- The paper shows that batch normalization drives gradient descent away from max-margin solutions, leading to a uniform margin outcome in linear models and CNNs.
- It establishes that BN induces a super-polynomial convergence rate in margin uniformity, contrasting sharply with the slower rates of classic implicit bias.
- Empirical evidence demonstrates that uniform margin solutions obtained via BN can generalize better in structured prediction problems than traditional max-margin approaches.
The Implicit Bias of Batch Normalization in Linear Models and Two-layer Linear CNNs
Problem Overview and Motivation
This work provides a rigorous theoretical characterization of the implicit bias induced by Batch Normalization (BN) in the optimization dynamics of linear models and two-layer single-filter linear Convolutional Neural Networks (CNNs) trained via gradient descent. The central aim is to understand the precise form of the solutions gradient descent converges to under BN, elucidating both the qualitative differences from the classic setting without BN and the implications for generalization and learning dynamics.
The literature on implicit bias has established that, in linearly separable problems and without normalization, gradient descent on logistic loss converges to the ℓ2 maximum-margin solution [soudry2017implicit]. However, the effect of BN on implicit bias, even in the simplest homogeneous settings, was not well understood except for general KKT point characterizations [lyu2019gradient]. This work fills that gap by giving explicit constructions and convergence rates for the solutions found by gradient descent under BN.
Main Theoretical Contributions
The first main result shows that, for overparameterized linear binary classification with BN, gradient descent does not converge to the max-margin classifier. Instead, it produces a so-called uniform margin solution in which the normalized margin $y_i \langle \wb, \xb_i \rangle / \| \wb \|_{\bSigma}$ is identical for all training examples. More formally, the margin discrepancy
$D(\wb) = \frac{1}{n^2} \sum_{i,i'=1}^n \left[y_{i'}\frac{ \langle \wb, \xb_{i'} \rangle}{\| \wb \|_{\bSigma}} - y_i\frac{ \langle \wb, \xb_i \rangle}{\| \wb \|_{\bSigma}}\right]^2$
converges to 0 on the training data.
Strong result: The convergence rate is super-polynomial in t: $D(\wb^{(t)}) = O(\exp(-c\log^2 t))$, which is exponentially faster than the well-known O(1/logt) rate for the classic max-margin implicit bias (without batch normalization) [soudry2017implicit].
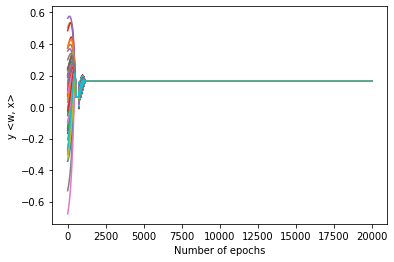
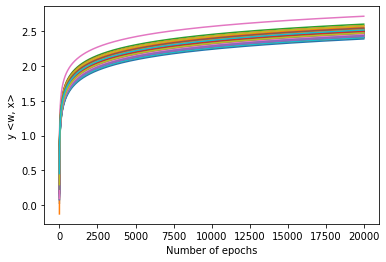
Figure 1: Dynamics of $y_i \langle \wb^{(t)}, \xb_i \rangle$ during gradient descent with (left) and without (right) batch normalization. With BN, margins collapse to a uniform value; without BN, margin dispersion persists.
The implicit bias result extends to two-layer, single-filter linear CNNs: the BN version does not find the usual max-margin solution, but a patch-wise uniform margin solution. Here, all patches (across all examples and positions) share the same normalized margin.
This behavior is unique to models with BN and cannot be generally attained by regression or classic maximum-margin optimization.
Empirical results demonstrate that the uniformity induced by BN also manifests at the neuron level in modern deep networks, such as VGG-16 (Figure 2), confirming theory-driven expectations even in more complex, nonlinear architectures.
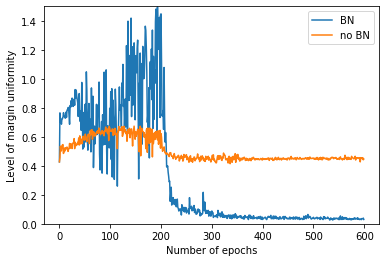
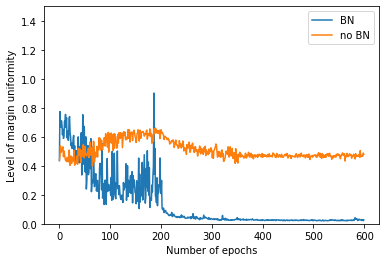
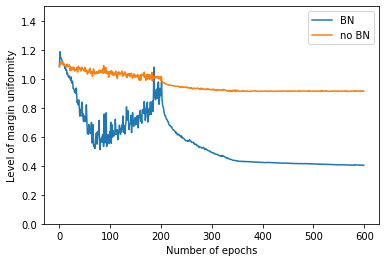
Figure 2: Margin uniformity statistics for neurons in VGG-16 with and without batch normalization, evaluated on class-specific and cross-class activations.
Comparative Generalization Efficacy
An important and nontrivial outcome is that uniform margin solutions may generalize better than max-margin solutions in certain structured data problems, especially in overparameterized or highly patch-redundant CNNs. The authors provide two explicit data models where patch-wise uniform margin classifiers outperform the maximum-margin alternative in test accuracy.
Technical Insights
The analysis leverages several technical innovations:
- Pairwise Margin Dynamics: The proof tracks the contraction in pairwise margin variability, relating gradient updates to margin discrepancy and showing monotonic improvement toward uniformity.
- Metric Equivalence and Induction: Margin discrepancy, Euclidean distance to the uniform margin solution, and metrics induced by $\bSigma$ are shown to be tightly connected, enabling induction-based convergence proofs.
- Super-polynomial Rate: The convergence to margin uniformity is controlled via a sequence of auxiliary bounds and induction over several properties (margin, loss decay, distance to solution, and step size scaling). The squared-log decay, exp(−clog2t), is both sharp and optimal for this dynamic.
Contrasts with Classic Implicit Bias
Without BN, the implicit bias in linear (and deep homogeneous linear) networks is well understood: logistic loss GD with overparameterization selects the ℓ2 max-margin solution (i.e., SVM). This work shows that BN modifies both the geometry of the optima (from max-margin to uniform margin) and the dynamics (from logarithmically slow to rapidly super-polynomial convergence). Furthermore, solutions selected by BN correspond to KKT points of the max-margin problem, but are not generally the maximizers.
Implications and Future Directions
Theoretical
- Homogeneous Models: The result contributes substantially to the theory of implicit bias for homogeneous (scale-invariant) models, providing a precise, non-asymptotic last-iterate characterization.
- Separation from Regression: For linear models, the uniform margin solution coincides with least-squares regression; in CNNs, however, uniform margin is strictly richer and unattainable without normalization. This shows that BN fundamentally changes the inductive bias.
- KKT Non-uniqueness: The results clarify that KKT-based characterizations are not sufficient for capturing the unique bias imposed by BN.
Practical
- BatchNorm as Implicit Regularizer: The results reinforce the empirical observation that BN acts as a form of strong implicit regularization, steering models toward solutions with highly uniform (and potentially more robust) activations.
- Generalization in Patch-rich Regimes: For structured data (e.g., images), BN can select solutions which amplify persistent, weak signals and suppress strong noise, outperforming classical max-margin on generalization.
Visual Illustration
Margin distributions during training confirm the collapse to uniformity in BN-trained models (Figures 1 and 2), whereas models without BN retain significant dispersion even after extended training. In deep CNNs, neuron activation margins are significantly more uniform with BN, as measured on the CIFAR-10 dataset.
Conclusion
This paper demonstrates that batch normalization fundamentally alters the implicit bias of gradient descent in linear models and linear CNNs, driving convergence to solutions of uniform margin or patch-wise uniform margin. The convergence rate is exponentially faster than the classical max-margin trajectory and, importantly, these uniform margin solutions may yield superior generalization in structured prediction problems.
Future work should extend these precise implicit bias characterizations to multi-filter, multi-layer, and nonlinear architectures, and further explore the interactions between normalization schemes and implicit regularization in deep learning.
Reference: "The Implicit Bias of Batch Normalization in Linear Models and Two-layer Linear Convolutional Neural Networks" (2306.11680)