CholecTriplet2021: A benchmark challenge for surgical action triplet recognition
Abstract: Context-aware decision support in the operating room can foster surgical safety and efficiency by leveraging real-time feedback from surgical workflow analysis. Most existing works recognize surgical activities at a coarse-grained level, such as phases, steps or events, leaving out fine-grained interaction details about the surgical activity; yet those are needed for more helpful AI assistance in the operating room. Recognizing surgical actions as triplets of <instrument, verb, target> combination delivers comprehensive details about the activities taking place in surgical videos. This paper presents CholecTriplet2021: an endoscopic vision challenge organized at MICCAI 2021 for the recognition of surgical action triplets in laparoscopic videos. The challenge granted private access to the large-scale CholecT50 dataset, which is annotated with action triplet information. In this paper, we present the challenge setup and assessment of the state-of-the-art deep learning methods proposed by the participants during the challenge. A total of 4 baseline methods from the challenge organizers and 19 new deep learning algorithms by competing teams are presented to recognize surgical action triplets directly from surgical videos, achieving mean average precision (mAP) ranging from 4.2% to 38.1%. This study also analyzes the significance of the results obtained by the presented approaches, performs a thorough methodological comparison between them, in-depth result analysis, and proposes a novel ensemble method for enhanced recognition. Our analysis shows that surgical workflow analysis is not yet solved, and also highlights interesting directions for future research on fine-grained surgical activity recognition which is of utmost importance for the development of AI in surgery.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
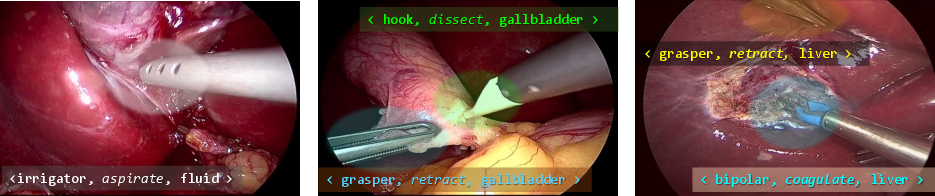
Surgeons often do operations using long tools and a camera inside the body (this is called laparoscopic surgery). The paper introduces a big science challenge called CholecTriplet2021. The goal: teach computers to watch these surgery videos and name exactly what is happening, in detail, at each moment. They do this by recognizing three things together, called a “triplet”:
- the instrument being used (like a grasper or scissors),
- the verb (the action, like cut or grasp),
- the target (the body part, like the gallbladder).
So, every moment in the video should be described like “grasper–grasp–gallbladder.” This detailed understanding could help create smart tools that assist surgeons safely in real time.
The main questions the paper asks
- Can AI recognize detailed surgical actions as triplets {instrument, verb, target} from real surgery videos?
- Which kinds of computer vision methods work best for this?
- How well do different teams’ ideas perform on the same data?
- What are the hardest parts of this problem, and where should research go next?
How the researchers approached it
Think of this like a science fair where everyone solves the same hard problem and is judged fairly.
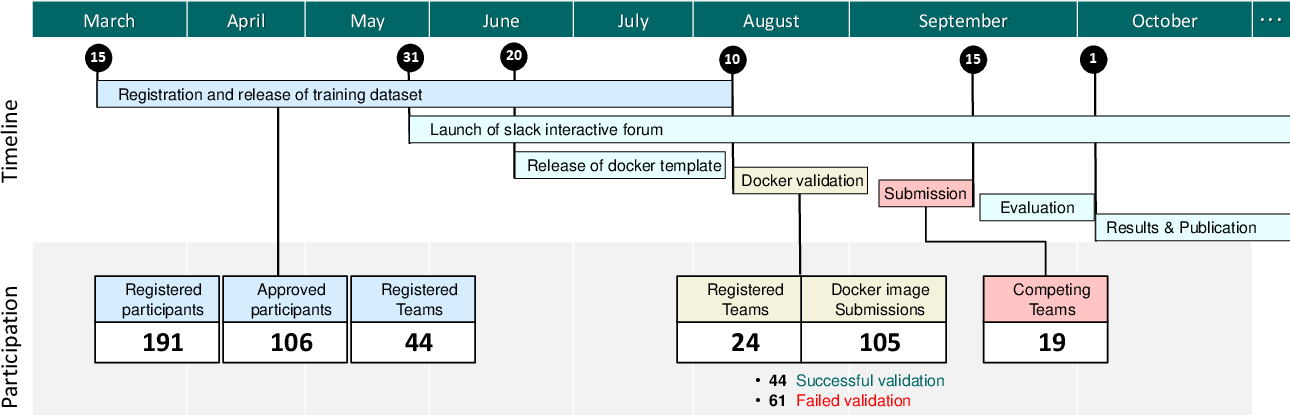
- Data: They used a large dataset called CholecT50 with 50 videos of gallbladder removal surgery (laparoscopic cholecystectomy). They sampled the videos at 1 frame per second, ending up with about 100,900 images and 161,000 labeled triplet examples. There are:
- 6 instruments (e.g., grasper, scissors),
- 10 verbs (e.g., grasp, cut, clip),
- 15 targets (e.g., gallbladder, liver),
- which combine into 100 possible triplet classes.
- Fair testing: 45 videos were given to teams to train their models. The remaining 5 (hidden) videos were used to test everyone’s methods fairly.
- The challenge: 19 teams from around the world submitted 19 new AI methods; organizers also provided 4 strong “baseline” methods to compare against.
What the AI methods did (in everyday language):
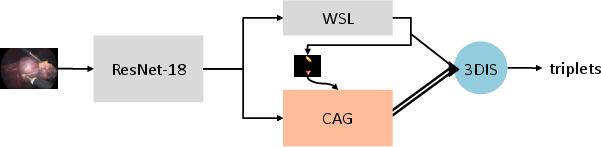
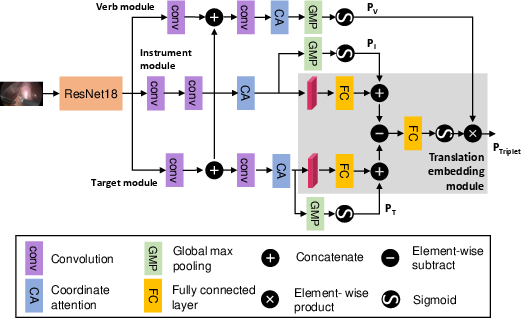
- Multi-task learning: Like learning several related skills at once (spotting the tool, the action, and the body part) so the skills help each other.
- Temporal modeling: Not just looking at one picture, but also remembering what happened in the few seconds before (like how you understand a movie scene).
- Attention: A “spotlight” that helps the AI focus on the important regions (for example, around the tool tip) when deciding the action and target.
- Ensembles: Combining the opinions of several models, like a team vote, to get better results.
How they measured success:
- They used a score called mean average precision (mAP). You can think of mAP as an overall “how accurately did you pick the right triplets?” score across all classes. Higher is better.
What they found and why it matters
- Performance range: The submitted methods’ mAP scores ranged from about 4.2% to 38.1% for recognizing the full triplets. That tells us this task is very hard, and even the best models still make many mistakes.
- What helped:
- Using information over time (temporal models like LSTMs or video networks) generally improved recognition.
- Using instrument information to guide where to look helped the model guess the correct action (verb) and body part (target).
- Attention mechanisms (smart focus/spotlights) and multi-task learning (learning tool, action, target together) were useful.
- Combining multiple models (an ensemble) gave a new, better baseline, improving over the best single method by about +4.3 percentage points in average precision.
- What’s hard:
- Multiple things can happen in the same frame (more than one triplet at once).
- Some triplets are rare (few examples to learn from).
- The visual clues can be very subtle (tiny tooltips, similar-looking tissues).
Why this research matters for the future
- Safer, smarter surgery: If computers can reliably understand “who did what to which body part” in real time, they can:
- Warn surgeons about risky actions,
- Remind them of next steps,
- Help train new surgeons with detailed feedback,
- Keep better records of what happened during an operation.
- A roadmap for progress: This challenge and its shared dataset give researchers a common testbed. The results show that:
- Detailed surgical understanding is not solved yet,
- Using time, attention, and multi-task learning is promising,
- More data, better handling of rare actions, and smarter ways to link instrument–action–target will be important next steps.
In short, this paper set up a fair competition, compared many cutting-edge ideas, and showed that while computers can start to understand surgery at a detailed level, there’s still a long way to go. The lessons learned point the way to better AI assistants in the operating room.
Collections
Sign up for free to add this paper to one or more collections.