- The paper demonstrates that using pre-trained Vision Transformers reduces data and computational requirements while maintaining competitive accuracy compared to CNNs.
- Methodology leverages ViTs as feature extractors paired with shallow classifiers like SVM and Random Forest to effectively assess apple defects and banana ripeness.
- The findings suggest that decentralized fruit grading systems become more accessible for resource-limited operators, paving the way for integration with additional sensor data.
Facilitated Machine Learning for Image-Based Fruit Quality Assessment
Introduction
The paper "Facilitated Machine Learning for Image-Based Fruit Quality Assessment" (2207.04523) presents an innovative approach to fruit quality assessment utilizing machine learning models based on pre-trained Vision Transformers (ViTs). This method addresses challenges in deploying image-based sorting and grading systems in regions with decentralized food supply chains by eliminating the need for extensive retraining of deep neural networks and requiring fewer data samples compared to traditional CNN-based methods.
Background and Methodology
The research focuses on simplifying machine learning procedures for automated fruit sorting and grading, primarily targeting apple defect detection and banana ripeness estimation. In contrast to convolutional neural networks (CNNs), which necessitate large labeled datasets and considerable computational resources, ViTs offer an efficient alternative. The methodology leverages pre-trained Vision Transformers that are not retrained on domain-specific data, thereby reducing data and computational demands.
The authors assess two fruit-related datasets:
- Banana ripeness using images classified into four ordinal categories.
- Apple defects using binary classification to identify worm damage.
The data processing involved resizing images to fit the pre-trained model's resolution and using Vision Transformers as feature extractors. The generated embeddings from ViTs are inputted into shallow machine learning classifiers such as SVM, Random Forest, and Logistic Regression for the final assessment task.
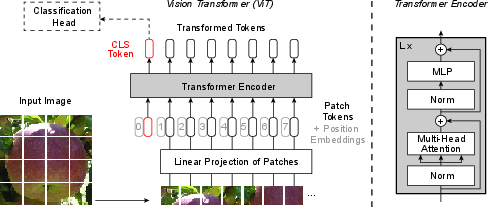
Figure 1: Model overview of a vision transformer. An input image is split into patches and embedded with positional information ("patch tokens"). An extra learnable cls-token is added. All tokens are transformed into a new sequence by a transformer encoder.
Experimental Results
The experiments conducted show that classifiers using the embeddings extracted from Vision Transformers can achieve competitive accuracy measures with significantly fewer training samples compared to CNNs. For instance, classification of banana ripeness reached accuracy levels comparable to traditional CNN methods, despite being trained on ambiguous labels and a smaller dataset (Figure 2).
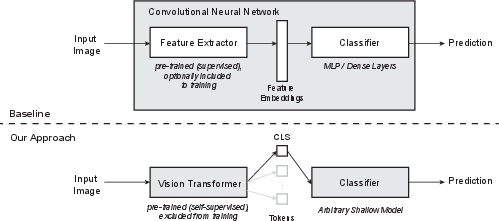
Figure 3: High-level comparison between the standard approach for machine learning--based image classification and the method proposed in this work.
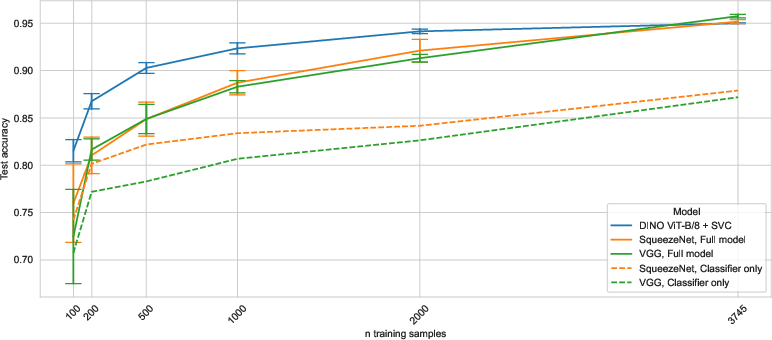
Figure 2: Test accuracies on the CASC~IFW dataset for different numbers of available training samples. Error bars represent the standard deviation of experimental results w.r.t. random initialization.
The paper's results illustrate that ViTs can efficiently compete with CNNs, especially in environments where high-quality labeled data is sparse. The use of attention mechanisms in ViTs allows for improved feature extraction, which contributes to the lower data requirements.
Implications and Future Directions
The findings of this paper imply substantial practical benefits for stakeholders in decentralized regions, potentially enabling the implementation of automated fruit grading despite limitations in data and hardware. This approach democratizes access to efficient machine learning capabilities, allowing smaller operators to participate in advanced technological solutions.
Looking forward, fine-tuning ViTs for complex tasks beyond classification, such as fruit defect segmentation and localization, could enhance this approach's applicability. Additionally, integrating these insights with complementary data sources (sensor data or metadata from supply chains) could improve predictions for complex assessments.
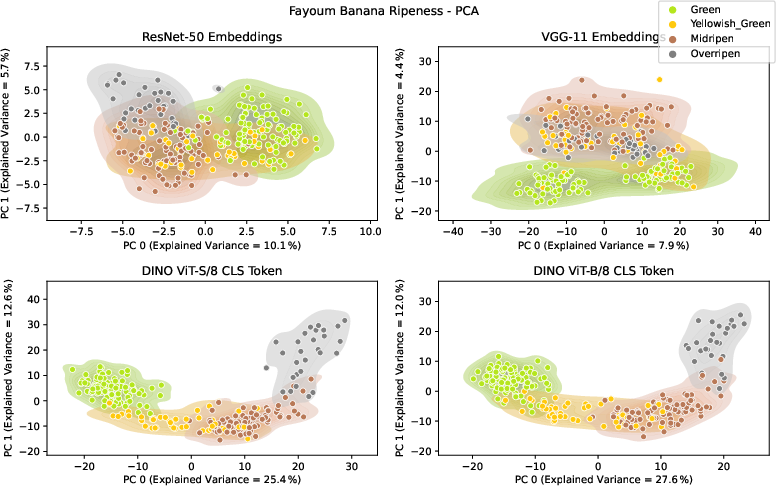
Figure 4: Latent representation of the Fayoum banana ripeness dataset in two dimensions (reduced by PCA).
Conclusion
The paper presents a significant advancement in the application of machine learning to agricultural sorting and grading, offering an efficient approach that overcomes common barriers related to data and hardware limitations. With further validation and application to complex tasks, this approach could become pivotal in transforming fruit quality assessments in decentralised supply chain environments.