- The paper introduces a Markovian framework that models failure probabilities and survival rates using continuous-time processes.
- It compares single-ECU and multi-ECU configurations, highlighting trade-offs between structural redundancy and diagnostic capability using M-out-of-N logic.
- Empirical results indicate that 2oo3/2oo4 architectures effectively balance reliability and fault detection for mission-critical automated driving systems.
Reliability Analysis of Fault-Tolerant Architectures for Automated Driving Systems
Architectural Classes and Redundancy Mechanisms
The paper systematically distinguishes between two ECU architectural groups for automated driving: single-ECU (system-on-a-chip) and multi-ECU (distributed fail-safe) configurations. These architectures leverage various forms of redundancy—structural (e.g., M-out-of-N or MooN majority voting), parallel, and diversity—to achieve fault tolerance in the context of hardware faults in CPUs/MCUs and sensors.
Single-ECU configurations can implement higher degrees of structural redundancy internally (e.g., 2oo3, 3oo4 architectures) and benefit from tighter integration and potentially higher baseline reliability, as all redundant elements are collocated and can be more efficiently monitored. Multi-ECU architectures, meanwhile, capitalize on architectural diversity and independence, providing superior robustness against dependent failures (common-cause and cascading faults), at the possible cost of increased interconnection complexity and more challenging coordination.
The foundational combinatorial structure for redundancy in this domain is the MooN logic, which formalizes the conditions for system survival based on the operational status of N components: system function is assured provided that at least M out of N elements are functional. This logic is applied hierarchically to both sensors and computing units (MCUs/CPUs).
Markovian Reliability Modeling
The reliability evaluation leverages continuous-time Markov processes to model the degradation and survival probabilities of various sensor/MCU architectures (SooNS/MooNM). System state is described by the number of operational sensors (s) and MCUs (m), with transition rates governed by exponential distributions parametrized by failure rates λS and λM. The state-transition model considers only loss (no repair or restoration), and the system is considered failed as soon as it can no longer satisfy the minimum admissible redundancy required for either sensors or MCUs according to the MooN logic.
(See Figure 1)
Figure 1: Phase diagram of a Markov chain for a system with three MCUs and three sensors.
The reliability function is then derived as
R(t)=m=M∑NMs=S∑NSPm,s(t)
where Pm,s(t) is the probability of m MCUs and s sensors being operational at time t, computed via matrix exponential methods exploiting the sparsity and triangularity of the transition rate matrix.
Empirical Evaluation and Critical Results
The quantitative results explore a broad parametric sweep of SooNS/MooNM configurations, with 3 sensors and up to 4 MCUs, and practical failure rates of λS=1×10−5 h−1 for sensors and λM=1×10−4 h−1 for MCUs. Reliability curves are juxtaposed for a spectrum of architectures ranging from pure series (e.g., NooN) to pure parallel (e.g., 1ooN) and various majority redundancies.
(Figure 2)
Figure 2: Survival probability R(t) for SooNS/MooNM configurations with NS=3, NM=3, highlighting the impact of redundancy logic on system reliability.
A pivotal finding is that while 1ooN parallel systems consistently yield the highest reliability in raw terms—as they only require one element to be functional—they lack any self-diagnostic capability and thus cannot guarantee safe fail-over or support effective fault management in the absence of human supervision. In contrast, majority-redundant (e.g., 2oo3, 2oo4) systems—central to fault-tolerant design in safety-critical applications—achieve a theoretically slightly lower maximal reliability but provide indispensable self-diagnosis and error localization.
For three MCUs and sensors, 2oo3/2oo3 emerges as the minimal configuration that balances fault tolerance and diagnostic capability, although it is noted that its long-term reliability eventually underperforms a basic 1oo1/1oo1 (series) reference architecture, indicating a trade-off that must be considered in mission-duration and maintenance planning.
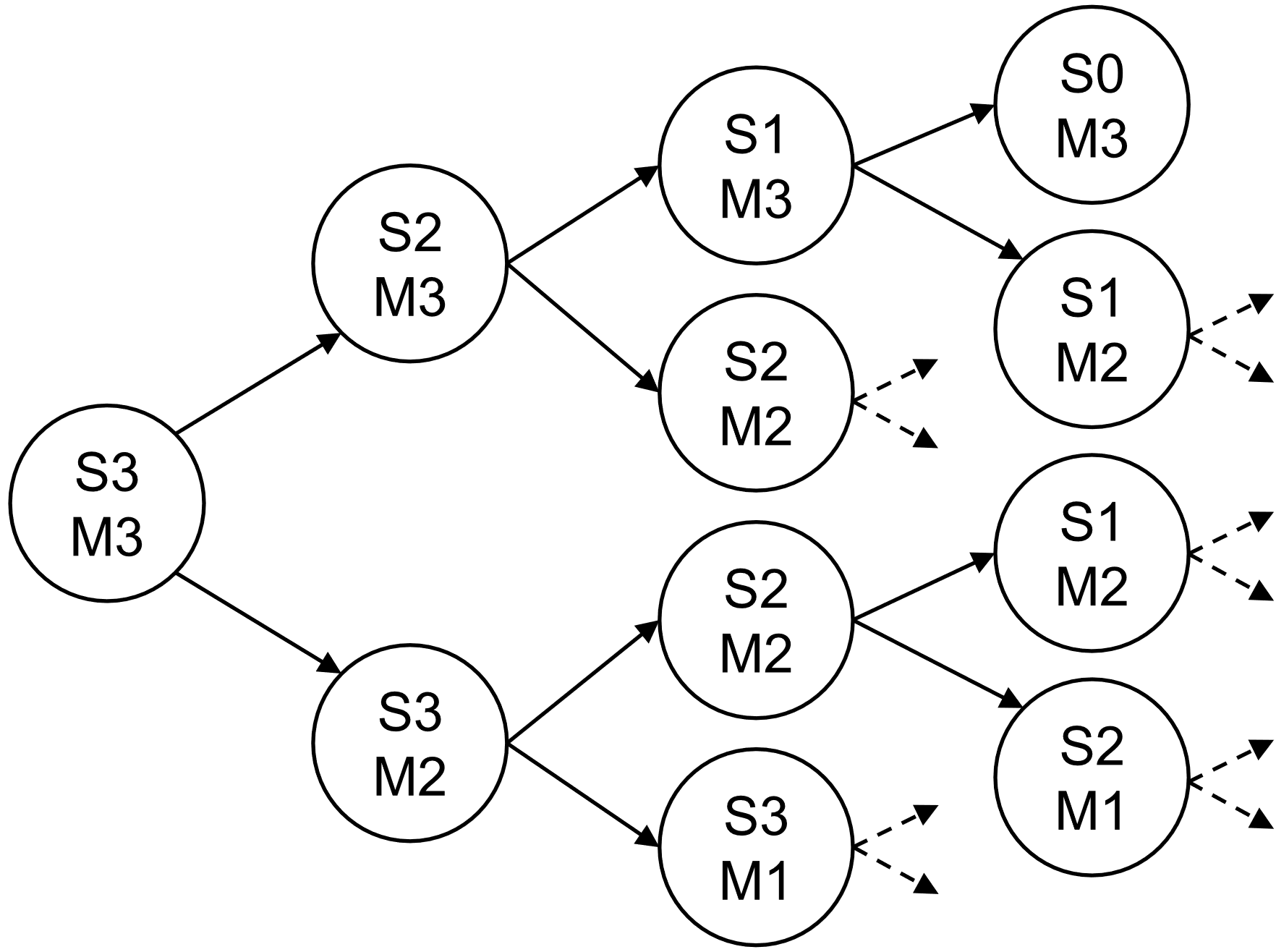
Figure 1: Survival probability R(t) for SooNS/MooNM configurations with NS=3, NM=4, demonstrating the reliability gain as MCU redundancy increases and as majority thresholds are adjusted.
When architectures are extended to four MCUs (3 sensors, 4 MCUs), 2oo3/2oo4 architectures provide a marked improvement: The crossing point with the 1oo1/1oo1 baseline is significantly delayed, suggesting that the addition of a fourth MCU (and corresponding majority logic) provides measurable gains in both absolute reliability and fault-tolerant operational range. This result is consistent with established practice in sectors such as nuclear, space, and military systems, where 2oo4 is the preferred baseline for high-integrity fail-operational scenarios.
Contrasts, Design Implications, and Recommendations
The study underscores a foundational design tension: maximum reliability (as delivered by minimal-parallel/1ooN systems) and maximum observability/self-diagnosis (as enabled by majority redundancy) are competing rather than strictly additive. The most reliable designs in terms of pure survival probability may not satisfy safety requirements under the SAE L4/L5 paradigm due to their diagnostic opacity. Thus, system designers must accept a degree of reliability penalty to realize architectures capable of internal fault detection, isolation, and recovery, eliminating the need for human fallback.
Architectural choice between single-ECU and multi-ECU, as well as sensor redundancy, must also be made in the context of cost and system complexity. The results show that within the 2oo3–2oo4 regime, increasing the number of MCUs (from 3 to 4) is more impactful for reliability than increasing sensor count (from 2 to 3), due in part to practical component failure rates and to the fact that sensor-level redundancy yields diminishing returns past a certain point.
Crucially, the analysis posits that 2oo4 architectures, despite their current under-utilization in automotive literature, should be prioritized for next-generation autonomous driving systems. This stance is partly contradictory to the prevailing industry focus on 2oo2/2oo3 architectures and demands new cost-benefit analyses in terms of both component overhead and safety gains.
Theoretical and Practical Implications—Pathways for Future Research
The reliability modeling framework presented enables direct, quantitative comparison of complex architectures, including parametric stress-testing (via λ selection) and evaluation of survival probabilities for arbitrary mission durations. The analysis highlights the necessity of joint optimization over architecture, failure rates (which can be controlled by targeted hardware selection and qualification), and redundancy thresholds.
Going forward, several lines of research are explicitly warranted:
- Diagnosis-augmented parallel systems: There is potential, via auxiliary diagnostic hardware/software, to endow pure parallel (1ooN) systems with sufficient self-checking to narrow the reliability-diagnosis gap.
- Inclusion of repair/recovery rates: The current Markov model is strictly degrading; future extensions to include repair/standby modes (with associated Kolmogorov equations) will enable joint analysis of availability/fail-operational lifetime in dynamic operational contexts.
- System-level importance and risk analysis: Extension of the modeling to address minimal cut-sets, component importance scaling, and risk prioritization is necessary for cost-constrained design under ISO 26262 and similar standards.
- Resilience to dependent failures: Robustness to common-cause failures and cascading events, especially in multi-ECU systems, should inform sensor/ECU allocation and physical separation.
- Architectural heterogeneity and diversity: Engineering diversity (e.g., different sensor/MCU vendors, disparate software stacks) improves resilience in ways not captured by simple redundancy modeling, and should be formalized.
Conclusion
This paper delivers a rigorous Markovian framework for evaluating the time-dependent reliability of sensor/MCU architectures in automated driving systems, revealing the central trade-offs between structural redundancy, parallelism, and self-diagnosis. The numerical results support the adoption of 2oo4 architectures for mission-critical fail-operational requirements, in contrast to the prevalent preference for 2oo3. The modeling approach and empirical insights provide a robust foundation for future system design, optimization, and standardization efforts in automotive autonomy.
