- The paper introduces a novel approach to generate 3D facial models from textual prompts by bridging CLIP embeddings with FLAME parameters.
- It employs a deep MLP trained on a synthetic dataset of 50,000 StyleGAN2-generated faces to accurately capture facial identity, expressions, and surface details.
- Experimental results demonstrate high-fidelity synthesis with practical applications in digital avatars and security, while also highlighting the need for bias mitigation.
Text2Face: A Technical Overview
This essay discusses the research presented in the paper "Text2Face: A Multi-Modal 3D Face Model" (2303.02688), which introduces a novel approach to generating 3D Morphable Models (3DMMs) from textual prompts. The model exploits advancements in multi-modal learning and pre-trained embedding spaces to accomplish text-driven 3D face synthesis. Detailed experiments and architectural insights reveal potential practical applications and open up future avenues in AI research.
Introduction to Methodological Approach
The paper presents a model named Text2Face, which bridges Contrastive Language-Image Pre-training (CLIP) embeddings and the FLAME 3D face model parameter space. The model functions by translating descriptive text inputs into fully parameterised 3D faces, describing corresponding identity, expressions, and surface details. Unlike existing text-to-shape approaches, this framework explicitly handles face identity in the generation process, leveraging the robustness of CLIP embeddings to accurately capture textual nuances.
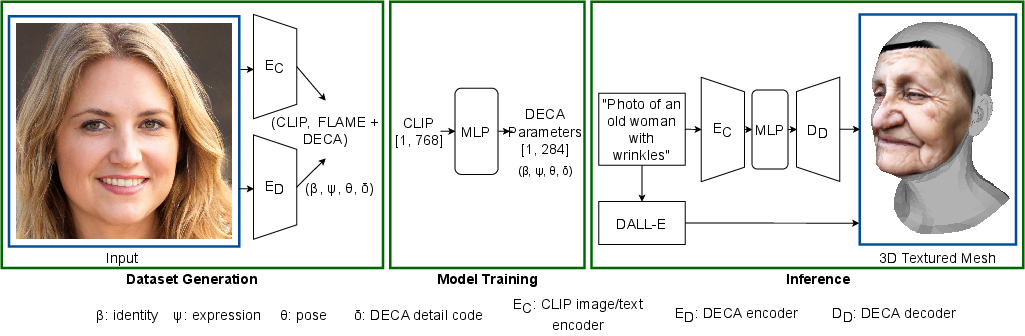
Figure 1: Dataset generation, model training, and inference for Text2Face.
Model Architecture and Training Procedure
Text2Face is implemented as a deep Multilayer Perceptron (MLP), trained on a synthetic dataset consisting of $50,000$ adult faces produced by StyleGan2. For each generated image, the model extracts CLIP embeddings and maps them along with corresponding FLAME model parameters, including identity, detailed displacement maps, and expressions. The model architecture capitalizes on the shared latent space in CLIP to facilitate interchangeable text and image prompts during inference.
To synthesize the dataset, image embeddings are extracted using a ViT-L/14-336px vision transformer, followed by parameter extraction using the DECA method for 3D face reconstruction. The training regimen follows standard optimization strategies employing the Adam optimizer.
Experimental Results and Visual Demonstrations
The paper effectively demonstrates Text2Face's capacity to produce high-fidelity 3D faces from contextual prompts through various experimental setups. For instance, the model produces convincing results for prompts like "Photo of an old woman with wrinkles" and "50 year old man looking grumpy", showcasing seamless integration of textual nuances into realistic 3D facial models as evidenced by qualitative outcomes.

Figure 2: (l): Prompt: "20 year old woman looking at the sky with surprise at UFO overhead". (r): Prompt: "50 year old man looking grumpy". Each sub-figure, from left to right: Shape generated by the text prompt, DALL-E image from the same prompt, textured mesh.
In addition to textual prompts, Text2Face showcases multi-modal inputs by fitting 3DMMs to images, sketches, and sculptures derived from an iconic subject, Robert De Niro, demonstrating robust cross-modal application. The model's depiction suggests its potential in diverse fields, such as digital avatar creation and refined photofit generation in law enforcement.

Figure 3: Robert De Niro fit to a 3DMM using Text2Face: using an original image (left), a sketch (middle), and an engraving (right).
Implications and Future Directions
The development of Text2Face holds significant implications for multi-modal synthesis in AI, encouraging hybrid approaches to 3D modeling combining textual and visual prompts. It supports applications from entertainment to security, although careful consideration must be given to biases inherited through pre-trained models like CLIP.
Future research should explore mitigation strategies for latent biases and broaden the scope of text-based synthesis to diverse demographic attributes. Integrating this model into applications with real-time constraints, such as live avatar creation and interactive virtual environments, represents promising exploration venues.
Conclusion
Text2Face marks a significant advancement in text-driven 3D modeling, offering a comprehensive framework for generating detailed morphable facial models from textual descriptions. By integrating CLIP and 3DMMs, the approach not only enhances the diversity of input data but also paves the way for further improvements in multi-modal AI applications. Future research directions should target understanding and alleviating bias implications while expanding the model's scope in both accuracy and real-world applicability.

