- The paper introduces a self-detection method that uses paraphrase consistency to flag non-factual knowledge in LLM responses.
- It leverages both response divergence and negative log-likelihood of inputs to quantify uncertainty and atypicality.
- Experimental results show improved precision-recall metrics over existing techniques in factoid, arithmetic, and commonsense tasks.
Knowing What LLMs DO NOT Know: A Simple Yet Effective Self-Detection Method
The paper "Knowing What LLMs DO NOT Know: A Simple Yet Effective Self-Detection Method" (2310.17918) introduces a novel self-detection technique for identifying gaps in knowledge within LLMs. The approach aims to discern whether an LLM does not know the answer to a particular question, by leveraging the model's own outputs without needing external resources. This essay will elaborate on key components, methodologies, and findings presented in the paper.
Introduction to Self-Detection Method
The proposed self-detection method focuses on identifying questions where LLMs like Llama 2, Vicuna, ChatGPT, and GPT-4 produce non-factual responses. The core hypotheses are that non-factuality arises from either a lack of understanding of the question or ignorance of the relevant knowledge. The method involves two primary mechanisms:
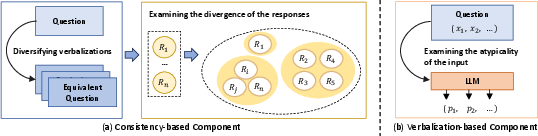
- Behavioral Divergence: By presenting semantically equivalent questions in different verbalizations, the LLM's divergence in responses can indicate uncertainty or non-factuality (Figure 1).
- Input Atypicality: The LLM's confidence regarding a question can also indicate non-factuality. This is measured using the atypicality of the verbalized input, determined through negative log-likelihood.
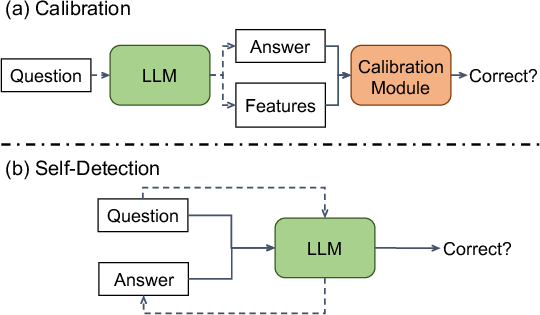
Figure 1: Two paradigms for detecting hallucinations. The dashed lines denote the LLM generation process. The solid lines denote non-factuality detection.
Framework and Implementation
Consistence-based Detection
For this component, the first step involves generating diverse paraphrases for a given question to enrich the input representation. The LLM then produces responses for these rephrased questions, allowing the model's self-consistency to be examined. If the responses differ significantly or unpredictably, it suggests the model's uncertainty or ignorance of the knowledge underlying the question.
Diversifying Question Verbalizations
- Model-based Generation: Utilizes LLMs such as ChatGPT or Vicuna to generate semantically equivalent paraphrases.
- Rule-based Generation: Applies predefined rules to craft variations of arithmetic and commonsense reasoning questions.
Calculating Consistency Score
Verbalization-based Detection
Atypical verbalizations reveal whether a question formulation is representative within the model's architecture. The paper employs the negative log-likelihood of the input as a gauge for atypicality. This involves computation across tokens to evaluate how non-representative the question is within the data distribution the model was trained on.
Experiments and Results
The effectiveness of the self-detection approach was validated through experiments on multiple datasets and LLMs, including factoid question answering, arithmetic reasoning, and commonsense reasoning. The self-detection method surpasses existing techniques like TokenProbs and SelfCheckGPT in precision-recall metrics (Figure 3).
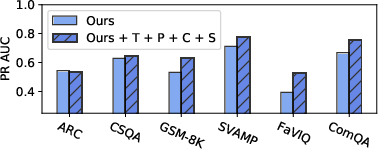
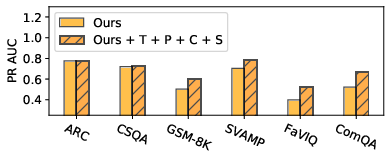
Figure 3: The PR AUC when combining our method and previous proposed TokenProbs (T), Perplexity (P), ConsistAnswers (C), and SelfCheckGPT (S).
Implications and Future Work
The study illustrates that current LLMs exhibit specific vulnerabilities in knowledge representation, particularly concerning less popular, abstract, or atypical concepts. Future research could integrate external verification systems or develop hybrid detection models that utilize both internal and external knowledge resources to enhance model reliability.
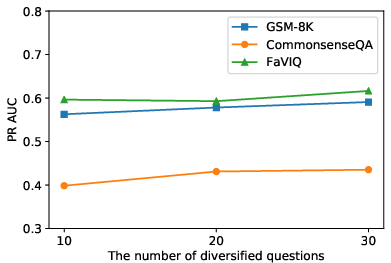
Figure 4: The performance of different numbers of diversified questions for the self-detection.
Conclusion
The self-detection method put forth in this paper provides a robust, adaptable strategy for identifying LLMs' unknowns, enhancing their reliability across diverse tasks. By addressing both behavioral divergence and input atypicality, this approach offers quantifiable insights into a model's uncertainties, paving the way for more transparent and dependable AI systems. Future enhancements will need to tackle eloquent question representation and assess broader real-world applications.