- The paper derives novel empirical Freedman-type martingale concentration bounds to rigorously show that compute-optimal LLMs generalize better as scale increases.
- It decomposes generalization gaps into parameters per token, loss variance, and quantization error, demonstrating that larger models exhibit lower loss variance and quantization errors.
- The findings highlight practical implications for developing efficient quantization techniques and model architectures that capitalize on scaling laws for improved performance.
Compute-Optimal LLMs Provably Generalize Better With Scale
Introduction
The paper "Compute-Optimal LLMs Provably Generalize Better with Scale" (2504.15208) explores the understanding of why larger LLMs tend to perform better in terms of generalization, particularly when trained in the compute-optimal regime. Utilizing Chinchilla scaling laws, the authors develop novel generalization bounds for LLMs, applying a new Freedman-type martingale concentration inequality. This work is pivotal because it deciphers the compositional factors of generalization bounds, namely parameters per token, loss variance, and quantization error at fixed bitrates, proposing they reduce as model sizes increase.
Methodological Advances
The core methodology employs a novel empirical Freedman-type martingale concentration inequality, enhancing traditional bounds by incorporating loss variance. The paper decomposes the generalization bound into three main components: parameters per token, loss variance, and quantization error. By adhering to the compute-optimal scaling laws, these components suggest that larger models exhibit reduced generalization gaps primarily due to decreased loss variance and quantization errors despite constant parameters per data point.
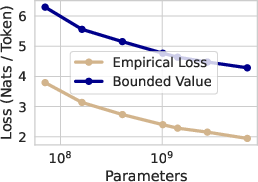
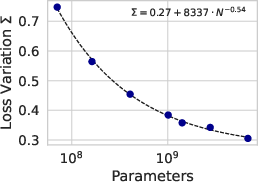
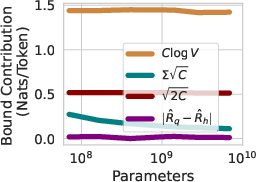
Figure 1: Left: A direct comparison of our evaluated generalization bound, and the empirical loss as a function of model scale. As the model is scaled up, our bound improves just like the empirical loss. Center: Loss variation Σ entering into the generalization bound. As the loss deviation decreases, so does the largest term in our bound. Right: Comparison of the relative scale of the contributions to \autoref{eq:full_theorem}.
Theoretical Insights
The theoretical framework is built on establishing token-wise generalization gaps using martingale methods. The paper introduces the prediction smoothing concept for negative log likelihood objectives, incorporating worst-case behavior and smoothing for bound variability. It sets the foundation for empirical evaluations using models sized from 70 million to 12 billion parameters from the Pythia family, established against standard empirical risks and consistent checking of Chinchilla scaling law adherence.
The empirical analyses exhibit that as model size increases, the generalization gap decreases according to a predictable law. The paper articulates improved generalization, predominantly enabled by decreased loss variance that aligns with empirical reduction trends in the quantization gap.
Practical Implications
Practically, this work signifies that as we push towards larger LLMs while controlling the computational budget, generalization improves due to better efficiency in parameter utilization and information encoding. For practitioners, this implies a need to focus on developing quantization techniques and architectures that leverage this reduced generalization gap as models get larger.
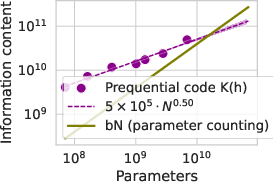
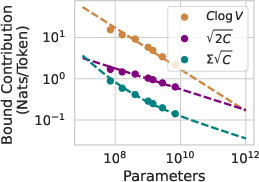
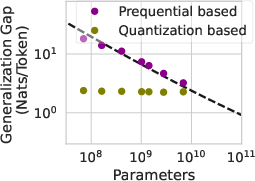
Figure 2: Left: Information content contained in the model as upper bounded by K(h) from the information transfer prequential coding approach vs parameter counting and quantization. Fitting a power law to the prequential K(h) yields 6×105⋅N0.5±0.1.
Future Directions
The paper opens multiple avenues for future research. Primarily, refining the complexity components of the generalization bounds, specifically the loss variation factor, and examining these bounds' implications on different architectures and training scenarios remain areas ripe for exploration. Addressing why the Hessian spectrum decays rapidly with model scale, facilitating easier quantization, is another pivotal research question arising from this work.
Moreover, the transition from theoretical upper bounds to practical algorithmic innovations in efficient model compression and deployment can augment LLM application across resource-constrained environments. Understanding and potentially further reducing the generalization gap through novel architectures and quantization methods may significantly enhance model applicability and accuracy.
Conclusion
This research paves the path to understanding why large-scale models in compute-optimal settings inherently generalize better, supported by sophisticated theoretical bounds and corroborated with empirical results. These insights align with the scaling trends of modern LLMs and provide robust theoretical backing for scaling laws, suggesting efficient strategies for further research and development in the field of LLMs.