RULER: What's the Real Context Size of Your Long-Context Language Models?
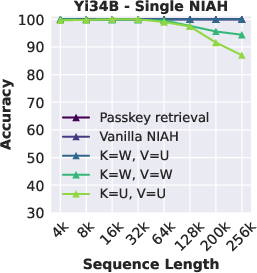
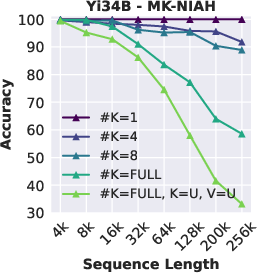
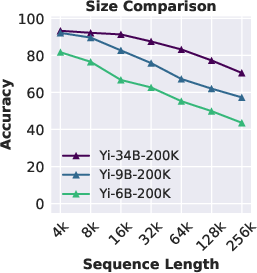
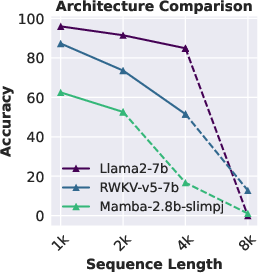
Abstract: The needle-in-a-haystack (NIAH) test, which examines the ability to retrieve a piece of information (the "needle") from long distractor texts (the "haystack"), has been widely adopted to evaluate long-context LMs. However, this simple retrieval-based test is indicative of only a superficial form of long-context understanding. To provide a more comprehensive evaluation of long-context LMs, we create a new synthetic benchmark RULER with flexible configurations for customized sequence length and task complexity. RULER expands upon the vanilla NIAH test to encompass variations with diverse types and quantities of needles. Moreover, RULER introduces new task categories multi-hop tracing and aggregation to test behaviors beyond searching from context. We evaluate 17 long-context LMs with 13 representative tasks in RULER. Despite achieving nearly perfect accuracy in the vanilla NIAH test, almost all models exhibit large performance drops as the context length increases. While these models all claim context sizes of 32K tokens or greater, only half of them can maintain satisfactory performance at the length of 32K. Our analysis of Yi-34B, which supports context length of 200K, reveals large room for improvement as we increase input length and task complexity. We open source RULER to spur comprehensive evaluation of long-context LMs.
- AI21. Introducing jamba: Ai21’s groundbreaking ssm-transformer model, 2024. URL https://www.ai21.com/blog/announcing-jamba.
- L-eval: Instituting standardized evaluation for long context language models. In ICLR, 2024.
- Anthropic. Long context prompting for Claude 2.1. Blog, 2023. URL https://www.anthropic.com/index/claude-2-1-prompting.
- Anthropic. Introducing the next generation of claude, 2024. URL https://www.anthropic.com/news/claude-3-family.
- Zoology: Measuring and improving recall in efficient language models. In ICLR, 2024.
- Yushi Bai et al. LongBench: A bilingual, multitask benchmark for long context understanding. arXiv:2308.14508, 2023.
- Scaling Transformer to 1M tokens and beyond with RMT. arXiv:2304.11062, 2023.
- Introducing GoodAI LTM benchmark. Blog, 2024. URL https://www.goodai.com/introducing-goodai-ltm-benchmark/.
- Extending context window of large language models via positional interpolation. In ICLR, 2023.
- LongLoRA: Efficient fine-tuning of long-context large language models. In ICLR, 2024.
- Generating long sequences with sparse Transformers. arXiv:1904.10509, 2019.
- Cohere. Command r, 2024. URL https://docs.cohere.com/docs/command-r#model-details.
- Tri Dao. FlashAttention-2: Faster attention with better parallelism and work partitioning. arxiv:2307.08691, 2023.
- FlashAttention: Fast and memory-efficient exact attention with IO-awareness. In NeurIPS, 2022.
- Jiayu Ding et al. LongNet: Scaling Transformers to 1,000,000,000 tokens. arXiv:2307.02486, 2023.
- Yiran Ding et al. LongRoPE: Extending LLM context window beyond 2 million tokens. arXiv:2402.13753, 2024.
- Bamboo: A comprehensive benchmark for evaluating long text modeling capacities of large language models. arXiv:2309.13345, 2023.
- GLM: General language model pretraining with autoregressive blank infilling. In Proc of the 60th Annual Meeting of the ACL (Volume 1: Long Papers), pp. 320–335, 2022.
- Hungry Hungry Hippos: Towards language modeling with state space models. In ICLR, 2023a.
- Daniel Y. Fu et al. Simple hardware-efficient long convolutions for sequence modeling. ICML, 2023b.
- Yao Fu et al. Data engineering for scaling language models to 128k context. arXiv:2402.10171, 2024.
- Neural Turing machines. arXiv:1410.5401, 2014.
- Mamba: Linear-time sequence modeling with selective state spaces. arXiv:2312.00752, 2023.
- Efficiently modeling long sequences with structured state spaces. In ICLR, 2022.
- Lm-infinite: Simple on-the-fly length generalization for large language models. arXiv:2308.16137, 2023.
- John J. Hopfield. Neural networks and physical systems with emergent collective computational abilities. Proc of the National Academy of Sciences of the United States of America, 79 8:2554–8, 1982.
- Efficient long-text understanding with short-text models. Transactions of the ACL, 11:284–299, 2023.
- Sam Ade Jacobs et al. DeepSpeed Ulysses: System optimizations for enabling training of extreme long sequence Transformer models. arXiv:2309.14509, 2023.
- Sebastian Jaszczur et al. Sparse is enough in scaling transformers. In NeurIPS, 2021.
- Albert Q Jiang et al. Mixtral of experts. arXiv:2401.04088, 2024.
- Huiqiang Jiang et al. LongLlmLingua: Accelerating and enhancing LLMs in long context scenarios via prompt compression. arXiv:2310.06839, 2023.
- Gregory Kamradt. Needle In A Haystack - pressure testing LLMs. Github, 2023. URL https://github.com/gkamradt/LLMTest_NeedleInAHaystack/tree/main.
- Lauri Karttunen. Discourse referents. In COLING, 1969.
- George Kingsley Zipf. Selected studies of the principle of relative frequency in language. Harvard university press, 1932.
- Woosuk Kwon et al. Efficient memory management for large language model serving with paged attention. In Proc. of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023.
- How long can open-source LLMs truly promise on context length?, 2023a. URL https://lmsys.org/blog/2023-06-29-longchat.
- Loogle: Can long-context language models understand long contexts? arXiv:2311.04939, 2023b.
- Ring attention with blockwise Transformers for near-infinite context. In ICLR, 2023.
- World model on million-length video and language with Ring Attention. arxiv:2402.08268, 2024a.
- Jiaheng Liu et al. E2-LLM: Efficient and extreme length extension of large language models. arXiv:2401.06951, 2024b.
- Lost in the middle: How language models use long contexts. Transactions of the ACL, 12:157–173, 2024c.
- ∞\infty∞-former: Infinite memory Transformer. In Proc. of the 60th Annual Meeting of the ACL (Volume 1: Long Papers), 2022.
- Mistral.AI. La plateforme, 2023. URL https://mistral.ai/news/la-plateforme/.
- Landmark attention: Random-access infinite context length for Transformers. In Workshop on Efficient Systems for Foundation Models @ ICML, 2023.
- Vincent Ng. Supervised noun phrase coreference research: The first fifteen years. In Proc. of the 48th Annual Meeting of the ACL, 2010.
- Catherine Olsson et al. In-context learning and induction heads. Transformer Circuits Thread, 2022. https://transformer-circuits.pub/2022/in-context-learning-and-induction-heads/index.html.
- OpenAI: Josh Achiam et al. GPT-4 technical report. arXiv:2303.08774, 2023.
- Bo Peng et al. RWKV: Reinventing RNNs for the transformer era. In EMNLP, 2023.
- YaRN: Efficient context window extension of large language models. In ICLR, 2024.
- Hyena hierarchy: Towards larger convolutional language models. In ICML, 2023.
- Train short, test long: Attention with linear biases enables input length extrapolation. In ICLR, 2022.
- Know what you don’t know: Unanswerable questions for SQuAD. In Proc. of the 56th Annual Meeting of the ACL (Volume 2: Short Papers), 2018.
- Machel Reid et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context. arXiv:2403.05530, 2024.
- Beyond accuracy: Behavioral testing of NLP models with CheckList. In Proc. of the 58th Annual Meeting of the ACL, 2020.
- ZeroSCROLLS: A zero-shot benchmark for long text understanding. In EMNLP, 2023.
- RoFormer: Enhanced Transformer with rotary position embedding. arXiv:2104.09864, 2023.
- ChapterBreak: A challenge dataset for long-range language models. In Proc. of the 2022 Conference of the North American Chapter of the ACL: Human Language Technologies, 2022.
- Retentive network: A successor to Transformer for large language models. arXiv:2307.08621, 2023a.
- A length-extrapolatable Transformer. In Proc. of the 61st Annual Meeting of the ACL (Volume 1: Long Papers), 2023b.
- A benchmark for learning to translate a new language from one grammar book. In ICLR, 2024.
- Yi Tay et al. Long Range Arena: A benchmark for efficient Transformers. In ICLR, 2021.
- Together.AI. Preparing for the era of 32k context: Early learnings and explorations, 2023a. URL https://www.together.ai/blog/llama-2-7b-32k.
- Together.AI. Llama-2-7b-32k-instruct — and fine-tuning for llama-2 models with together api, 2023b. URL https://www.together.ai/blog/llama-2-7b-32k-instruct.
- Hugo Touvron et al. Llama 2: Open foundation and fine-tuned chat models. arXiv:2307.09288, 2023.
- Musique: Multihop questions via single-hop question composition. Transactions of the ACL, 10:539–554, 2022.
- Szymon Tworkowski et al. Focused Transformer: Contrastive training for context scaling. NeurIPS, 36, 2024.
- Teun A. van Dijk and Walter Kintsch. Strategies of discourse comprehension. In Academic Press, 1983.
- Attention is all you need. In NeurIPS, 2017.
- Augmenting language models with long-term memory. NeurIPS, 36, 2024.
- Thomas Wolf et al. Huggingface’s Transformers: State-of-the-art natural language processing. arXiv:1910.03771, 2019.
- Memformer: A memory-augmented Transformer for sequence modeling. In Findings of the ACL: AACL-IJCNLP, 2022.
- X.AI. Announcing grok-1.5, 2024. URL https://x.ai/blog/grok-1.5.
- Chaojun Xiao et al. InfLLM: Unveiling the intrinsic capacity of LLMs for understanding extremely long sequences with training-free memory. arXiv:2402.04617, 2024a.
- Efficient streaming language models with attention sinks. In ICLR, 2024b.
- Wenhan Xiong et al. Effective long-context scaling of foundation models. arXiv:2309.16039, 2023.
- Retrieval meets long context large language models. In ICLR, 2024.
- HotpotQA: A dataset for diverse, explainable multi-hop question answering. In EMNLP, 2018.
- Alex Young et al. Yi: Open foundation models by 01.AI. arXiv:2403.04652, 2024.
- Soaring from 4k to 400k: Extending LLM’s context with activation beacon. arXiv:2401.03462, 2024a.
- ∞\infty∞bench: Extending long context evaluation beyond 100k tokens. arXiv:2402.13718, 2024b.
- PoSE: Efficient context window extension of LLMs via positional skip-wise training. In ICLR, 2024.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.