- The paper introduces HELMET, a benchmark that assesses long-context LLMs across seven diverse, application-centric categories.
- It employs model-based evaluations and few-shot prompting to reliably measure model performance on tasks like summarization and long-document QA.
- The study reveals that real-world tasks outperform synthetic ones in reflecting true model capabilities as context lengths increase.
HELMET: How to Evaluate Long-Context LLMs Effectively and Thoroughly
HELMET addresses the challenge of evaluating long-context LLMs (LCLMs) by providing a comprehensive benchmark that encompasses diverse, application-centric categories. This essay outlines the motivation, design, and results of using HELMET to evaluate a wide range of LCLMs.
Introduction to HELMET
Existing benchmarks for LCLMs often rely on synthetic tasks or arbitrary subsets of tasks, leading to noisy signals and inconsistent model comparisons. For example, tasks like needle-in-a-haystack (NIAH) and others often do not translate well to diverse downstream applications. HELMET aims to resolve these issues by encompassing seven diverse categories with controllable lengths up to 128k tokens, providing reliable and consistent evaluations through model-based metrics and few-shot prompting.

Figure 1: Long-context benchmark results of frontier LCLMs at 128k input length. HELMET demonstrates more consistent rankings.
Benchmark Design
HELMET includes realistic tasks such as retrieval-augmented generation (RAG), passage re-ranking, and generation with citations. It also covers more complex tasks like long-document question answering, summarization, many-shot in-context learning, and various forms of synthetic recalls.
Reliable Evaluation Metrics
Conventional metrics like ROUGE are often unreliable for long outputs in tasks such as summarization or long-document QA. Instead, HELMET uses model-based evaluations to significantly improve reliability. This involves LLM-judged fluency and correctness for QA, and precision/recall metrics for summarization tasks.
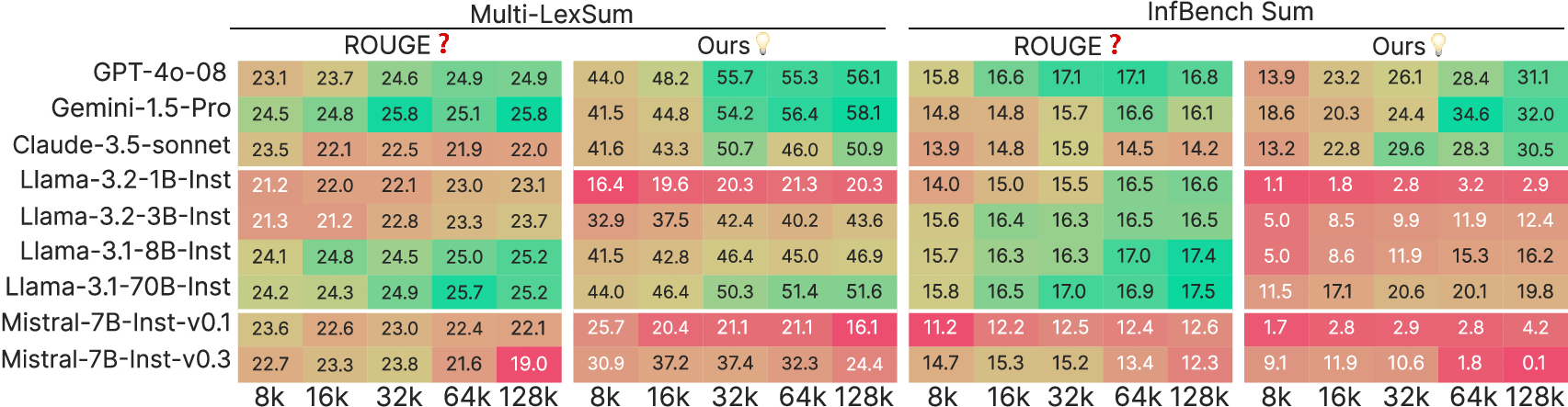
Figure 2: Comparison between ROUGE-L F1 and model-based evaluation metric on summarization tasks.
Prompting and Evaluation Settings
To reduce noise and support evaluation of both base and instruction-tuned models, HELMET employs few-shot prompting. This approach enhances the model's ability to consistently produce desired outputs across tasks. HELMET also provides controlled evaluation settings to ensure fair comparisons at varying input lengths.
Detailed Evaluation Results
Synthetic Tasks vs. Real-World Applications
A major finding is that commonly used synthetic tasks like NIAH do not correlate well with real-world applications. Tasks with more distracting or complex contexts like JSON KV retrieval exhibit better correlation with other downstream tasks.
Diverse Applications Require Diverse Measures
The benchmark results indicate that while some tasks, such as RAG, correlate with each other, other categories like summarization and ICL show distinctive trends. This highlights the necessity of evaluating LCLMs over a broad spectrum of categories.
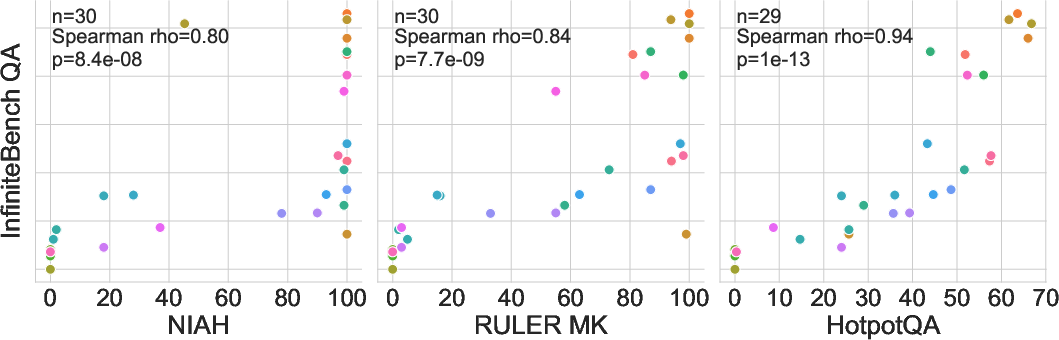
Figure 3: Distribution of instruction-tuned models' performance on QA with respect to NIAH, RULER MK, and HotpotQA.
Despite substantial improvements, closed-source models like GPT-4o and Gemini still outperform open-source models on more complex tasks. However, capabilities vary significantly across different tasks, showing no clear winner uniformly.
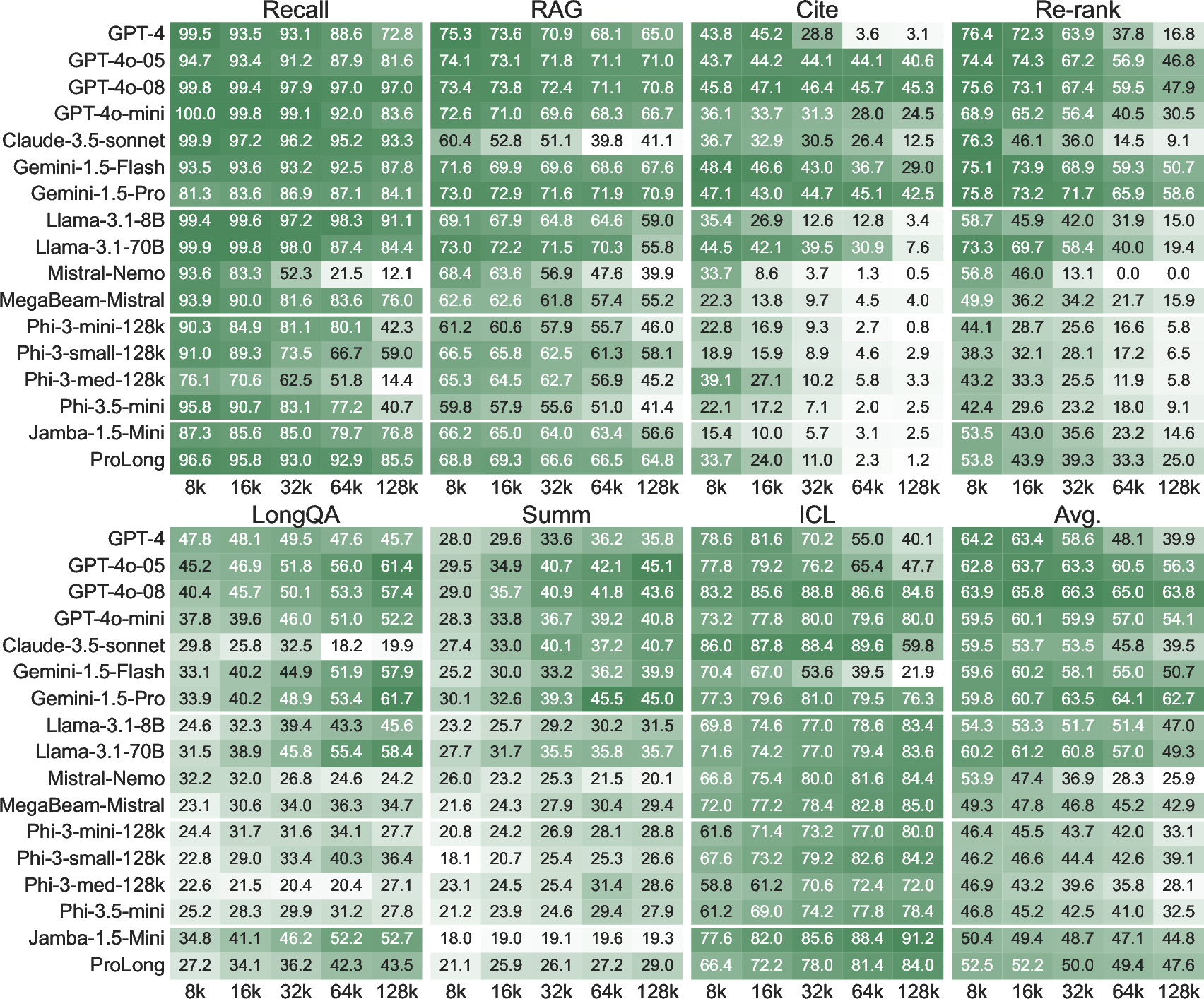
Figure 4: Results of HELMET with various models demonstrating that performance degradation varies across tasks as input length increases.
Conclusion
HELMET provides a robust framework for evaluating LCLMs comprehensively and consistently across varied applications. The benchmark facilitates deeper insight into model capacities and informs the development of more capable long-context models. By doing so, it prioritizes realistic evaluation settings that reflect real-world application demands.
In future work, the community should focus on further improving evaluation metrics and exploring the potential for more advanced positional understanding to handle extended contexts effectively.

