Beyond the Chat: Executable and Verifiable Text-Editing with LLMs
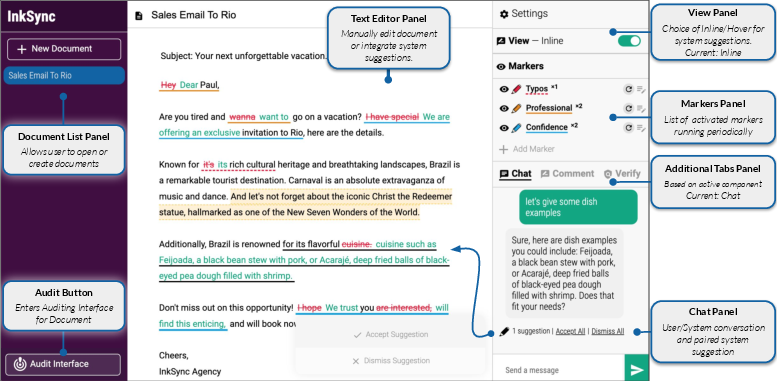
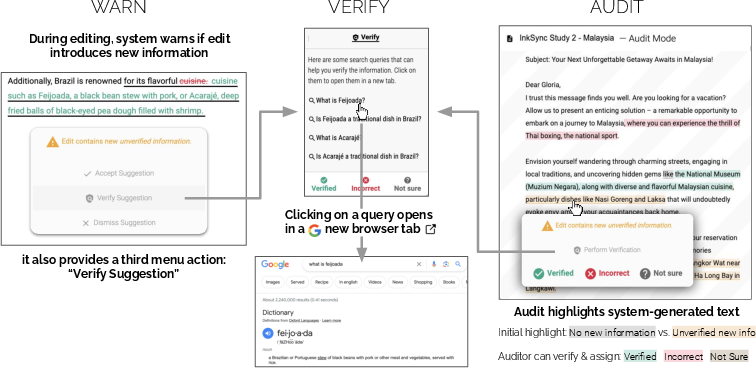
Abstract: Conversational interfaces powered by LLMs have recently become a popular way to obtain feedback during document editing. However, standard chat-based conversational interfaces do not support transparency and verifiability of the editing changes that they suggest. To give the author more agency when editing with an LLM, we present InkSync, an editing interface that suggests executable edits directly within the document being edited. Because LLMs are known to introduce factual errors, Inksync also supports a 3-stage approach to mitigate this risk: Warn authors when a suggested edit introduces new information, help authors Verify the new information's accuracy through external search, and allow an auditor to perform an a-posteriori verification by Auditing the document via a trace of all auto-generated content. Two usability studies confirm the effectiveness of InkSync's components when compared to standard LLM-based chat interfaces, leading to more accurate, more efficient editing, and improved user experience.
- The (un) suitability of automatic evaluation metrics for text simplification. Computational Linguistics 47, 4 (2021), 861–889.
- On suggesting phrases vs. predicting words for mobile text composition. In Proceedings of the 29th Annual Symposium on User Interface Software and Technology. 603–608.
- A multitask, multilingual, multimodal evaluation of chatgpt on reasoning, hallucination, and interactivity. arXiv preprint arXiv:2302.04023 (2023).
- Soylent: a word processor with a crowd inside. In Proceedings of the 23nd annual ACM symposium on User interface software and technology. 313–322.
- From tool to companion: Storywriters want AI writers to respect their personal values and writing strategies. In Designing Interactive Systems Conference. 1209–1227.
- Carlo E Bonferroni. 1935. Il calcolo delle assicurazioni su gruppi di teste. Studi in onore del professore salvatore ortu carboni (1935), 13–60.
- Collaborative writing with Web 2.0 technologies: education students’ perceptions. (2011).
- The impact of multiple parallel phrase suggestions on email input and composition behaviour of native and non-native english writers. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems. 1–13.
- How Novelists Use Generative Language Models: An Exploratory User Study.. In HAI-GEN+ user2agent@ IUI.
- Help me write a Poem-Instruction Tuning as a Vehicle for Collaborative Poetry Writing. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 6848–6863.
- Next Steps for Human-Centered Generative AI: A Technical Perspective. arXiv preprint arXiv:2306.15774 (2023).
- Decontextualization: Making sentences stand-alone. Transactions of the Association for Computational Linguistics 9 (2021), 447–461.
- TaleBrush: Sketching stories with generative pretrained language models. In Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems. 1–19.
- Creative writing with a machine in the loop: Case studies on slogans and stories. In 23rd International Conference on Intelligent User Interfaces. 329–340.
- Wordcraft: a human-ai collaborative editor for story writing. arXiv preprint arXiv:2107.07430 (2021).
- The AI Ghostwriter Effect: Users Do Not Perceive Ownership of AI-Generated Text But Self-Declare as Authors. arXiv preprint arXiv:2303.03283 (2023).
- Read, Revise, Repeat: A System Demonstration for Human-in-the-loop Iterative Text Revision. In2Writing 2022 (2022), 96.
- Understanding Iterative Revision from Human-Written Text. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 3573–3590.
- Bradley Efron. 1982. The Jackknife, the Bootstrap and other resampling plans. In CBMS-NSF Regional Conference Series in Applied Mathematics.
- QAFactEval: Improved QA-Based Factual Consistency Evaluation for Summarization. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2587–2601.
- Experts, errors, and context: A large-scale study of human evaluation for machine translation. Transactions of the Association for Computational Linguistics 9 (2021), 1460–1474.
- Enabling Large Language Models to Generate Text with Citations. arXiv preprint arXiv:2305.14627 (2023).
- A design space for writing support tools using a cognitive process model of writing. In Proceedings of the First Workshop on Intelligent and Interactive Writing Assistants (In2Writing 2022). 11–24.
- Sparks: Inspiration for science writing using language models. In Designing interactive systems conference. 1002–1019.
- Social dynamics of AI support in creative writing. In Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems. 1–15.
- Tanya Goyal and Greg Durrett. 2021. Annotating and Modeling Fine-grained Factuality in Summarization. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 1449–1462.
- Joy Paul Guilford. 1967. The nature of human intelligence. (1967).
- A survey on automated fact-checking. Transactions of the Association for Computational Linguistics 10 (2022), 178–206.
- Passages: interacting with text across documents. In Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems. 1–17.
- Measuring massive multitask language understanding. arXiv preprint arXiv:2009.03300 (2020).
- TRUE: Re-evaluating Factual Consistency Evaluation. In Proceedings of the Second DialDoc Workshop on Document-grounded Dialogue and Conversational Question Answering. 161–175.
- The Case for a Single Model that can Both Generate Continuations and Fill-in-the-Blank. In Findings of the Association for Computational Linguistics: NAACL 2022. 2421–2432.
- Threddy: An Interactive System for Personalized Thread-based Exploration and Organization of Scientific Literature. In Proceedings of the 35th Annual ACM Symposium on User Interface Software and Technology. 1–15.
- Tae Wook Kim and Quan Tan. 2023. Repurposing Text-Generating AI into a Thought-Provoking Writing Tutor. arXiv preprint arXiv:2304.10543 (2023).
- Neural Text Summarization: A Critical Evaluation. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 540–551.
- LLMs as Factual Reasoners: Insights from Existing Benchmarks and Beyond. arXiv preprint arXiv:2305.14540 (2023).
- Keep It Simple: Unsupervised Simplification of Multi-Paragraph Text. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). 6365–6378.
- SummaC: Re-visiting NLI-based models for inconsistency detection in summarization. Transactions of the Association for Computational Linguistics 10 (2022), 163–177.
- SWiPE: A Dataset for Document-Level Simplification of Wikipedia Pages. Proceedings of the 61th Annual Meeting of the Association for Computational Linguistics (2023).
- Coauthor: Designing a human-ai collaborative writing dataset for exploring language model capabilities. In Proceedings of the 2022 CHI conference on human factors in computing systems. 1–19.
- Evaluating human-language model interaction. arXiv preprint arXiv:2212.09746 (2022).
- Suggestion lists vs. continuous generation: Interaction design for writing with generative models on mobile devices affect text length, wording and perceived authorship. In Proceedings of Mensch und Computer 2022. 192–208.
- Vladimir I. Levenshtein. 1966. Binary Codes Capable of Correcting Deletions, Insertions and Reversals. Soviet physics. Doklady 10 (1966), 707–710.
- Evaluating verifiability in generative search engines. arXiv preprint arXiv:2304.09848 (2023).
- LENS: A Learnable Evaluation Metric for Text Simplification. arXiv preprint arXiv:2212.09739 (2022).
- On Faithfulness and Factuality in Abstractive Summarization. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 1906–1919.
- Co-Writing Screenplays and Theatre Scripts with Language Models: Evaluation by Industry Professionals. In Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems. 1–34.
- Fake news detection: A hybrid CNN-RNN based deep learning approach. International Journal of Information Management Data Insights 1, 1 (2021), 100007.
- WearWrite: Crowd-assisted writing from smartwatches. In Proceedings of the 2016 CHI conference on human factors in computing systems. 3834–3846.
- OpenAI. 2023. GPT-4 Technical Report. ArXiv abs/2303.08774 (2023).
- Training language models to follow instructions with human feedback. arXiv preprint arXiv:2203.02155 (2022).
- Vishakh Padmakumar and He He. 2023. Does Writing with Language Models Reduce Content Diversity? arXiv preprint arXiv:2309.05196 (2023).
- Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics. 311–318.
- Automatically neutralizing subjective bias in text. In Proceedings of the aaai conference on artificial intelligence, Vol. 34. 480–489.
- CoEdIT: Text Editing by Task-Specific Instruction Tuning. arXiv preprint arXiv:2305.09857 (2023).
- Joseph M Reagle Jr. 2010. “Be Nice”: Wikipedia norms for supportive communication. New Review of Hypermedia and Multimedia 16, 1-2 (2010), 161–180.
- A Recipe for Arbitrary Text Style Transfer with Large Language Models. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). 837–848.
- Jeba Rezwana and Mary Lou Maher. 2022. Identifying ethical issues in ai partners in human-ai co-creation. arXiv preprint arXiv:2204.07644 (2022).
- Melissa Roemmele and Andrew S Gordon. 2018. Automated assistance for creative writing with an rnn language model. In Proceedings of the 23rd international conference on intelligent user interfaces companion. 1–2.
- Revisiting non-English Text Simplification: A Unified Multilingual Benchmark. arXiv preprint arXiv:2305.15678 (2023).
- Characterizing stage-aware writing assistance for collaborative document authoring. Proceedings of the ACM on Human-Computer Interaction 4, CSCW3 (2021), 1–29.
- Toolformer: Language models can teach themselves to use tools. arXiv preprint arXiv:2302.04761 (2023).
- Peer: A collaborative language model. arXiv preprint arXiv:2208.11663 (2022).
- Combating fake news: A survey on identification and mitigation techniques. ACM Transactions on Intelligent Systems and Technology (TIST) 10, 3 (2019), 1–42.
- Beyond Summarization: Designing AI Support for Real-World Expository Writing Tasks. arXiv preprint arXiv:2304.02623 (2023).
- Where to hide a stolen elephant: Leaps in creative writing with multimodal machine intelligence. ACM Transactions on Computer-Human Interaction (2022).
- Supporting collaborative writing with microtasks. In Proceedings of the 2016 CHI conference on human factors in computing systems. 2657–2668.
- FEVER: a Large-scale Dataset for Fact Extraction and VERification. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers). 809–819.
- Ellis Paul Torrance. 1966. Torrance tests of creative thinking: Norms-technical manual: Verbal tests, forms a and b: Figural tests, forms a and b. Personal Press, Incorporated.
- LLMs as Workers in Human-Computational Algorithms? Replicating Crowdsourcing Pipelines with LLMs. arXiv preprint arXiv:2307.10168 (2023).
- Yonghui Wu. 2018. Smart compose: Using neural networks to help write emails. Google AI Blog (2018).
- Problems in current text simplification research: New data can help. Transactions of the Association for Computational Linguistics 3 (2015), 283–297.
- Optimizing statistical machine translation for text simplification. Transactions of the Association for Computational Linguistics 4 (2016), 401–415.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.