- The paper introduces a Bayesian nonparametric approach integrating stochastic blockmodels with degree correction and a novel SICS prior for robust community detection.
- It employs a Dependent Dirichlet Process to jointly infer related graphs, effectively propagating uncertainty across multiple datasets.
- A Bayes factor method based on the Savage-Dickey ratio facilitates rigorous hypothesis testing for the presence of latent graph substructures.
Motivation and Foundations
The paper "Bayesian Learning of Graph Substructures" (2203.11664) addresses the inference of large-scale structure in the latent graphs of multivariate data, moving beyond an exclusive focus on individual edge recovery typically prevalent in graphical model literature. The underlying premise is that community structures, blocks, or cliques are fundamental in many real-world applications such as genomics, finance, and social network analysis and that ignoring such macroscopic organization can result in loss of interpretability, misspecification, and propagation of uncertainty.
To integrate structure recovery, the authors systematically incorporate advances from Bayesian nonparametrics and random graph theory into probabilistic graphical models, with an emphasis on flexible prior specification for induced block structures. This allows propagation of uncertainty from graph estimation to higher-order dependencies and enables hypotheses on global substructure, such as community or modular organization, to be tested within the generative framework.
Methodological Framework
Degree-Corrected Stochastic Blockmodels via Nonparametric Priors
The central innovation is the use of Bayesian nonparametric stochastic blockmodels, particularly the Dirichlet Process (DP) prior, as a flexible mechanism for defining block structure in a graph. Structural assignments for each node emerge from this random partition, and block-specific interaction strength is parameterized through latent variables (Figure 1). Degree correction is effected via node-level popularity parameters θi, also represented with a DP for regularization and to enhance identifiability.

Figure 2: Karate club network: posterior similarity matrices for the simulation studies, indicating node co-clustering probabilities and relation to true community structure.
Blockwise edge probabilities are modeled via a probit link, where intra-block connections have parameter βij. The DP prior determines both the number of blocks and their memberships in a data-driven, uncertainty-propagating manner. This approach contrasts with conventional models that assume fixed block counts or rely on two-stage graph/community estimation, as uncertainty is coherently propagated through the posterior.
For applications demanding stronger intracommunity structure (e.g., biological interaction networks), the SICS prior enforces that blocks are cliques; i.e., all within-block connections are deterministic. Inter-block edges are present with a uniform probability parameterized by ρ. Block partitions utilize a Chinese Restaurant Process (CRP) for flexibility, with the clique assumption constraining the graph space and offering computational advantages when large within-clique dependencies are expected.
Extension to Multiple Graphs
Recognizing the recurrent scenario of heterogeneous data (e.g., multiple experimental conditions), the framework is extended to jointly infer collections of related but distinct graphs, with shared and group-specific structure. A novel Dependent Dirichlet Process (DDP) prior is formulated such that each "baseline" node partition is allowed to be inherited or independently redrawn in each experimental group, modulated by a linkage parameter γ. This model explicitly biases node i in group x to tend towards the partitioning of node i in the baseline group, increasing cross-group interpretability while allowing for deviations.
Hypothesis Testing for Graph Substructures
To explicitly test for the presence of latent large-scale substructure, the paper introduces a Bayes factor approach based on the Savage-Dickey ratio, facilitating comparison between a "structured" model and the simplest configuration (no community structure). Critically, the computation leverages MCMC output from the full model, circumventing extraneous MCMC runs required by prior methods and enabling efficient evaluation even when closed-form marginal likelihoods are unavailable. This yields a strong model selection tool for assessing the presence and strength of block structure.
Empirical Evaluation
Simulation studies include the canonical Zachary Karate Club network and synthetic block models, highlighting the impact of sample size and demonstrating that uncertainty in graph estimation nontrivially affects community detection performance. The propagation of uncertainty is evident when comparing block recovery as sample size decreases: the estimated Bayes factor for block structure shifts rapidly from strong support of modularity to agnosticism as n reduces, aligned with theoretical expectations.
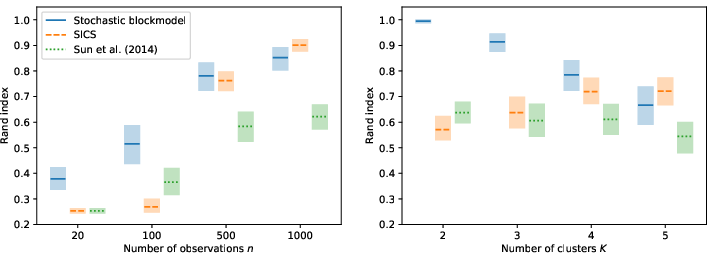
Figure 3: Block structure recovery: the Rand index as a function of sample size and number of clusters, validating the block recovery accuracy and limitations under finite data.
Applications on real data include:
- Finance: Posterior similarity matrices and median probability graphs reveal interpretable clusters of mutual funds, consistent with known investment categories. SICS produces many small blocks due to the clique constraint, whereas the stochastic blockmodel aligns more naturally with economic taxonomy.
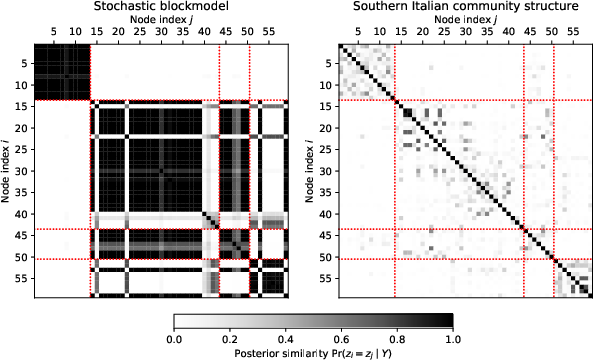
Figure 4: Mutual fund data: posterior similarity matrices reveal subgroup structure consistent with fund sector labels.
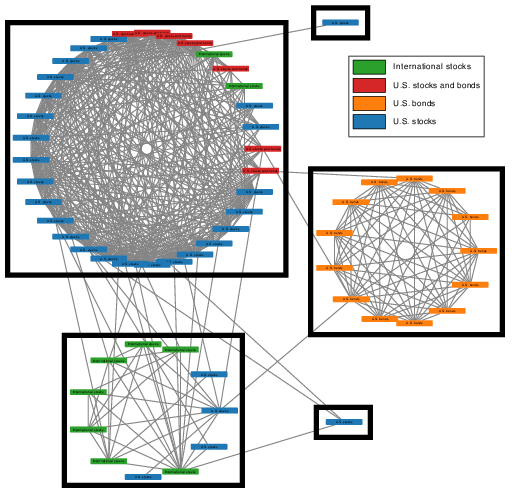
Figure 5: Mutual fund data: median probability graph from the stochastic blockmodel highlights block formation and their sectoral correspondence.
- Genomics: Analysis of gene expression in breast and ovarian cancer identifies modules with high posterior probability, showing correspondences and deviations from external annotations (e.g., GO enrichment). The multi-graph extension successfully distinguishes both shared and tissue-specific module allocation.

Figure 6: Gene expression data: posterior similarity matrices visualize both within-cancer and cross-cancer co-clustering, elucidating patterns of shared and differential gene module organization.
Theoretical and Practical Implications
This integration of random graph models and Bayesian nonparametrics directly addresses several deficiencies in standard graphical modeling: lack of uncertainty propagation to macrostructure inference, rigidity in block specification, and limited adaptability to multiple related networks.
The main implications are:
- Practical: The models provide a principled mechanism for robust community detection in graphs learned from data, with explicit uncertainty quantification. They allow practitioners to borrow information across related datasets and test for modular organization natively.
- Theoretical: The use of DDPs for node clustering across networks is novel and can be extended to introduce more sophisticated dependency structures or non-DP priors. The partition-level hypothesis testing framework has broad applicability for model selection in latent partition models.
Future Directions
Several natural extensions follow. The models may be adapted for discrete or mixed-type graphical models beyond GGMs, incorporate further hierarchical or spatial prior structure, or be linked to dynamic and temporal graph inference. The development of alternative partition priors (Gibbs-type, repulsive mixtures) within this framework and investigation of asymptotic properties as both n and p grow are other promising avenues.
Conclusion
In summary, "Bayesian Learning of Graph Substructures" presents a coherent, technically sound methodology for inferring, testing, and interpreting latent block structures in undirected graphical models. By leveraging Bayesian nonparametrics and formulating new priors and hypothesis testing approaches, the framework advances both the statistical rigor and practical utility of structure learning in multivariate graphical models (2203.11664).