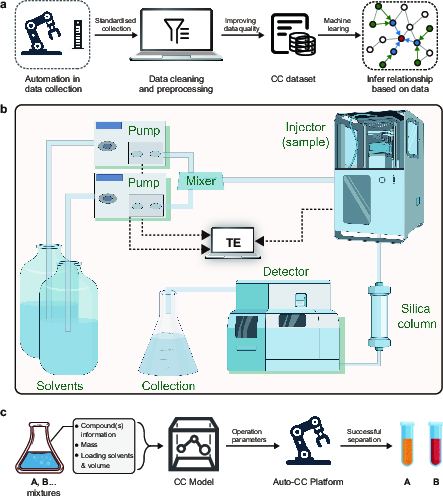
Figure 1: Schematic diagram of main parts. (a) Research pipeline. (b) Schematic of automation platform. (c) Separation process schematic (CC, column chromatography).
Development of the Basic Model
The development of a predictive chromatographic model leveraged machine learning algorithms such as Light Gradient Boosting Machine (LGB), Artificial Neural Networks (ANN), and a novel Graph Neural Network approach, QGeoGNN. The dataset used comprises records for various compounds, collected via standardized methods on a 4g column, and utilized advanced feature engineering to integrate molecular and experimental parameters. The QGeoGNN, incorporating graphs to represent molecular structures, exhibited superior predictive performance due to its ability to encode complex molecular interactions essential for accurate chromatographic prediction.
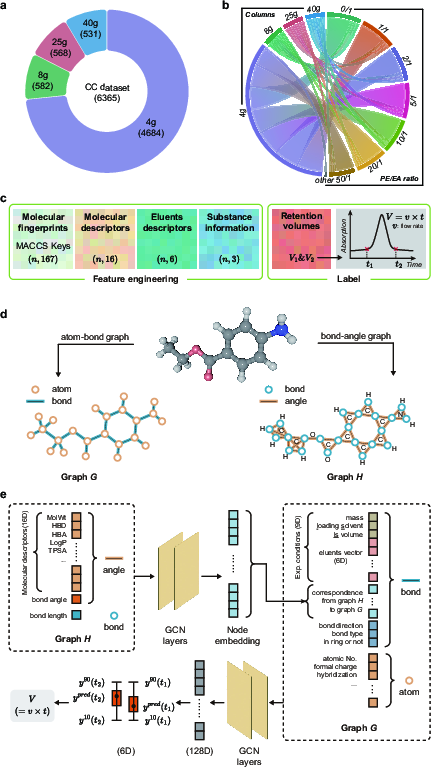
Figure 2: Dataset distribution and feature engineering. (a) Column specifications for number distribution. (b) Distribution of the amount of data according to the proportion of eluents. (c) Feature engineering for ANN and LGB. (d) The schematic instruction of atom-bond Graph G and bond-angle Graph H. (e) Schematic diagram of QGeoGNN hierarchy.
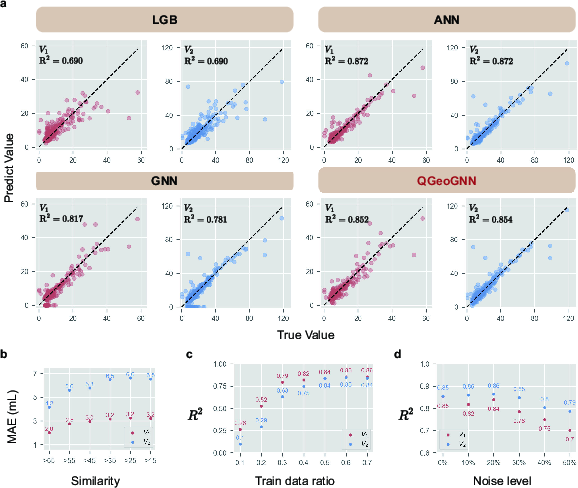
Figure 3: The training results of the basic model. (a) Training outcomes of different machine learning algorithms based on 4g-dataset. (b) Relationship between mean absolute error (MAE) and compound similarity. (c) Impact of the training set proportion on R2. (d) Influence of Gaussian noise ratio on R2.
Transfer Learning Application
Transfer learning enabled the extension of the predictive model to handle different chromatography column specifications, crucial for enhancing scalability and adaptability. By training the model with smaller datasets from larger columns such as 8g, 25g, and 40g, the paper demonstrated how pre-trained weights from the base model could effectively predict chromatographic outcomes across new tasks, accommodating the variability in different experimental setups.
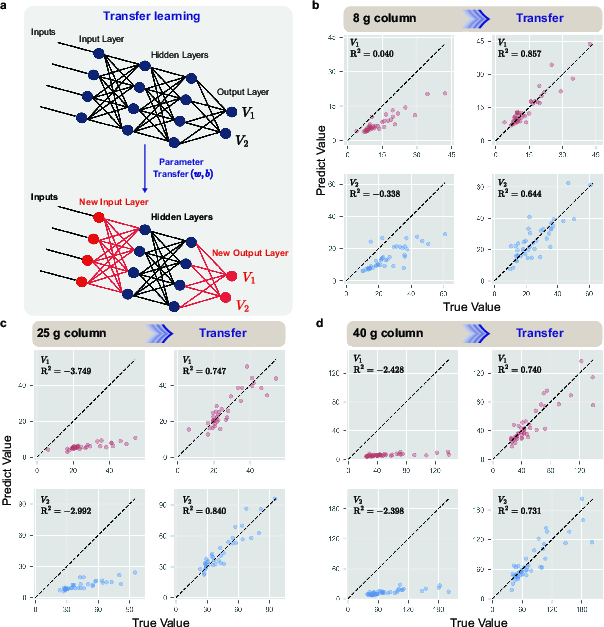
Figure 4: Transfer learning and training results. (a) Transfer learning process; (b, c, d) Training results from the application of transfer learning to the 8g, 25g, and 40g column datasets using the QGeoGNN model initially developed for the 4g.
Application of \texorpdfstring{Sp}{Sp}
The introduction of a separation probability metric, Sp, quantifies the likelihood of successful compound separation under specific conditions, relying on quantile-based probabilistic assessments. The metric is validated through experiments on classic reactions, such as the Claisen rearrangement, showcasing its utility and accuracy in predicting chromatographic success in practical chemical scenarios.
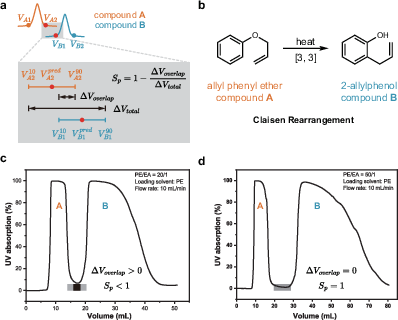
Figure 5: Application of Sp in CC predictive model. (a) Schematic diagram of Sp calculation. (b) The classic Claisen rearrangement reaction. (c, d) Wet laboratory validation based on model prediction results.
Conclusion
This research exemplifies the application of machine learning in enhancing the efficiency of chemical purification processes. By automating data acquisition and employing advanced predictive models, the study establishes a foundation for future advancements in chemical separations, demonstrating significant improvements in traditional chromatographic methods. While substantial progress is made, further work is essential to address limitations such as dataset breadth and broader applicability of different eluent systems, ultimately ensuring the model's robustness and precision in diverse chemical contexts.