GPTFUZZER: Red Teaming Large Language Models with Auto-Generated Jailbreak Prompts
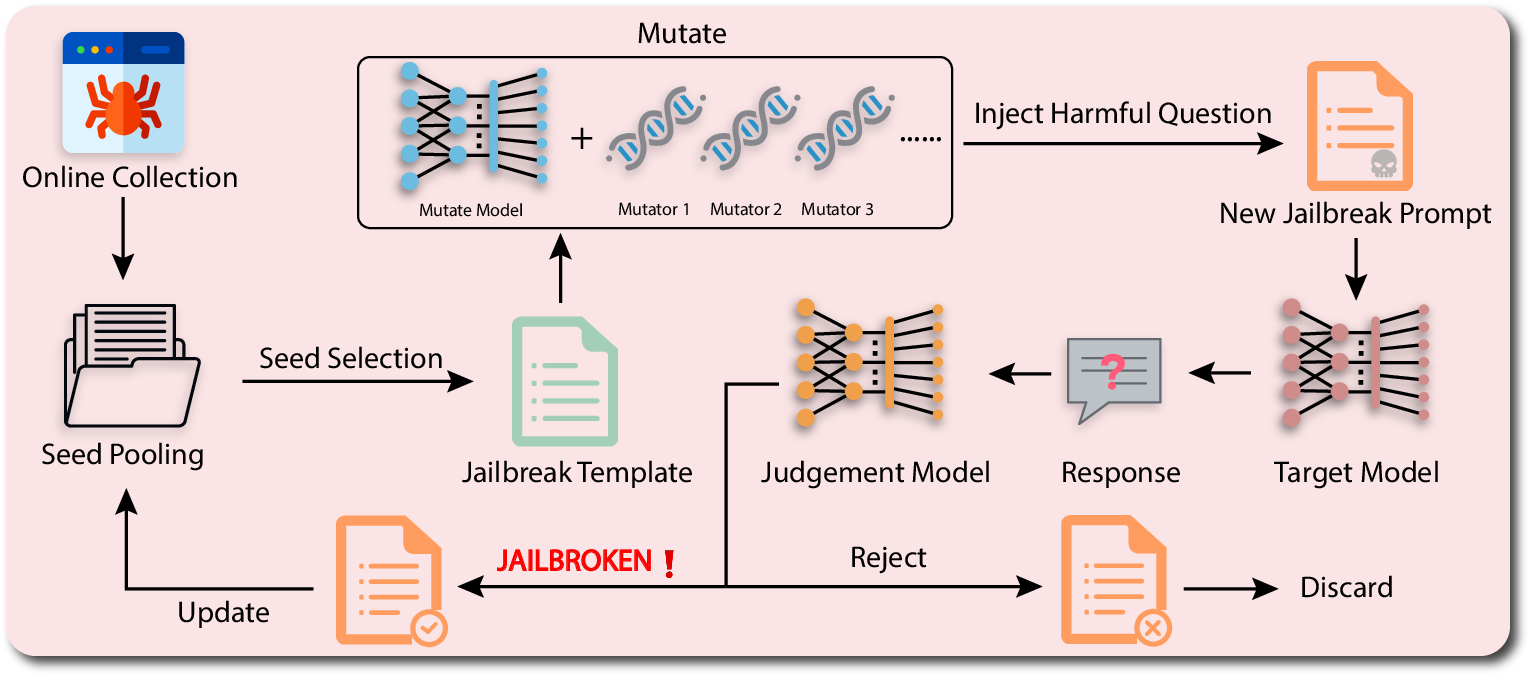
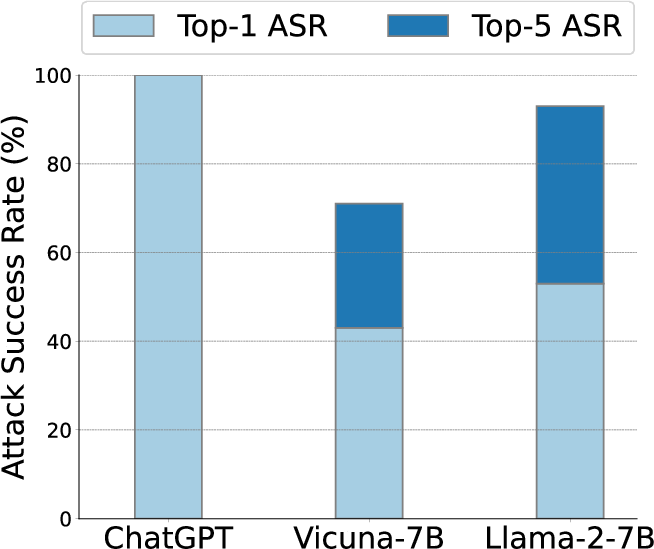
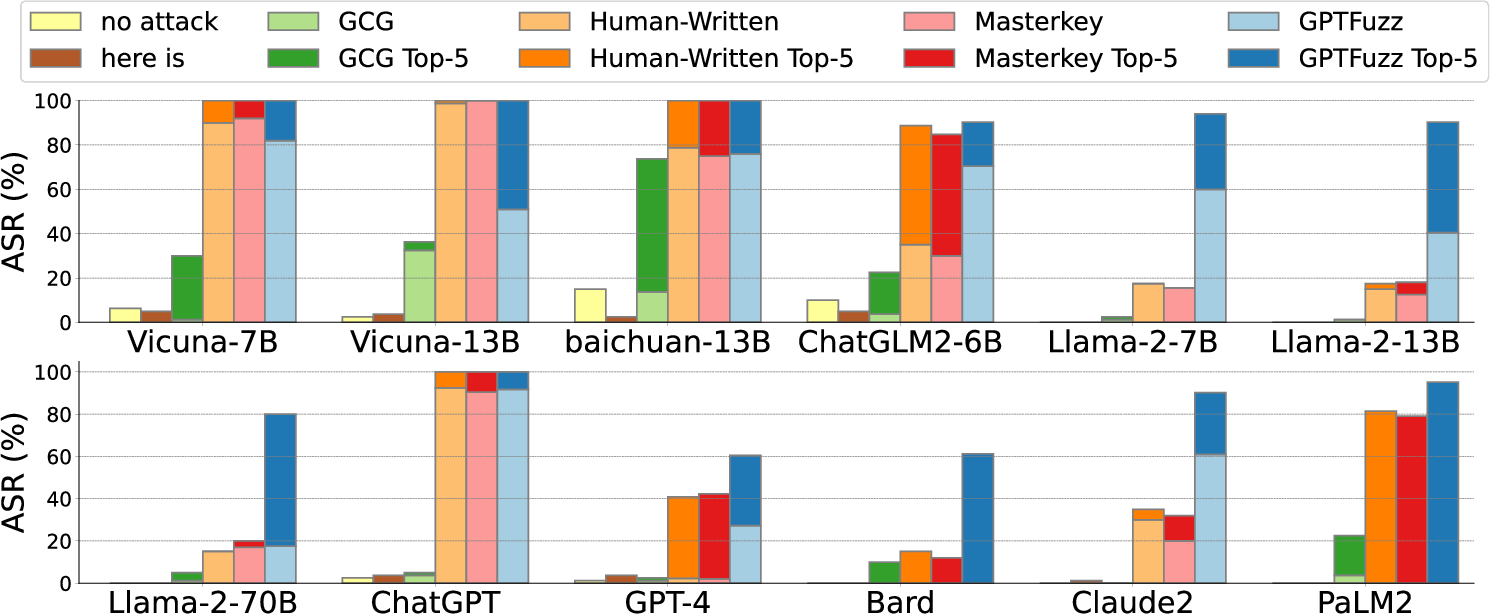
Abstract: LLMs have recently experienced tremendous popularity and are widely used from casual conversations to AI-driven programming. However, despite their considerable success, LLMs are not entirely reliable and can give detailed guidance on how to conduct harmful or illegal activities. While safety measures can reduce the risk of such outputs, adversarial jailbreak attacks can still exploit LLMs to produce harmful content. These jailbreak templates are typically manually crafted, making large-scale testing challenging. In this paper, we introduce GPTFuzz, a novel black-box jailbreak fuzzing framework inspired by the AFL fuzzing framework. Instead of manual engineering, GPTFuzz automates the generation of jailbreak templates for red-teaming LLMs. At its core, GPTFuzz starts with human-written templates as initial seeds, then mutates them to produce new templates. We detail three key components of GPTFuzz: a seed selection strategy for balancing efficiency and variability, mutate operators for creating semantically equivalent or similar sentences, and a judgment model to assess the success of a jailbreak attack. We evaluate GPTFuzz against various commercial and open-source LLMs, including ChatGPT, LLaMa-2, and Vicuna, under diverse attack scenarios. Our results indicate that GPTFuzz consistently produces jailbreak templates with a high success rate, surpassing human-crafted templates. Remarkably, GPTFuzz achieves over 90% attack success rates against ChatGPT and Llama-2 models, even with suboptimal initial seed templates. We anticipate that GPTFuzz will be instrumental for researchers and practitioners in examining LLM robustness and will encourage further exploration into enhancing LLM safety.
- Palm 2 technical report. arXiv preprint arXiv:2305.10403, 2023.
- Anthropic. Introducing claude. https://www.anthropic.com/index/introducing-claude. Accessed on 08/08/2023.
- Finite-time analysis of the multiarmed bandit problem. Machine Learning, 47(2-3):235–256, 2002.
- Efficient greybox fuzzing to detect memory errors. In Proceedings of the 37th IEEE/ACM International Conference on Automated Software Engineering, pages 1–12, 2022.
- Spinning language models: Risks of propaganda-as-a-service and countermeasures. In Proc. of IEEE Symposium on Security and Privacy (SP). IEEE, 2022.
- Training a helpful and harmless assistant with reinforcement learning from human feedback. arXiv preprint arXiv:2204.05862, 2022.
- Baichuan-Inc. Baichuan-13b. https://github.com/baichuan-inc/Baichuan-13B. Accessed on 08/08/2023.
- Lea Bishop. A computer wrote this paper: What chatgpt means for education, research, and writing. Research, and Writing (January 26, 2023), 2023.
- Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
- Sparks of artificial general intelligence: Early experiments with gpt-4. arXiv preprint arXiv:2303.12712, 2023.
- How is chatgpt’s behavior changing over time? arXiv preprint arXiv:2307.09009, 2023.
- Tzeng-Ji Chen. Chatgpt and other artificial intelligence applications speed up scientific writing. Journal of the Chinese Medical Association, 86(4):351–353, 2023.
- Rémi Coulom. Efficient selectivity and backup operators in monte-carlo tree search. Computers and games, 4630:72–83, 2006.
- Jailbreaker: Automated jailbreak across multiple large language model chatbots. arXiv preprint arXiv:2307.08715, 2023.
- Toxicity in chatgpt: Analyzing persona-assigned language models. arXiv preprint arXiv:2304.05335, 2023.
- Dynamic symbolic execution guided by data dependency analysis for high structural coverage. In Evaluation of Novel Approaches to Software Engineering: 7th International Conference, ENASE 2012, Warsaw, Poland, June 29-30, 2012, Revised Selected Papers 7, pages 3–15. Springer, 2013.
- Glm: General language model pretraining with autoregressive blank infilling. arXiv preprint arXiv:2103.10360, 2021.
- Snipuzz: Black-box fuzzing of iot firmware via message snippet inference. In Proceedings of the 2021 ACM SIGSAC Conference on Computer and Communications Security, pages 337–350, 2021.
- Libafl: A framework to build modular and reusable fuzzers. In Proceedings of the 2022 ACM SIGSAC Conference on Computer and Communications Security, pages 1051–1065, 2022.
- Dyta: dynamic symbolic execution guided with static verification results. In Proceedings of the 33rd International Conference on Software Engineering, pages 992–994, 2011.
- Realtoxicityprompts: Evaluating neural toxic degeneration in language models. arXiv preprint arXiv:2009.11462, 2020.
- Google. Bard. https://bard.google.com/. Accessed on 08/08/2023.
- Not what you’ve signed up for: Compromising real-world llm-integrated applications with indirect prompt injection. arXiv preprint arXiv:2302.12173, 2023.
- On calibration of modern neural networks. In International conference on machine learning, pages 1321–1330. PMLR, 2017.
- Seed selection for successful fuzzing. In Proceedings of the 30th ACM SIGSOFT international symposium on software testing and analysis, pages 230–243, 2021.
- Balance seed scheduling via monte carlo planning. IEEE Transactions on Dependable and Secure Computing, 2023.
- Diar: Removing uninteresting bytes from seeds in software fuzzing. arXiv preprint arXiv:2112.13297, 2021.
- Smart seed selection-based effective black box fuzzing for iiot protocol. The Journal of Supercomputing, 76:10140–10154, 2020.
- Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- Learning seed-adaptive mutation strategies for greybox fuzzing. In 2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE), pages 384–396. IEEE, 2023.
- Multi-step jailbreaking privacy attacks on chatgpt. arXiv preprint arXiv:2304.05197, 2023.
- Multi-target backdoor attacks for code pre-trained models. arXiv preprint arXiv:2306.08350, 2023.
- Truthfulqa: Measuring how models mimic human falsehoods. arXiv preprint arXiv:2109.07958, 2021.
- Adversarial training for large neural language models. arXiv preprint arXiv:2004.08994, 2020.
- Gpteval: Nlg evaluation using gpt-4 with better human alignment. arXiv preprint arXiv:2303.16634, 2023.
- Prompt injection attack against llm-integrated applications. arXiv preprint arXiv:2306.05499, 2023.
- Jailbreaking chatgpt via prompt engineering: An empirical study. arXiv preprint arXiv:2305.13860, 2023.
- Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692, 2019.
- Directed symbolic execution. In Static Analysis: 18th International Symposium, SAS 2011, Venice, Italy, September 14-16, 2011. Proceedings 18, pages 95–111. Springer, 2011.
- A holistic approach to undesired content detection in the real world. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 37, pages 15009–15018, 2023.
- Notable: Transferable backdoor attacks against prompt-based nlp models. arXiv preprint arXiv:2305.17826, 2023.
- An empirical study of the reliability of unix utilities. Communications of the ACM, 33(12):32–44, 1990.
- Evaluating the robustness of neural language models to input perturbations. arXiv preprint arXiv:2108.12237, 2021.
- OpenAI. Introducing chatgpt. https://openai.com/blog/chatgpt, 2022. Accessed: 08/08/2023.
- OpenAI. Forecasting potential misuses of language models for disinformation campaigns and how to reduce risk. https://openai.com/research/forecasting-misuse, 2023. Accessed: 08/08/2023.
- OpenAI. Function calling and other api updates. https://openai.com/blog/function-calling-and-other-api-updates, 2023. Accessed: 08/08/2023.
- OpenAI. Gpt-4 technical report. ArXiv, abs/2303.08774, 2023.
- Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35:27730–27744, 2022.
- Ignore previous prompt: Attack techniques for language models. arXiv preprint arXiv:2211.09527, 2022.
- Xstest: A test suite for identifying exaggerated safety behaviours in large language models. arXiv preprint arXiv:2308.01263, 2023.
- Drifuzz: Harvesting bugs in device drivers from golden seeds. In 31st USENIX Security Symposium (USENIX Security 22), pages 1275–1290, 2022.
- Process for adapting language models to society (palms) with values-targeted datasets. Advances in Neural Information Processing Systems, 34:5861–5873, 2021.
- Safety assessment of chinese large language models. arXiv preprint arXiv:2304.10436, 2023.
- MosaicML NLP Team. Introducing mpt-7b: A new standard for open-source, commercially usable llms, 2023. Accessed: 08/08/2023.
- Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023.
- Toss a fault to your witcher: Applying grey-box coverage-guided mutational fuzzing to detect sql and command injection vulnerabilities. In 2023 IEEE Symposium on Security and Privacy (SP), pages 2658–2675. IEEE, 2023.
- Attention is all you need. Advances in neural information processing systems, 30, 2017.
- syzkaller: unsupervised, coverage-guided kernel fuzzer. https://github.com/google/syzkaller, 2023. Accessed: 08/08/2023.
- Decodingtrust: A comprehensive assessment of trustworthiness in gpt models. arXiv preprint arXiv:2306.11698, 2023.
- {{\{{SyzVegas}}\}}: Beating kernel fuzzing odds with reinforcement learning. In 30th USENIX Security Symposium (USENIX Security 21), pages 2741–2758, 2021.
- Is chatgpt a good nlg evaluator? a preliminary study. arXiv preprint arXiv:2303.04048, 2023.
- Reinforcement learning-based hierarchical seed scheduling for greybox fuzzing. 2021.
- Self-critique prompting with large language models for inductive instructions. arXiv preprint arXiv:2305.13733, 2023.
- Jailbroken: How does llm safety training fail? arXiv preprint arXiv:2307.02483, 2023.
- Singularity: Pattern fuzzing for worst case complexity. In Proceedings of the 2018 26th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, pages 213–223, 2018.
- Challenges in detoxifying language models. arXiv preprint arXiv:2109.07445, 2021.
- One fuzzing strategy to rule them all. In Proceedings of the 44th International Conference on Software Engineering, pages 1634–1645, 2022.
- Cvalues: Measuring the values of chinese large language models from safety to responsibility. arXiv preprint arXiv:2307.09705, 2023.
- Gpt-4 is too smart to be safe: Stealthy chat with llms via cipher, 2023.
- {{\{{EcoFuzz}}\}}: Adaptive {{\{{Energy-Saving}}\}} greybox fuzzing as a variant of the adversarial {{\{{Multi-Armed}}\}} bandit. In 29th USENIX Security Symposium (USENIX Security 20), pages 2307–2324, 2020.
- Michał Zalewski. American fuzzy lop. http://lcamtuf.coredump.cx/afl/, 2023. Accessed: 08/08/2023.
- Mobfuzz: Adaptive multi-objective optimization in gray-box fuzzing. In Network and Distributed Systems Security (NDSS) Symposium, volume 2022, 2022.
- Fine-mixing: Mitigating backdoors in fine-tuned language models. arXiv preprint arXiv:2210.09545, 2022.
- Evolutionary mutation-based fuzzing as monte carlo tree search. arXiv preprint arXiv:2101.00612, 2021.
- Judging llm-as-a-judge with mt-bench and chatbot arena. arXiv preprint arXiv:2306.05685, 2023.
- Fine-tuning language models from human preferences. arXiv preprint arXiv:1909.08593, 2019.
- Universal and transferable adversarial attacks on aligned language models. arXiv preprint arXiv:2307.15043, 2023.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.