- The paper introduces instance-level difficulty scores to enhance evaluation efficiency, achieving a Kendall correlation of up to 0.93 using only 5% of instances.
- It improves dataset quality by identifying and correcting trivial or erroneous instances, leading to more robust model training and evaluation.
- The study proposes a weighted accuracy metric that better reflects out-of-domain performance and aids in informed model selection.
ILDAE: Instance-Level Difficulty Analysis of Evaluation Data
Introduction
The paper "ILDAE: Instance-Level Difficulty Analysis of Evaluation Data" presents a novel approach for analyzing evaluation data through the lens of instance-level difficulty. The authors highlight the importance of understanding the difficulty of individual instances, leveraging this understanding to improve the evaluation of NLP models across various datasets. This approach is demonstrated through five significant applications, emphasizing efficiency, data quality enhancement, model selection based on task characteristics, dataset insights for future data creation, and reliable out-of-domain (OOD) performance estimation.
Efficient Evaluations
One of the primary applications discussed in the paper is conducting efficient evaluations. The paper proposes a method that reduces the computational cost of model evaluations by evaluating models on a carefully selected subset of instances rather than the entire dataset. By utilizing instance-level difficulty scores, the method selects a majority of instances with moderate difficulty and a few with extreme scores to maintain evaluation efficiency while preserving accuracy.
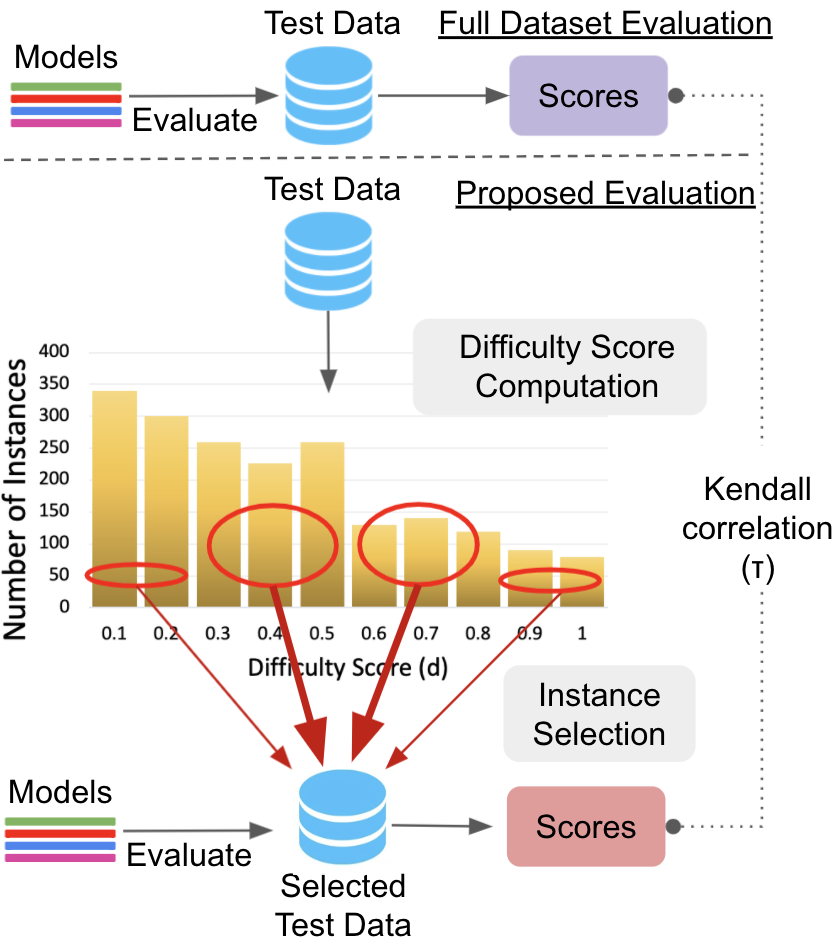
Figure 1: Comparing standard evaluation approach with the proposed efficient approach using difficulty scores.
The results demonstrate that using just 5% of the instances can achieve a Kendall correlation of up to 0.93 with full dataset evaluations, thus significantly reducing computational expenses without compromising evaluation reliability.
Improving Evaluation Datasets
The paper also addresses the issue of dataset quality by identifying and modifying erroneous and trivial instances using difficulty scores. Through a human-and-model-in-the-loop technique, trivial instances are made adversarial and erroneous ones are corrected, enhancing the dataset quality. This process is illustrated by experiments on the SNLI dataset, where modifying and repairing instances result in marked changes in model performance.
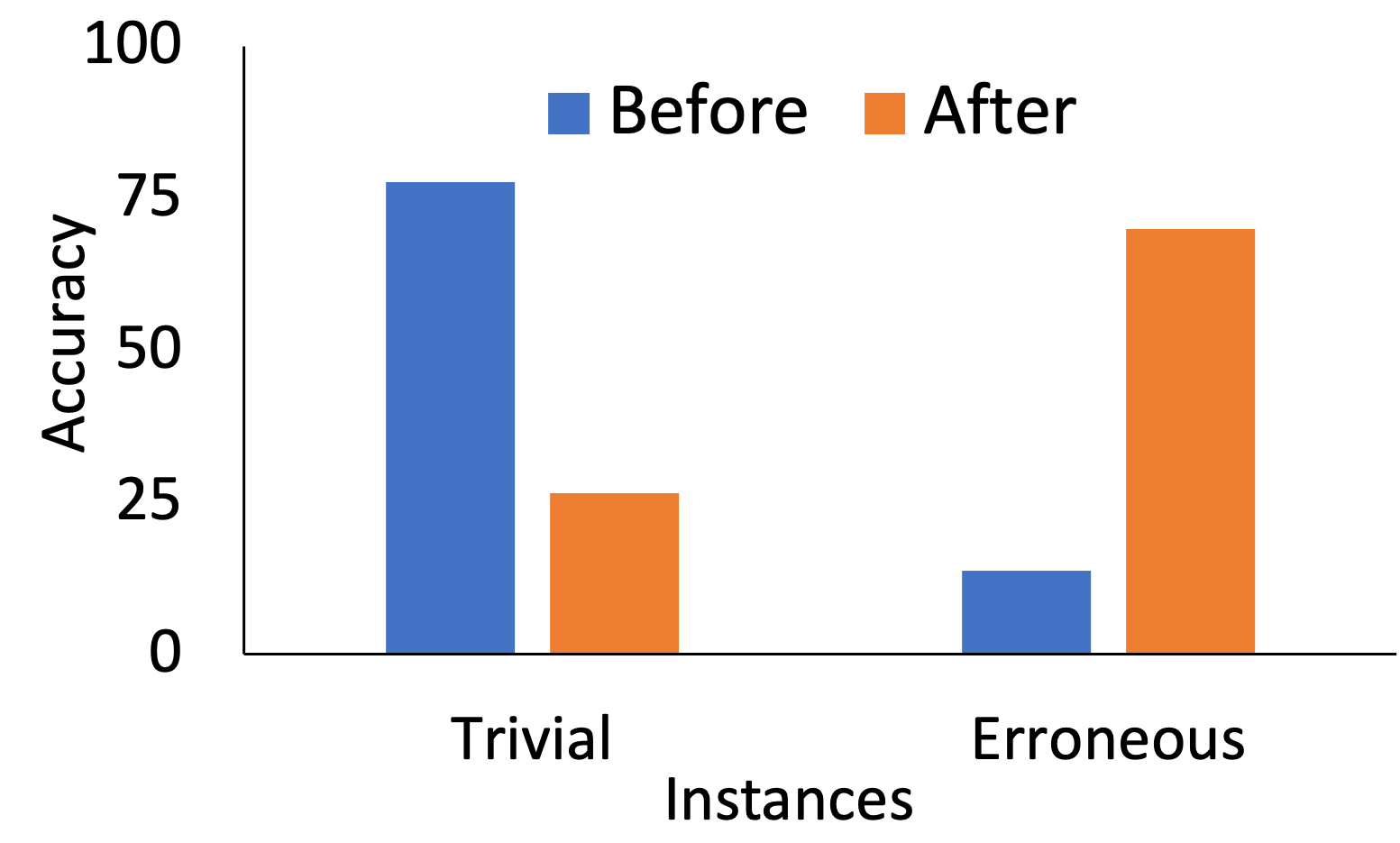
Figure 2: Comparing accuracy before and after modifying SNLI instances.
Such improved datasets are crucial for researchers pursuing accurate evaluations and robust model training.
Model and Dataset Analysis
ILDAE provides insights into model capabilities and dataset characteristics. By segregating instances based on difficulty scores, it enables an analysis of model performance across different difficulty regions. This highlights that models excel in different areas, aiding in informed model selection depending on application requirements. Furthermore, difficulty analysis across dataset labels reveals potential areas for improvement in future dataset creation.
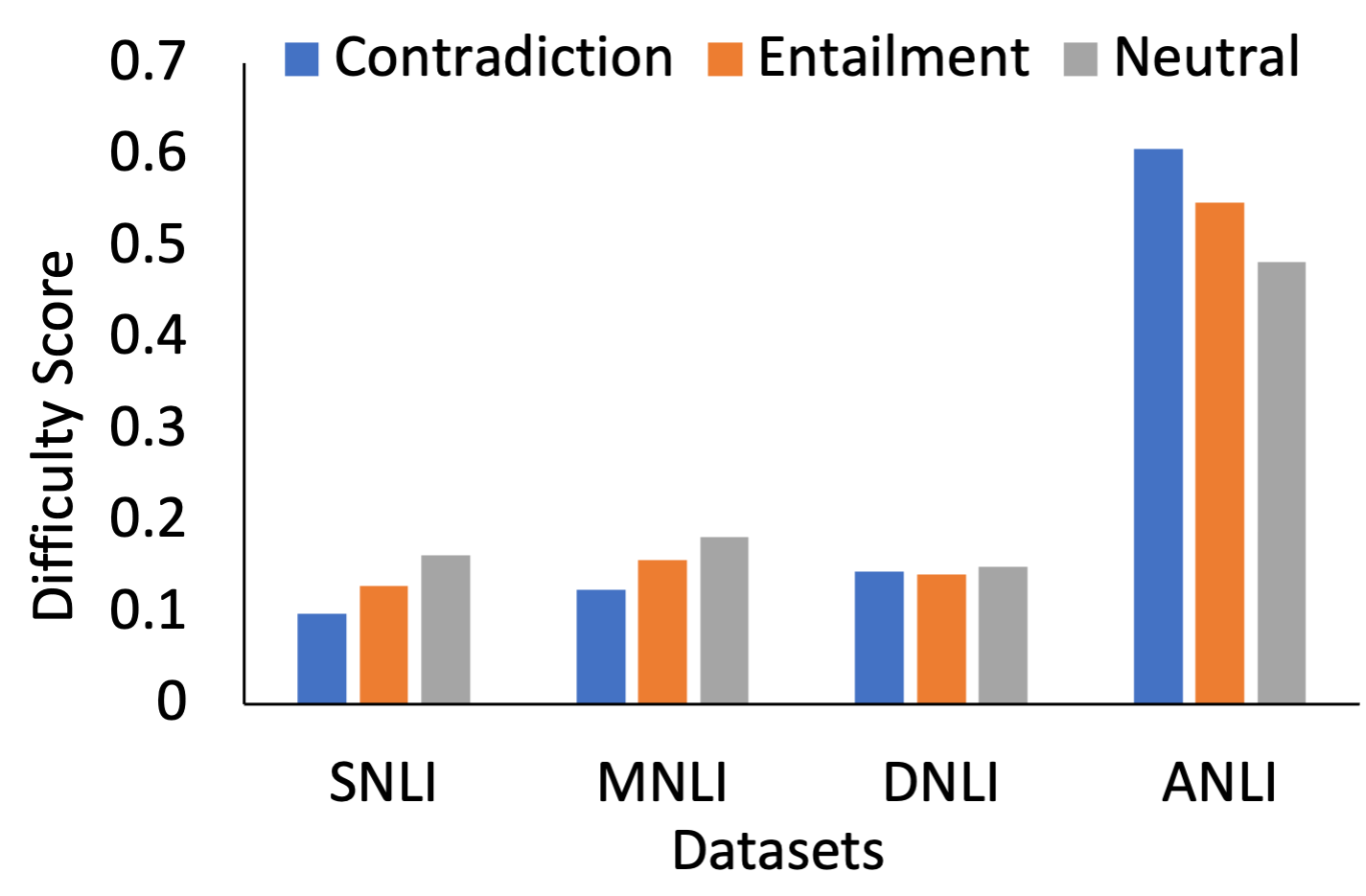
Figure 3: Comparing average difficulty of NLI datasets for each label.
Correlation with Out-of-Domain Performance
The study introduces a novel calculation of weighted accuracy, which correlates better with OOD performance than traditional accuracy metrics. This weighted accuracy uses difficulty scores to provide a more reliable performance estimate, as seen in the analysis on various OOD datasets.
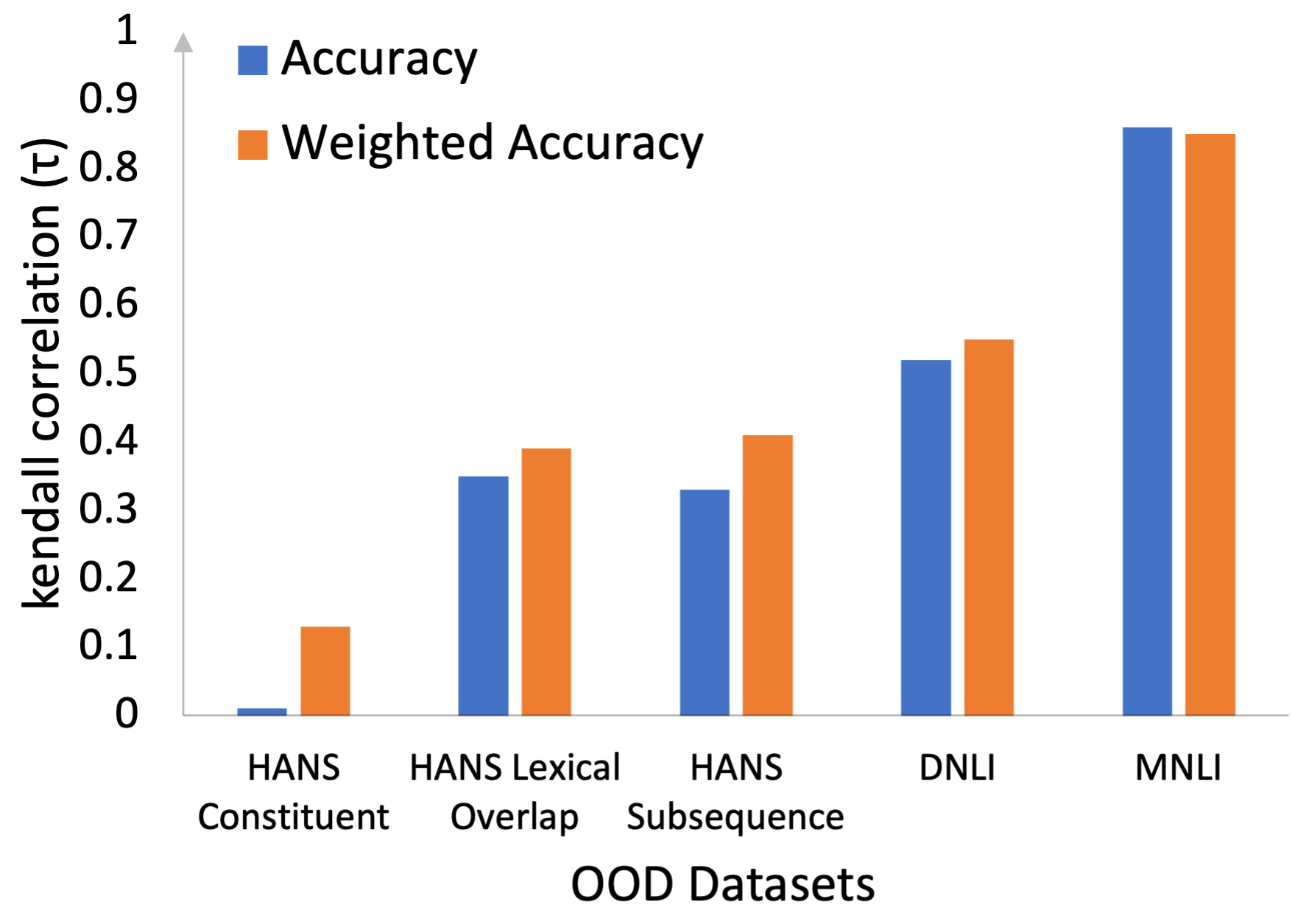
Figure 4: Comparing Kendall correlation of standard unweighted accuracy and weighted accuracy with OOD accuracy.
Conclusion
The research on ILDAE demonstrates the profound impact of instance-level difficulty analysis in NLP evaluations. The applications not only improve efficiency and dataset quality but also provide deeper insights into model and dataset characteristics. By making difficulty scores publicly available, the authors hope to foster further research and development in this promising area of NLP evaluation. The framework set by this study paves the way for more nuanced and efficient model evaluations that are critical for advancing robust AI applications.