A Survey on Safe Multi-Modal Learning System
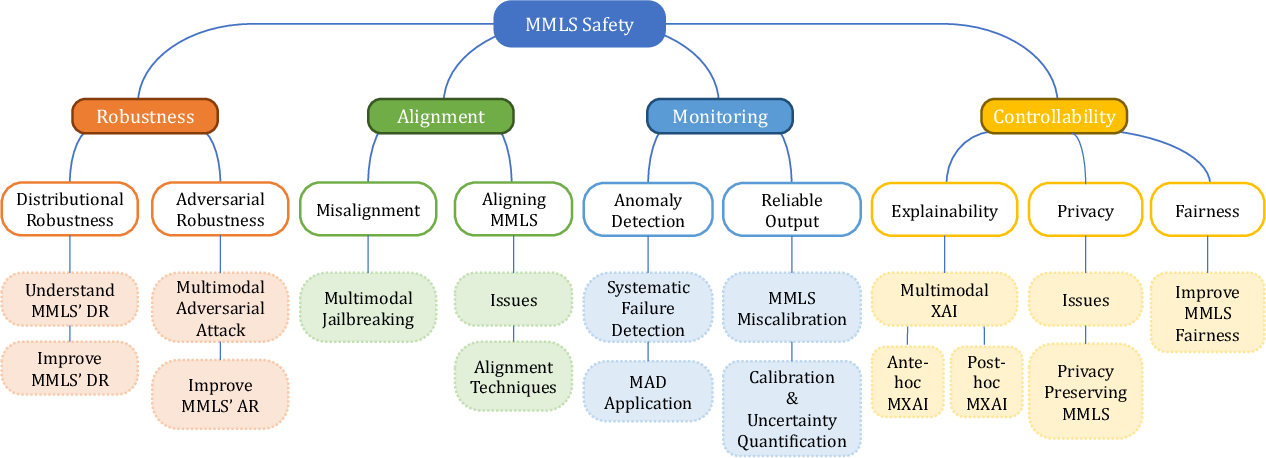
Abstract: In the rapidly evolving landscape of artificial intelligence, multimodal learning systems (MMLS) have gained traction for their ability to process and integrate information from diverse modality inputs. Their expanding use in vital sectors such as healthcare has made safety assurance a critical concern. However, the absence of systematic research into their safety is a significant barrier to progress in this field. To bridge the gap, we present the first taxonomy that systematically categorizes and assesses MMLS safety. This taxonomy is structured around four fundamental pillars that are critical to ensuring the safety of MMLS: robustness, alignment, monitoring, and controllability. Leveraging this taxonomy, we review existing methodologies, benchmarks, and the current state of research, while also pinpointing the principal limitations and gaps in knowledge. Finally, we discuss unique challenges in MMLS safety. In illuminating these challenges, we aim to pave the way for future research, proposing potential directions that could lead to significant advancements in the safety protocols of MMLS.
- Robust cross-modal representation learning with progressive self-distillation. In CVPR, 2022.
- Multimodal machine learning: A survey and taxonomy. TPAMI, 41(2), 2018.
- Bias and fairness in multimodal machine learning: A case study of automated video interviews. In ICMI, 2021.
- Exploring text specific and blackbox fairness algorithms in multimodal clinical nlp. arXiv preprint arXiv:2011.09625, 2020.
- Fmmrec: Fairness-aware multimodal recommendation. arXiv preprint arXiv:2310.17373, 2023.
- Clip-ad: A language-guided staged dual-path model for zero-shot anomaly detection. arXiv preprint arXiv:2311.00453, 2023.
- Can language models be instructed to protect personal information? arXiv preprint arXiv:2310.02224, 2023.
- Multimodal machine unlearning. arXiv preprint arXiv:2311.12047, 2023.
- Estimating uncertainty in multimodal foundation models using public internet data. arXiv preprint arXiv:2310.09926, 2023.
- Data determines distributional robustness in contrastive language image pre-training (clip). In ICML. PMLR, 2022.
- Fedmultimodal: A benchmark for multimodal federated learning. arXiv preprint arXiv:2306.09486, 2023.
- Large-scale adversarial training for vision-and-language representation learning. NeurIPS, 33, 2020.
- Anomalygpt: Detecting industrial anomalies using large vision-language models. arXiv preprint arXiv:2308.15366, 2023.
- How well does gpt-4v (ision) adapt to distribution shifts? a preliminary investigation. arXiv preprint arXiv:2312.07424, 2023.
- Safeguarding data in multimodal ai: A differentially private approach to clip training. arXiv preprint arXiv:2306.08173, 2023.
- Winclip: Zero-/few-shot anomaly classification and segmentation. In CVPR, 2023.
- Robustmixgen: Data augmentation for enhancing robustness of visual-language models in the presence of distribution shift. Authorea Preprints, 2023.
- Practical membership inference attacks against large-scale multi-modal models: A pilot study. In ICCV, 2023.
- Vqa-e: Explaining, elaborating, and enhancing your answers for visual questions. In ECCV, 2018.
- A closer look at the robustness of vision-and-language pre-trained models. arXiv preprint arXiv:2012.08673, 2020.
- Myriad: Large multimodal model by applying vision experts for industrial anomaly detection. arXiv preprint arXiv:2310.19070, 2023.
- Red teaming visual language models. arXiv preprint arXiv:2401.12915, 2024.
- Multimodal contrastive learning via uni-modal coding and cross-modal prediction for multimodal sentiment analysis. arXiv preprint arXiv:2210.14556, 2022.
- Learning multimodal data augmentation in feature space. arXiv preprint arXiv:2212.14453, 2022.
- Dime: Fine-grained interpretations of multimodal models via disentangled local explanations. In AIES, 2022.
- Are multimodal transformers robust to missing modality? In CVPR, 2022.
- Calibrating multimodal learning. In ICML. PMLR, 2023.
- Robustness in multimodal learning under train-test modality mismatch. In ICML. PMLR, 2023.
- A survey on bias and fairness in machine learning. CSUR, 54(6), 2021.
- Understanding (un) intended memorization in text-to-image generative models. arXiv preprint arXiv:2312.07550, 2023.
- A survey of machine unlearning. arXiv preprint arXiv:2209.02299, 2022.
- Towards calibrated robust fine-tuning of vision-language models. arXiv preprint arXiv:2311.01723, 2023.
- Discover: Making vision networks interpretable via competition and dissection. arXiv preprint arXiv:2310.04929, 2023.
- Bias in multimodal ai: Testbed for fair automatic recruitment. In CVPRW, 2020.
- Visual adversarial examples jailbreak aligned large language models. In NFAML Workshop, volume 1, 2023.
- Are multimodal models robust to image and text perturbations? arXiv preprint arXiv:2212.08044, 2022.
- Building privacy-preserving and secure geospatial artificial intelligence foundation models (vision paper). In ACM SIGSPATIAL, 2023.
- Multimodal explainable artificial intelligence: A comprehensive review of methodological advances and future research directions. arXiv preprint arXiv:2306.05731, 2023.
- On the adversarial robustness of multi-modal foundation models. In ICCV, 2023.
- Bias and fairness on multimodal emotion detection algorithms. arXiv preprint arXiv:2205.08383, 2022.
- Framu: Attention-based machine unlearning using federated reinforcement learning. arXiv preprint arXiv:2309.10283, 2023.
- Understanding and mitigating copying in diffusion models. arXiv preprint arXiv:2305.20086, 2023.
- Assessing multilingual fairness in pre-trained multimodal representations. arXiv preprint arXiv:2106.06683, 2021.
- Towards top-down reasoning: An explainable multi-agent approach for visual question answering. arXiv preprint arXiv:2311.17331, 2023.
- Msaf: Multimodal supervise-attention enhanced fusion for video anomaly detection. IEEE SPL, 29, 2022.
- Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time. In ICML. PMLR, 2022.
- Vadclip: Adapting vision-language models for weakly supervised video anomaly detection. arXiv preprint arXiv:2308.11681, 2023.
- A unified framework for multi-modal federated learning. Neurocomputing, 480, 2022.
- Understanding the robustness of multi-modal contrastive learning to distribution shift. arXiv preprint arXiv:2310.04971, 2023.
- Mitigating biases in multimodal personality assessment. In ICMI, 2020.
- Defending multimodal fusion models against single-source adversaries. In CVPR, 2021.
- Multimodal federated learning via contrastive representation ensemble. In ICLR, 2022.
- Delving into clip latent space for video anomaly recognition. arXiv preprint arXiv:2310.02835, 2023.
- Towards adversarial attack on vision-language pre-training models. In ACM MM, 2022.
- Forget-me-not: Learning to forget in text-to-image diffusion models. arXiv preprint arXiv:2303.17591, 2023.
- Provable dynamic fusion for low-quality multimodal data. arXiv preprint arXiv:2306.02050, 2023.
- Anomalyclip: Object-agnostic prompt learning for zero-shot anomaly detection. arXiv preprint arXiv:2310.18961, 2023.
- Advclip: Downstream-agnostic adversarial examples in multimodal contrastive learning. In ACM MM, 2023.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.