- The paper introduces a novel two-stage pipeline that uses supervised feature extraction and fine-tuned language models to generate detailed explanations of fashion item compatibility.
- The paper constructs the PFE dataset of 6,407 manually filtered sentences to enhance training quality with specific fashion item features.
- The pipeline outperforms baseline models by achieving higher BLEURT and ROUGE scores, indicating improved alignment with ground-truth compatibility explanations.
Introduction
The paper "Deciphering Compatibility Relationships with Textual Descriptions via Extraction and Explanation" (2312.11554) addresses the challenge of explaining compatibility relationships between fashion items. This study is motivated by the limitations of current models, which often provide rudimentary and repetitive explanations for fashion item pairings. The authors introduce the Pair Fashion Explanation (PFE) dataset, a meticulously curated resource intended to enhance the generation of insightful explanations for these compatibility relationships. The paper proposes a two-stage pipeline model that leverages both large datasets of user interactions and the PFE dataset to generate explanations that align with ground-truth compatibility relationships.
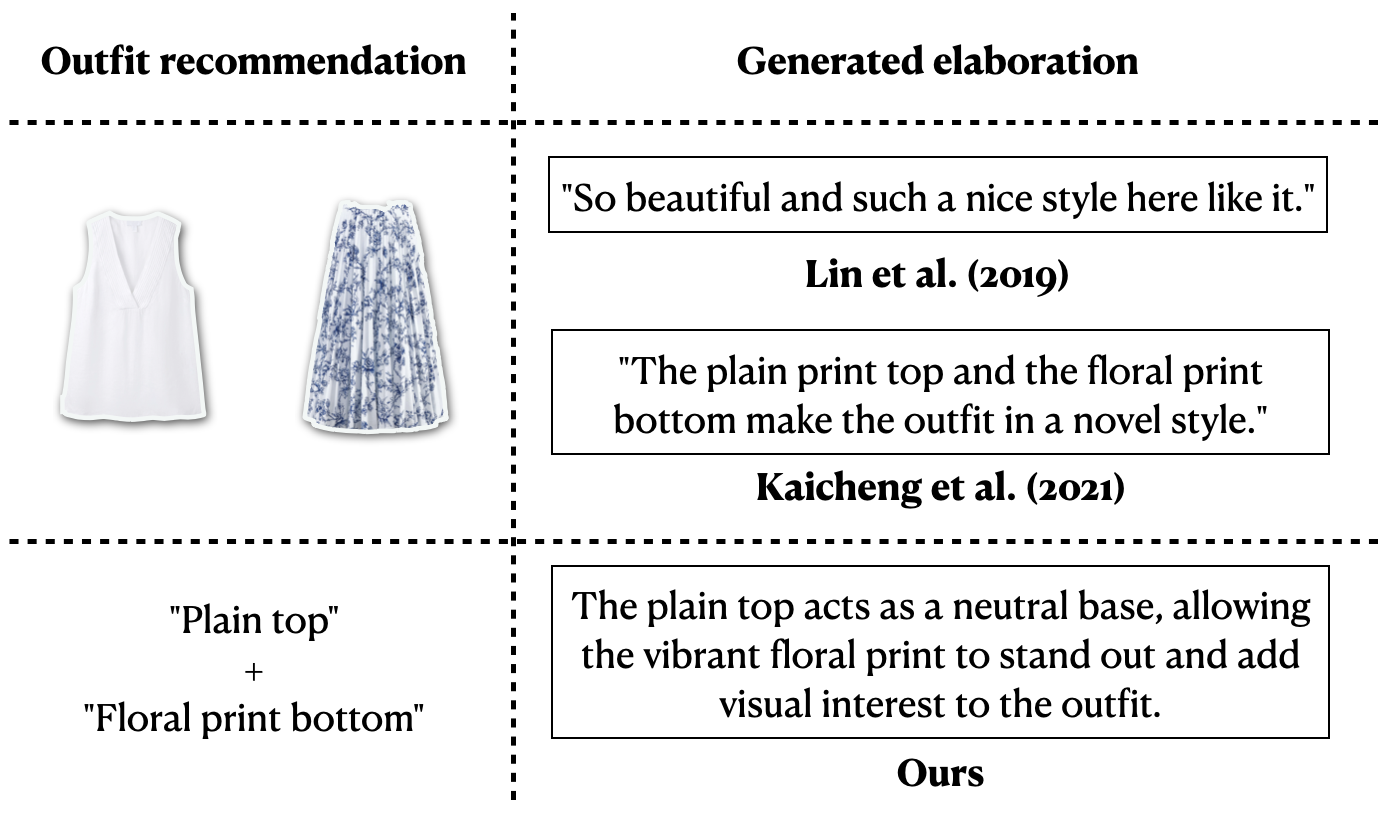
Figure 1: Our task is generating natural language descriptions to explain compatibility relationships between items.
Methodology
Two-Stage Pipeline
The authors present a novel two-stage pipeline approach:
- Feature Extraction: Leveraging a large general dataset, the first stage trains a feature extraction model (fθ) to identify significant features from item descriptions. It does this by using supervised learning, discerning between positive and negative pairs to determine compatibility features.
- Explanation Generation: In the second stage, a fine-tuned LLM (gφ) generates detailed explanations for item compatibility using the features extracted in the first stage. This step is fine-tuned on the PFE dataset, which contains dense, high-quality explanations for compatibility.
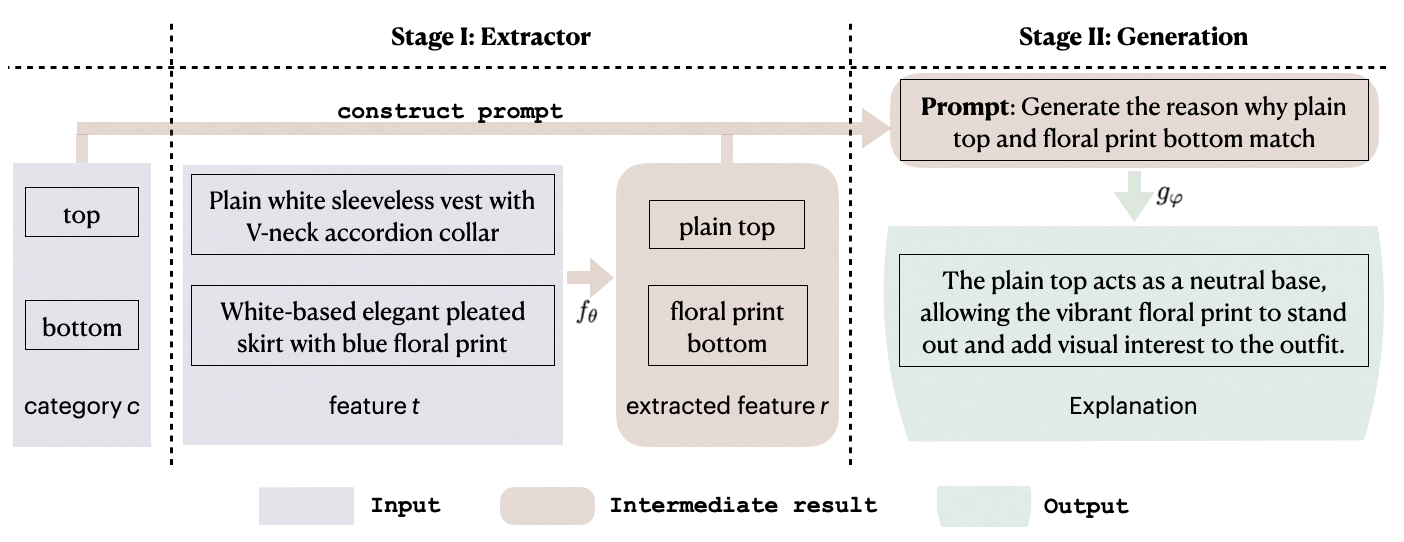
Figure 2: Overall Proposed Pipeline. The features t (in the form of a bag of words) of two items are input into the extraction model fθ to obtain the extracted features r, which are then used as prompts for the generation model gφ.
PFE Dataset Construction
The dataset construction involves several steps:
- Entity Extraction: Sentences from public sources are filtered based on the presence of specific entities relevant to fashion items.
- Manual Labeling and Filtering: Using Named Entity Recognition (NER) and expert filtering, the authors distill a set of 6,407 sentences from an initial corpus of over 959,157 sentences.
- Feature and Category Tagging: Each sentence in the dataset is tagged with specific items, their features, and the corresponding categorical information, creating a rich dataset for model training.
Experimental Results
The performance of the proposed model is evaluated using several automated metrics:
- BLEU and ROUGE: These scores measure the similarity of generated explanations to ground-truth data, reflecting both lexical and semantic alignment.
- BLEURT and FID: BLEURT scores indicate semantic similarity, while Frechet Inception Distance (FID) measures distributional similarity between generated and real-world explanations.
Comparison with Baselines
The two-stage model significantly outperforms baseline models such as PEPLER and general-purpose LLMs like ChatGPT. The model trained on the PFE dataset yields higher BLEURT and ROUGE scores, indicating the efficacy of domain-specific data in enhancing the quality of explanations.
Implications and Future Work
The proposed pipeline offers a viable solution for improving not only fashion recommendation systems but also other domains requiring interpretability in pairwise compatibility assessments, such as interior design and device interoperability. Future work could explore extending this framework to multi-object compatibility relationships, enhancing the breadth and applicability of the approach.
Conclusion
The introduction of the PFE dataset and the two-stage pipeline provides a substantial advancement in generating explanatory descriptions of fashion item compatibility. By finely tuning LLMs to a specialized dataset, the study demonstrates improved explanation quality and alignment with expert assessments. This framework paves the way for broader applications and more nuanced recommendation systems across various domains.