- The paper introduces a probabilistic framework using latent variables to efficiently select neuron subsets for intrinsic probing.
- It employs variational inference with Monte Carlo sampling to marginalize over subset selections, outperforming traditional baseline probes.
- Empirical results on m-BERT show improved normalized mutual information and cross-lingual transfer in capturing morphosyntactic properties.
Latent-Variable Intrinsic Probing: A Probabilistic Approach to Neuron-Level Analysis
Introduction
The analysis of pre-trained contextualized representations has evolved into a major subfield in NLP interpretability, with probing techniques serving as the principal analytical tool for uncovering the linguistic structure encoded in neural networks. The work "A Latent-Variable Model for Intrinsic Probing" (2201.08214) proposes a new probabilistic framework for intrinsic probing of vector representations—specifically a latent-variable approach that facilitates scalable and principled neuron (dimension) subset selection. This framework addresses fundamental limitations in the tractability and expressiveness of earlier methods for locating where in a representation specific linguistic properties are encoded.
Limitations of Conventional Intrinsic Probing
Intrinsic probing seeks not only to detect the presence of linguistic attributes (e.g., morphosyntactic features) in a given representation, but to precisely localize where these properties are manifested—down to the level of individual neurons. Previous techniques, such as exhaustive training of probes on all possible neuron subsets or greedy selection of dimensions, are computationally infeasible in high-dimensional contexts (e.g., 2768 possible subsets for BERT), and rely on restrictive assumptions or heuristics for estimating mutual information. These constraints have hindered the systematic, quantitative characterization of internal representation structure.
The Latent-Variable Model: Probabilistic Subset Marginalization
The central contribution of the paper is a latent-variable formulation for intrinsic probing, replacing rigid or greedy subset selection with parameterized distributions over neuron subsets. Instead of hard-selecting a subset C, the model assigns a prior p(C) over all possible subsets, using conditional Poisson and Poisson sampling designs to flexibly control the expected subset size and selection pattern. The likelihood of a linguistic attribute given an embedding marginalizes over all possible subset configurations:
p(π∣h)=C⊆D∑p(π∣C,h)p(C)
Variational inference, specifically stochastic variational inference with Monte Carlo sampling and, when appropriate, the REINFORCE estimator for gradients, is leveraged to handle the intractable summation over subsets during training. This enables efficient joint optimization of both model parameters (e.g., probe weights) and variational parameters (e.g., subset distribution parameters), yielding a probe whose parameters generalize across all neuron subset selections.
Experimental Setup
The latent-variable probe is validated in a multilingual, morphosyntactic probing scenario using m-BERT representations over 29 property-language pairs spanning six languages (Arabic, English, Finnish, Polish, Portuguese, Russian). Empirical evaluation targets the normalized mutual information (NMI) between neuron subsets and morphosyntactic labels, with comparisons against several baselines: (i) linear and generative Gaussian probes, and (ii) an upper bound configuration in which a probe is retrained for every subset—representing an impractical but tight lower bound on estimation error.
Strong Numerical Evidence and Comparative Analysis
Conditional Poisson and Poisson probes outperform both linear and Gaussian baselines in terms of NMI across most subset size regimes. The most striking improvements are observable at moderate to large subset sizes (≥ 50 dimensions), where the generative Gaussian approach not only underperforms but can yield unstable or even negative MI estimates. The difference in performance compared to the upper bound configuration is small, supporting the efficiency and universality of parameter sharing across subsets. Notably, Gaussian probes sometimes show higher raw classification accuracy but do so at the expense of NMI consistency and calibration.
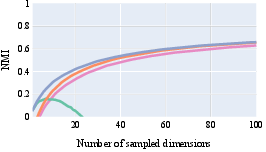
Figure 2: Comparison of normalized mutual information (NMI) for different intrinsic probes over varying dimension subset sizes and attributes.
The model also supports the deeper architectural variants, confirming that the latent-variable approach is not restricted to linear models, though observed performance gains for nonlinear classifiers over linear ones in this context are modest.
Structural Analyses: Distribution and Overlap
Analysis of information dispersion reveals that morphosyntactic properties are unevenly distributed across neuron dimensions, varying by attribute and language. Attributes such as 'gender' and 'number' in typologically distinct languages require disparate numbers of dimensions for optimal information capture, with richer systems (e.g., Russian, Polish) dispersing their encoding more broadly than simpler systems (e.g., English, Portuguese).
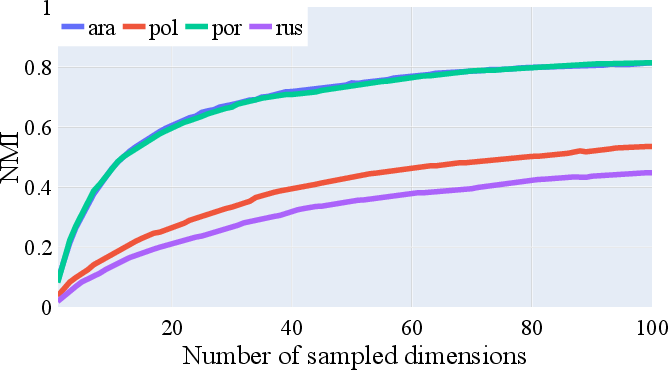
Figure 1: Average NMI for gender encoding across languages, showing information is more diffused in languages with more gender classes.
Cross-lingual analysis demonstrates significant cross-language overlap among the most informative dimensions for key morphosyntactic properties, especially between closely related languages (e.g., Slavic and Romance pairs). This pattern is robust after family-wise multiple comparison correction and suggests strong parameter sharing in multilingual contextual encoders.

Figure 3: Statistically significant overlap between top-30 number dimensions in m-BERT representations across different languages.
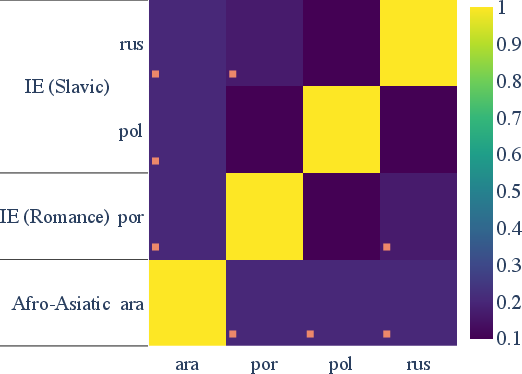
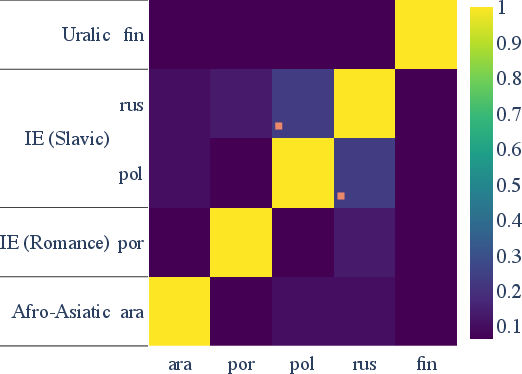
Figure 4: Overlap in the top-30 most informative neurons for gender (left) and case (right) across languages, flagged with statistical significance.
Theoretical and Practical Implications
The latent-variable framework yields a tractable and theoretically principled method for intrinsic probing, offering improved MI estimation and scalability. This enables fine-grained, statistically robust mappings between neurons and linguistic properties, supporting future investigations in neurosymbolic interpretability, model debugging, and bias analysis. Practically, the cross-lingual transfer observed in top informative dimensions has direct implications for multilingual model design, zero-shot learning, and efficiency-oriented pruning or compression strategies. These results reinforce the deeply entangled nature of multilingual representations, highlighting a convergence between crosslinguistic typology and learned internal structure.
Future Directions
Open research avenues include extending the latent-variable intrinsic probing paradigm to non-neuron-level substructures (e.g., attention heads, layer groups), integrating richer Bayesian priors over subsets, or coupling with causal intervention frameworks for stronger claims on neuron necessity and redundancy. There is also scope for leveraging this approach in designing more controlled and attribute-specific model steering, as well as closed-loop model editing for debiasing or targeted attribute suppression.
Conclusion
The latent-variable model for intrinsic probing constitutes a substantial advance in both the theory and practice of neural representation interpretability. By unifying variational marginalization over neuron subsets with scalable, nonparametric mutual information estimation, this framework clarifies where and how linguistic properties are instantiated in deep contextual embeddings. It establishes a robust, generalizable, and scalable backbone for future neural model interpretability research and multi-lingual representation analysis.

