- The paper introduces a novel t-patch-based pipeline that segments 3D point cloud sequences to capture temporal dynamics.
- It employs a hierarchical neural network to effectively aggregate spatio-temporal features and improve action classification.
- Experimental results demonstrate significant performance gains on datasets like DFAUST and IKEA ASM, especially under occlusion.
Understanding Human Actions in 3D Point Clouds
Introduction
The paper "3DInAction: Understanding Human Actions in 3D Point Clouds" (2303.06346) presents a novel approach for action recognition utilizing 3D point cloud sequences. Traditional methods largely focus on RGB video data, which limits performance in scenarios requiring spatial awareness, such as autonomous systems or low-visibility environments. The proposed 3DinAction pipeline addresses the limitations of 3D point cloud data—lack of structure, permutation invariance, and variable point counts—by introducing temporally evolving patches, termed t-patches, and a hierarchical architecture to learn an effective spatio-temporal representation.
3DinAction Pipeline
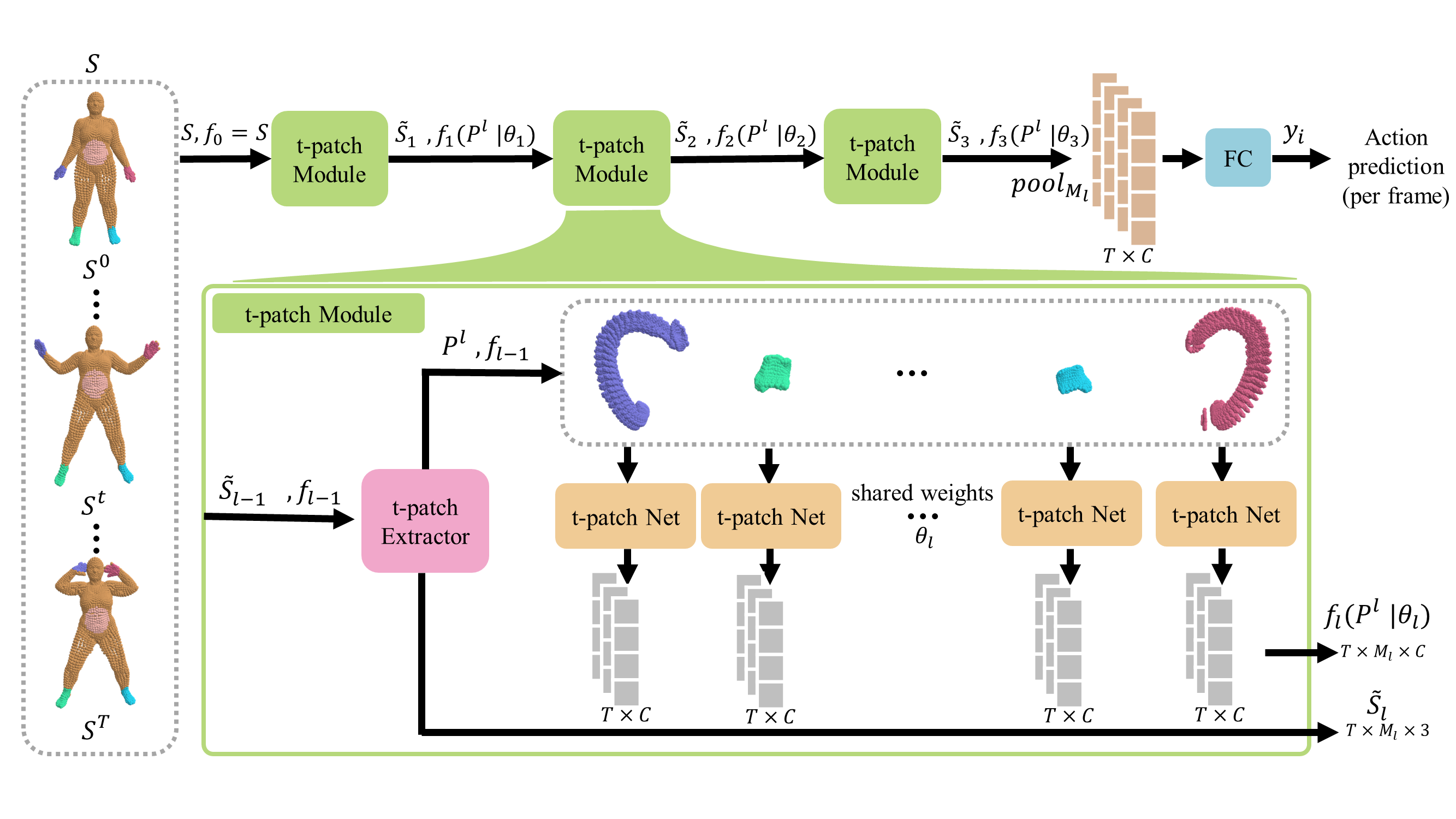
Figure 1: 3DinAction pipeline. Given a sequence of point clouds, a set of t-patches is extracted. The t-patches are fed into a neural network to output an embedding vector. This is done hierarchically until the global t-patch vectors are pooled to get a per-frame point cloud embedding which is then fed into a classifier to output an action prediction per frame.
The 3DinAction pipeline processes input 3D point cloud sequences by first segmenting them into local temporal patches called t-patches. These patches capture the dynamics of a point region over time. The t-patches are further passed through a hierarchical neural network to produce a high-dimensional representation for classification. This approach circumvents the need for temporal point correspondence and is robust to variations in point density and occlusion.
T-Patch Construction
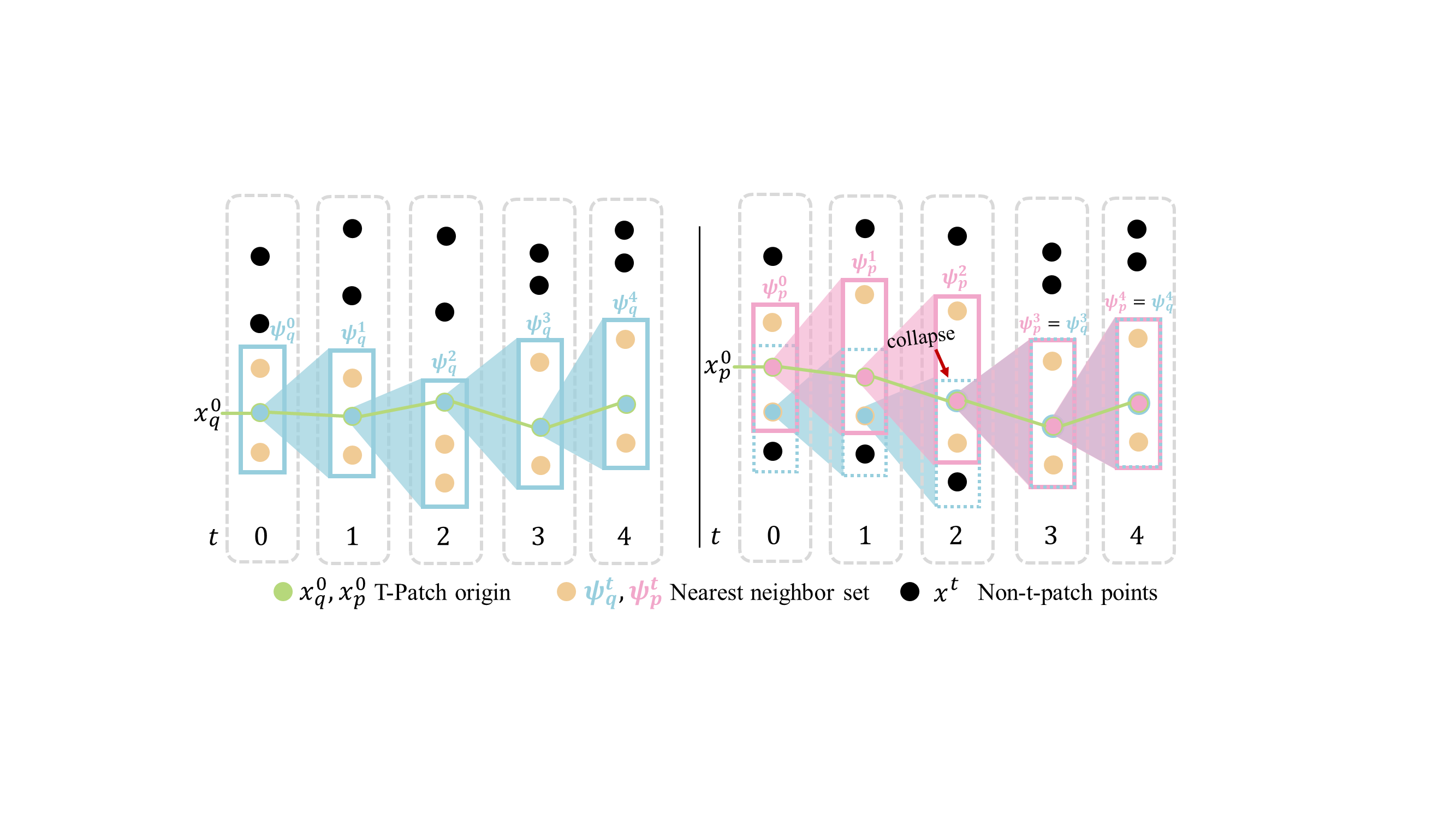
Figure 2: t-patch construction and collapse. Illustration of t-patch construction (left) and collapse (right). Starting from an origin point xq0, nearest neighbors are iteratively found in subsequent frames to form the t-patch subset.
T-patches are constructed by selecting a query point in the first frame of a sequence and finding its nearest neighbors across subsequent frames. This iterative process captures the dynamics of surface deformation. To prevent t-patch collapse, where multiple t-patches converge into the same points over time, bidirectional t-patches are utilized. This involves constructing t-patches both forward and reverse in time to maintain coverage and capture meaningful temporal dynamics.
Hierarchical Network Design
The hierarchical network design involves a series of t-patch modules that operate sequentially. Each module receives a sparser point cloud with an enhanced feature representation. The architecture comprises shared MLP layers followed by convolutional layers to aggregate features temporally. The final representation is fed through a classifier with temporal smoothing to produce per-frame action predictions. The network is trained using cross-entropy loss combined for frame-level and sequence-level predictions.
Experimental Results
Significant performance gains were demonstrated on the DFAUST and IKEA ASM datasets.









Figure 3: 3DinAction GradCAM scores. The proposed 3DinAction pipeline learns meaningful representations for prominent regions. The presented actions are jumping jacks (top row), hips (middle row), and knees (bottom row). The columns represent progressing time steps from left to right. Colormap indicates high GradCAM scores in red and low scores in blue.
3DinAction outperformed state-of-the-art models, particularly in scenarios involving occlusion and temporal collapse. An extended GradCAM approach illustrated the interpretability of learned features, highlighting effective motion regions like arms in "jumping jacks."
Architectural Trade-offs
While the 3DinAction pipeline can offer substantial gains, it necessitates careful selection of t-patch parameters like the number of neighbors and downsampling rates. This trade-off impacts computational requirements and the model's ability to generalize across different movement intensities and temporal resolutions. Optimization of t-patch extraction speed is particularly crucial due to its computational demands.
Conclusion
3DinAction proves to be a robust method for 3D point cloud action recognition, with significant implications for applications needing temporal and spatial acuity. Potential future enhancements include learning-based t-patch extraction and multi-modal integration. The research exemplifies the value in expanding beyond traditional RGB video data to more spatially rich modalities.